OracleSQL僷僘儖
柧抭廳憼偺僽儘僌
柧抭廳憼偺Twitter
婰帠(OTN)
婰帠(CodeZine)
暘愅娭悢偲model嬪
奣梫
Oracle OpenWorld 2009 Tokyo 偺"Unconference"偺丄4寧23擔(栘)偺15:00-15:30偺榞
偱巹偑丄僆乕僈僫僀僓(島巘)傪偝偣偰偄偨偩偒傑偟偰丄偦偺傑偲傔儁乕僕偱偡丅
OTN-Japan傗US-OTN偺僼僅乕儔儉偱偺SQL偺栤戣傪夝偔偺偵丄巊偆偙偲偺懡偄丄
暘愅娭悢偲model嬪偵偮偄偰丄巹偺巚峫朄傗丄擼撪偺僀儊乕僕傪夝愢偟傑偟偨丅
2007擭偵Laurent Schneider偝傫偑僗僺乕僇乕傪偝傟偨"SQL Model"傪堄幆偟偨撪梕偲丄
暘愅娭悢偺徴寕偺傑偲傔揑側撪梕傪埖偄傑偟偨丅扨弮側僒儞僾儖拞怱偺僙僢僔儑儞偵偟傑偟偨丅
僾儘僌儔儉
戞1晹 1. 暘愅娭悢偲偼
select嬪偲order by嬪偱巊偆偙偲偑偱偒傞丅(堦墳丄model嬪偱傕暘愅娭悢偼巊偊傑偡)
order by嬪偱巊偆偙偲偼丄傎偲傫偳側偄丅
Oracle9i偐傜(尩枾偵偼丄8.1.6 EnterpriseEdition)偐傜巊梡壜擻
傕偪傠傫丄Oracle10g,Oracle11g,OracleXE偱傕巊梡壜擻
SQLServer2005埲崀
DB2 Express
PostgreSQL8.4埲崀
側偳偱傕巊梡壜擻
暘愅娭悢偼昗弨SQL側偺偱丄偄偢傟偼丄懠偺DB偱傕巊偊傞傛偆偵側傞偼偢偱偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
暘愅娭悢偺儊儕僢僩
Oracle8i傑偱偼丄帺屓寢崌傗憡娭僒僽僋僄儕傪巊偭偨傝丄恊尵岅(Java傗VB6側偳)傗PL/SQL偱丄
媮傔偰偄偨寢壥傪丄SQL偱梕堈偵媮傔傞偙偲偑偱偒傞傛偆偵側傝傑偡丅
挔昜嶌惉傗僨乕僞暘愅偱摿偵巊偄傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
暘愅娭悢偺巊梡昿搙
嵟昿弌
count max min sum Row_Number
昿弌
Lag Lead Rank dense_rank
偨傑偵
avg Last_Value First_Value wmsys.wm_concat
儗傾
Ratio_To_Report median NTile regr_count
暘愅娭悢偺椺1 select暥偺審悢庢摼
select暥偺寢壥偺審悢偑梸偟偄偲偄偭偨偙偲偼丄寢峔偁傝傑偡丅偦傫側帪偵巊偆偺偑丄暘愅娭悢偺count娭悢偱偡丅
create table TestTable(ID,Val) as
select 1,10 from dual union
select 1,20 from dual union
select 2,10 from dual union
select 2,30 from dual union
select 2,50 from dual;
-- OLAPSample1
select ID,Val,
count(*) over() as recordCount
from TestTable;
-- OLAPSample1偺僒僽僋僄儕傪巊偭偨戙懼曽朄
select ID,Val,
(select count(*) from TestTable b) as recordCount
from TestTable a;
ID Val recordCount
-- --- -----------
1 10 5
1 20 5
2 10 5
2 30 5
2 50 5
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
 仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
-- OLAPSample2
select ID,Val,
count(*) over() as recordCount
from TestTable
where Val in(10,20);
ID Val recordCount
--- --- -----------
1 10 3
1 20 3
2 10 3
-- OLAPSample3
select ID,max(Val),
count(*) over() as recordCount
from TestTable
group by ID;
ID MAX(VAL) recordCount
-- -------- -----------
1 20 2
2 50 2
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
-- OLAPSample2
select ID,Val,
count(*) over() as recordCount
from TestTable
where Val in(10,20);
ID Val recordCount
--- --- -----------
1 10 3
1 20 3
2 10 3
-- OLAPSample3
select ID,max(Val),
count(*) over() as recordCount
from TestTable
group by ID;
ID MAX(VAL) recordCount
-- -------- -----------
1 20 2
2 50 2
暘愅娭悢偺椺2 嵟戝抣偺峴偺庢摼
幚偵傛偔尒偐偗傞丄掕斣栤戣偱偡丅ID偛偲偵丄Val偑嵟戝抣偺峴傪庢摼偟傑偡丅
create table TestTable2(ID,Val,extraCol) as
select 1,10,'A' from dual union all
select 1,20,'B' from dual union all
select 2,10,'C' from dual union all
select 2,30,'D' from dual union all
select 2,50,'E' from dual union all
select 3,70,'F' from dual union all
select 3,70,'G' from dual;
-- 扨弮偵丄ID偛偲偺Val偺嵟戝抣偑梸偟偄側傜丄偙傟偱壜
select ID,max(Val)
from TestTable2
group by ID;
-- OLAPSample4
select ID,Val,extraCol
from (select ID,Val,extraCol,
max(Val) over(partition by ID) as maxVal
from TestTable2)
where Val = maxVal;
-- OLAPSample4偺憡娭僒僽僋僄儕傪巊偭偨戙懼曽朄
select ID,Val,extraCol
from TestTable2 a
where Val = (select max(b.Val)
from TestTable2 b
where b.ID = a.ID);
ID Val extraCol
-- --- --------
1 20 B
2 50 E
3 70 F
3 70 G
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
暘愅娭悢偑巊偊傞偺偼丄select嬪偐order by嬪偱偡丅
側偺偱丄暘愅娭悢偺寢壥傪where嬪偱巊偆偵偼丄僀儞儔僀儞價儏乕傪巊偆昁梫偑偁傝傑偡丅
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅partition by 偼丄擼撪偱愒慄傪堷偔偲暘偐傝傗偡偄偱偡丅

暘愅娭悢偺椺3 弴埵傪晅偗傞
弴埵傗楢斣傪晅偗偨偄帪偵巊偆偺偑丄暘愅娭悢偺Row_Number娭悢,rank娭悢,dense_rank娭悢偱偡丅
create table TestTable3(ID,score) as
select 1,100 from dual union all
select 1,100 from dual union all
select 1, 90 from dual union all
select 1, 80 from dual union all
select 2,100 from dual union all
select 2, 70 from dual union all
select 2, 70 from dual;
-- OLAPSample5
select ID,score,
Row_Number() over(partition by ID order by score desc) as "Row_Number",
rank() over(partition by ID order by score desc) as "rank",
dense_rank() over(partition by ID order by score desc) as "dense_rank"
from TestTable3
order by ID,score desc;
ID score Row_Number rank dense_rank
-- ----- ---------- ---- ----------
1 100 1 1 1
1 100 2 1 1
1 90 3 3 2
1 80 4 4 3
2 100 1 1 1
2 70 2 2 2
2 70 3 2 2
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
Row_Number娭悢偼丄RowNum媅帡楍偲柤慜偑帡偰偄傞偙偲偐傜暘偐傞偲偍傝
1偐傜巒傑偭偰丄昁偢楢斣偵側傝傑偡丅
-- RowNum媅帡楍偺巊梡椺
select ID,score,RowNum
from (select ID,score from TestTable3
order by score desc)
order by score desc;
ID score ROWNUM
-- ----- ------
1 100 1
1 100 2
2 100 3
1 90 4
1 80 5
2 70 6
2 70 7
rank娭悢偼丄摨揰偑偁傞偲弴埵偑旘傃傑偡丅
dense_rank娭悢偼丄摨揰偑偁偭偰傕弴埵偑旘傃傑偣傫丅dense偼丄宍梕帉偱丄枾廤偟偨偲偄偆堄枴偱偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅

暘愅娭悢偺椺4 慜屻偺峴偺抣
巜掕偟偨僜乕僩僉乕偱偺丄慜屻偺峴偺抣偑梸偟偄帪偵巊傢傟傞偺偑丄Lag娭悢偲Lead娭悢偱偡丅
create table TestTable4(ID,sortKey,Val) as
select 'AA',1,10 from dual union all
select 'AA',3,20 from dual union all
select 'AA',5,60 from dual union all
select 'AA',7,30 from dual union all
select 'BB',2,40 from dual union all
select 'BB',4,80 from dual union all
select 'BB',6,50 from dual;
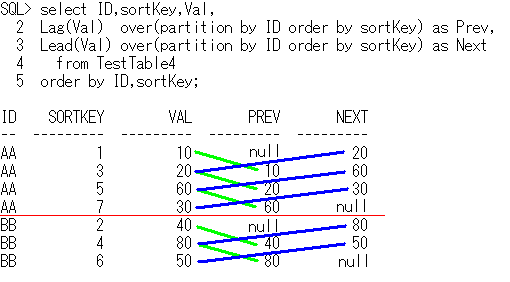
-- OLAPSample6
select ID,sortKey,Val,
Lag(Val) over(partition by ID order by sortKey) as Prev,
Lead(Val) over(partition by ID order by sortKey) as Next
from TestTable4
order by ID,sortKey;
ID sortKey Val Prev Next
-- ------- --- ---- ----
AA 1 10 null 20
AA 3 20 10 60
AA 5 60 20 30
AA 7 30 60 null
BB 2 40 null 80
BB 4 80 40 50
BB 6 50 80 null
-- OLAPSample6偺憡娭僒僽僋僄儕傪巊偭偨戙懼曽朄
埲崀丄妱垽偟傑偡丅嫽枴偑偁傞曽偼丄MySQL偱暘愅娭悢傪柾曧僔儕乕僘傪屼棗偵側偭偰壓偝偄丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
 仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
Lag娭悢偲Lead娭悢偼丄僉乕僽儗僀僋偺帠慜専抦偵傕巊偊傑偡丅
ID楍,sortKey楍傪僜乕僩僉乕丄
ID楍傪僽儗乕僋僉乕偲偟偰丄
僉乕僽儗僀僋傪専抦偟偰傒傑偡丅
(case幃傪巊偆偺偑掕斣偱偡偑丄偙傟偼丄case幃傪巊傢側偔偰偄偄僷僞乕儞偱偡)
-- case幃傪巊偆掕斣偺曽朄
select ID,sortKey,Val,
case when ID = Lag(ID) over(order by ID,SortKey) then 0 else 1 end as IsKeyBreaked,
case when ID = Lead(ID) over(order by ID,SortKey) then 0 else 1 end as willKeyBreak
from TestTable4
order by ID,sortKey;
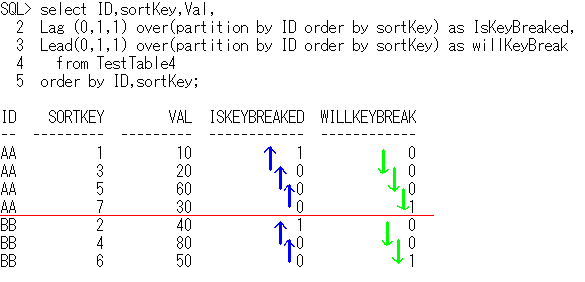
-- OLAPSample7
select ID,sortKey,Val,
Lag (0,1,1) over(partition by ID order by sortKey) as IsKeyBreaked,
Lead(0,1,1) over(partition by ID order by sortKey) as willKeyBreak
from TestTable4
order by ID,sortKey;
ID sortKey Val IsKeyBreaked willKeyBreak
-- ------- --- ------------ ------------
AA 1 10 1 0
AA 3 20 0 0
AA 5 60 0 0
AA 7 30 0 1
BB 2 40 1 0
BB 4 80 0 0
BB 6 50 0 1
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
Lag娭悢偲Lead娭悢偼丄僉乕僽儗僀僋偺帠慜専抦偵傕巊偊傑偡丅
ID楍,sortKey楍傪僜乕僩僉乕丄
ID楍傪僽儗乕僋僉乕偲偟偰丄
僉乕僽儗僀僋傪専抦偟偰傒傑偡丅
(case幃傪巊偆偺偑掕斣偱偡偑丄偙傟偼丄case幃傪巊傢側偔偰偄偄僷僞乕儞偱偡)
-- case幃傪巊偆掕斣偺曽朄
select ID,sortKey,Val,
case when ID = Lag(ID) over(order by ID,SortKey) then 0 else 1 end as IsKeyBreaked,
case when ID = Lead(ID) over(order by ID,SortKey) then 0 else 1 end as willKeyBreak
from TestTable4
order by ID,sortKey;
-- OLAPSample7
select ID,sortKey,Val,
Lag (0,1,1) over(partition by ID order by sortKey) as IsKeyBreaked,
Lead(0,1,1) over(partition by ID order by sortKey) as willKeyBreak
from TestTable4
order by ID,sortKey;
ID sortKey Val IsKeyBreaked willKeyBreak
-- ------- --- ------------ ------------
AA 1 10 1 0
AA 3 20 0 0
AA 5 60 0 0
AA 7 30 0 1
BB 2 40 1 0
BB 4 80 0 0
BB 6 50 0 1
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
 仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
僉乕僽儗僀僋偺帠慜専抦偼丄暘愅娭悢偺count娭悢傪巊偭偰傕偄偄偱偡偑丄
斲掕忦審偲側偭偰偟傑偭偨偨傔丄暘偐傝偵偔偄婥偑偟傑偡丅
-- OLAPSample8
select ID,sortKey,Val,
count(*) over(partition by ID order by sortKey
Rows between 1 preceding
and 1 preceding) as IsNotKeyBreaked,
count(*) over(partition by ID order by sortKey
Rows between 1 following
and 1 following) as willNotKeyBreak
from TestTable4
order by ID,sortKey;
ID sortKey Val IsNotKeyBreaked willNotKeyBreak
-- ------- --- --------------- ---------------
AA 1 10 0 1
AA 3 20 1 1
AA 5 60 1 1
AA 7 30 1 0
BB 2 40 0 1
BB 4 80 1 1
BB 6 50 1 0
windowing_clause(僂傿儞僪僂僀儞僌_僋儘僂僘)偼丄壓婰偺傛偆偵夝庍偡傞偲暘偐傝傗偡偄偲巚偄傑偡丅
order by sortKey -- sortKey偺徃弴偱丄
Rows between -- 峴偺斖埻偼丄
1 preceding -- 1峴慜偐傜
and 1 preceding -- 1峴慜傑偱
order by sortKey -- sortKey偺徃弴偱丄
Rows between -- 峴偺斖埻偼丄
1 following -- 1峴愭偐傜
and 1 following -- 1峴愭傑偱
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
僉乕僽儗僀僋偺帠慜専抦偼丄暘愅娭悢偺count娭悢傪巊偭偰傕偄偄偱偡偑丄
斲掕忦審偲側偭偰偟傑偭偨偨傔丄暘偐傝偵偔偄婥偑偟傑偡丅
-- OLAPSample8
select ID,sortKey,Val,
count(*) over(partition by ID order by sortKey
Rows between 1 preceding
and 1 preceding) as IsNotKeyBreaked,
count(*) over(partition by ID order by sortKey
Rows between 1 following
and 1 following) as willNotKeyBreak
from TestTable4
order by ID,sortKey;
ID sortKey Val IsNotKeyBreaked willNotKeyBreak
-- ------- --- --------------- ---------------
AA 1 10 0 1
AA 3 20 1 1
AA 5 60 1 1
AA 7 30 1 0
BB 2 40 0 1
BB 4 80 1 1
BB 6 50 1 0
windowing_clause(僂傿儞僪僂僀儞僌_僋儘僂僘)偼丄壓婰偺傛偆偵夝庍偡傞偲暘偐傝傗偡偄偲巚偄傑偡丅
order by sortKey -- sortKey偺徃弴偱丄
Rows between -- 峴偺斖埻偼丄
1 preceding -- 1峴慜偐傜
and 1 preceding -- 1峴慜傑偱
order by sortKey -- sortKey偺徃弴偱丄
Rows between -- 峴偺斖埻偼丄
1 following -- 1峴愭偐傜
and 1 following -- 1峴愭傑偱
暘愅娭悢偺椺5 椵寁
挔昜偱椵寁傪媮傔偨偄帪偵巊偆偺偑丄order by傪巜掕偟偨丄暘愅娭悢偺sum娭悢偱偡丅
create table ValTable(ID,sortKey,Val) as
select 'AA',1,10 from dual union all
select 'AA',2,20 from dual union all
select 'AA',3,40 from dual union all
select 'AA',4,80 from dual union all
select 'BB',1,10 from dual union all
select 'BB',2,30 from dual union all
select 'BB',3,90 from dual union all
select 'CC',1,50 from dual union all
select 'CC',2,60 from dual union all
select 'CC',2,60 from dual;
-- OLAPSample9
select ID,sortKey,Val,
sum(Val) over(partition by ID order by sortKey) as runSum
from ValTable
order by ID,sortKey;
ID sortKey Val runSum
-- ------- --- ------
AA 1 10 10
AA 2 20 30
AA 3 40 70
AA 4 80 150
BB 1 10 10
BB 2 30 40
BB 3 90 130
CC 1 50 50
CC 2 60 170
CC 2 60 170
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
order by傪巜掕偟偰丄windowing_clause傪徣棯偡傞偲丄僨僼僅儖僩偺丄
Range between unbounded preceding
and current row偵側傝傑偡丅
windowing_clause(僂傿儞僪僂僀儞僌_僋儘僂僘)偼丄壓婰偺傛偆偵夝庍偡傞偲暘偐傝傗偡偄偲巚偄傑偡丅
order by sortKey -- sortKey偺徃弴偱丄
Range between -- 抣偺斖埻偼丄
unbounded preceding -- 慜曽偼丄嵺尷側偔丄
and current row -- 屻曽偼丄僇儗儞僩峴傑偱
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅

暘愅娭悢偺椺6 堏摦椵寁
OracleSQL僷僘儖偺傾僋僙僗夝愅偱丄堏摦暯嬒偱専嶕偟偰偔傞曽偼丄寢峔懡偄偱偡丅4擔堏摦椵寁傪媮傔偰傒傑偟傚偆丅
create table idouT(day1,Val) as
select date '2009-04-16', 10 from dual union all
select date '2009-04-17', 20 from dual union all
select date '2009-04-20', 40 from dual union all
select date '2009-04-21', 80 from dual union all
select date '2009-04-22',160 from dual union all
select date '2009-04-23',320 from dual union all
select date '2009-04-24',640 from dual;
col BaseOfMoveSum1 for a18
col BaseOfMoveSum2 for a18
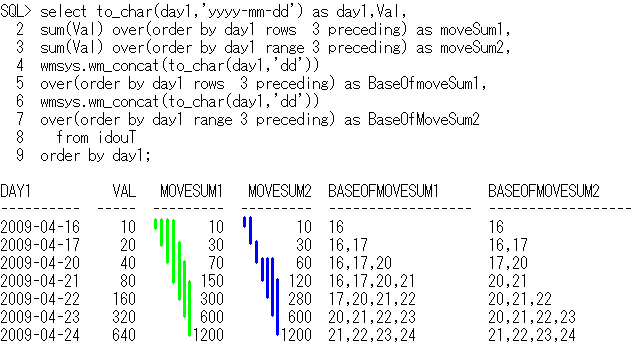
-- OLAPSample10
select to_char(day1,'yyyy-mm-dd') as day1,Val,
sum(Val) over(order by day1 rows 3 preceding) as moveSum1,
sum(Val) over(order by day1 range 3 preceding) as moveSum2,
wmsys.wm_concat(to_char(day1,'dd'))
over(order by day1 rows 3 preceding) as BaseOfMoveSum1,
wmsys.wm_concat(to_char(day1,'dd'))
over(order by day1 range 3 preceding) as BaseOfMoveSum2
from idouT
order by day1;
day1 Val moveSum1 moveSum2 BaseOfMoveSum1 BaseOfMoveSum2
---------- --- -------- -------- -------------- --------------
2009-04-16 10 10 10 16 16
2009-04-17 20 30 30 16,17 16,17
2009-04-20 40 70 60 16,17,20 17,20
2009-04-21 80 150 120 16,17,20,21 20,21
2009-04-22 160 300 280 17,20,21,22 20,21,22
2009-04-23 320 600 600 20,21,22,23 20,21,22,23
2009-04-24 640 1200 1200 21,22,23,24 21,22,23,24
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
暘愅娭悢偺wmsys.wm_concat偼丄Oracle11g偺儅僯儏傾儖偵偡傜嵹偭偰側偄偺偱偡偑丄
奐敪帪偺僨僶僢僌傗僥僗僩側偳偱巊偄摴偼偁傝傑偡丅
windowing_clause(僂傿儞僪僂僀儞僌_僋儘僂僘)偺徣棯帪偺巇條偲偟偰丄
order by day1 rows 3 preceding偼丄
order by day1 rows between 3 preceding
and current row
偲摨偠埖偄偲側傝傑偡丅
摨條偵丄
order by day1 range 3 preceding偼丄
order by day1 range between 3 preceding
and current row
偲摨偠埖偄偲側傝傑偡丅
rows巜掕偲range巜掕偺堘偄偼丄
rows偼丄僜乕僩僉乕偱暲傋偨帪偺丄慜傕偟偔偼屻傠偺峴悢(Rows)偺巜掕偱偁傝丄
range偼丄僜乕僩僉乕偑丄偳傟偩偗慜傕偟偔偼屻傠偐偺巜掕偱偁傞偙偲偱偡丅
偦傟偧傟丄壓婰偺傛偆偵夝庍偡傞偲暘偐傝傗偡偄偲巚偄傑偡丅
order by day1 -- day1偺徃弴偱丄
rows between -- 峴偺斖埻偼丄
3 preceding -- 3峴慜偐傜
and current row -- 僇儗儞僩峴傑偱
order by day1 -- day1偺徃弴偱丄
range between -- 抣偺斖埻偼丄
3 preceding -- 3擔慜偐傜
and current row -- 僇儗儞僩峴傑偱
側偍丄day1偼date宆偱偡偺偱丄
sum(Val) over(order by day1 range 3 preceding) as moveSum2
偼丄壓婰偺傛偆偵
sum(Val) over(order by day1 range interval '3' day preceding) as moveSum2
偲傕婰弎偱偒傑偡丅
-- OLAPSample11
select to_char(day1,'yyyy-mm-dd') as day1,Val,
sum(Val) over(order by day1 range interval '3' day preceding) as moveSum2
from idouT
order by day1;
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
暘愅娭悢偺椺7 楢懕斖埻偺嵟彫抣偲嵟戝抣
US-OTN偱傛偔尒偐偗傞栤戣偱偁傞丄楢懕斖埻偺嵟彫抣偲嵟戝抣傪媮傔傞SQL偱偡丅
暘愅娭悢偺墳梡椺偲偟偰桳柤側傕偺偩偲巚偄傑偡丅
create table seqTable(ID,seq) as
select 'AA',1 from dual union all
select 'AA',2 from dual union all
select 'AA',3 from dual union all
select 'AA',6 from dual union all
select 'AA',7 from dual union all
select 'BB',1 from dual union all
select 'BB',3 from dual union all
select 'BB',4 from dual union all
select 'BB',6 from dual union all
select 'BB',7 from dual union all
select 'CC',1 from dual union all
select 'CC',5 from dual union all
select 'DD',1 from dual union all
select 'DD',5 from dual;
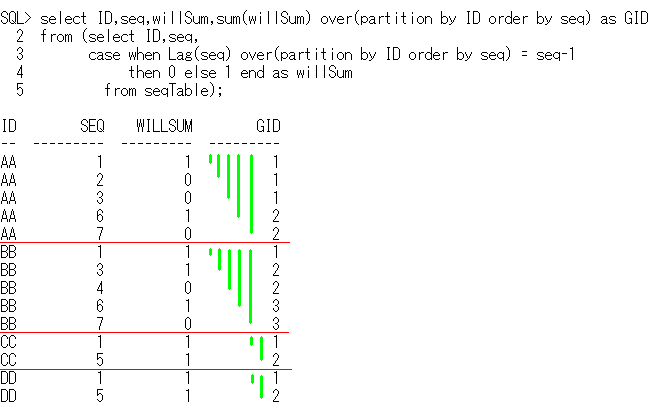
-- OLAPSample12 Lag娭悢偱僔乕働儞僗奐巒傪専抦
select ID,min(seq) as minSeq,max(seq) as maxSeq
from (select ID,seq,sum(willSum) over(partition by ID order by seq) as GID
from (select ID,seq,
case when Lag(seq) over(partition by ID order by seq) = seq-1
then 0 else 1 end as willSum
from seqTable))
group by ID,GID
order by ID,GID;
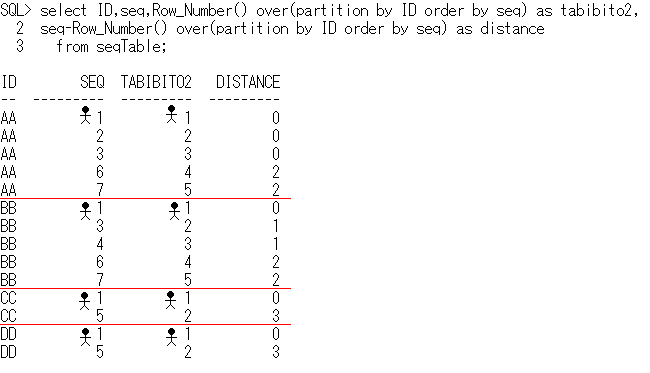
-- OLAPSample13 椃恖嶼偺姶妎傪巊偆
select ID,min(seq) as minSeq,max(seq) as maxSeq
from (select ID,seq,
seq-Row_Number() over(partition by ID order by seq) as distance
from seqTable)
group by ID,distance
order by ID,distance;
ID minSeq maxSeq
-- ------ ------
AA 1 3
AA 6 7
BB 1 1
BB 3 4
BB 6 7
CC 1 1
CC 5 5
DD 1 1
DD 5 5
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
SQL偺儘僕僢僋偺夝愢偼丄妱垽偟傑偡丅嫽枴偑偁傞曽偼丄壓婰傪屼棗偵側偭偰壓偝偄丅
暘愅娭悢偺徴寕3 (屻曇) (Lag娭悢偱僔乕働儞僗奐巒傪専抦)
暘愅娭悢偺徴寕5 (憤廤曇) (椃恖嶼偺姶妎傪巊偆)
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
Lag娭悢偱僔乕働儞僗奐巒傪専抦偡傞擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
 仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
椃恖嶼偺姶妎傪巊偆擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
椃恖嶼偺姶妎傪巊偆擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
暘愅娭悢偺椺8 慡徧峬掕,慡徧斲掕,懚嵼峬掕,懚嵼斲掕
偙傟傕US-OTN偱傛偔尒偐偗傞栤戣偱偡丅
丒慡偰偺峴偑忦審傪枮偨偡偐丠
丒慡偰偺峴偑忦審傪枮偨偝側偄偐丠
丒彮側偔偲傕1峴偑忦審傪枮偨偡偐丠
丒彮側偔偲傕1峴偑忦審傪枮偨偝側偄偐丠
偲偄偭偨暋悢峴偵傑偨偑偭偨僠僃僢僋傪偟偨偄帪偵巊偄傑偡丅
create table TestTable8(ID,Val not null) as
select 'AA',10 from dual union all
select 'AA',20 from dual union all
select 'BB',10 from dual union all
select 'BB',30 from dual union all
select 'BB',50 from dual union all
select 'CC',80 from dual union all
select 'CC',90 from dual union all
select 'DD',20 from dual union all
select 'DD',70 from dual;
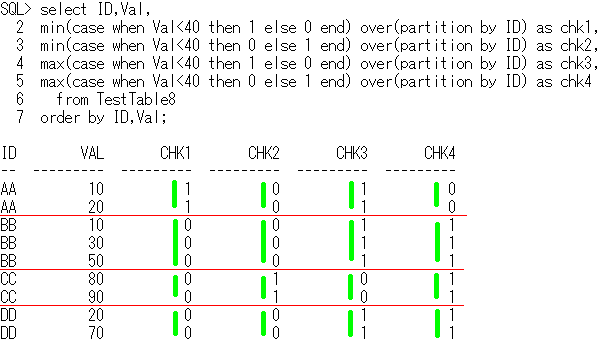
丒check1 ID偛偲偱丄慡偰偺峴偑 Val<40 傪枮偨偡偐丠
丒check2 ID偛偲偱丄慡偰偺峴偑 Val<40 傪枮偨偝側偄偐丠
丒check3 ID偛偲偱丄彮側偔偲傕1偮偺峴偑 Val<40 傪枮偨偡偐丠
丒check4 ID偛偲偱丄彮側偔偲傕1偮偺峴偑 Val<40 傪枮偨偝側偄偐丠
傪僠僃僢僋偟偰傒傑偟傚偆丅
select ID,Val,
min(case when Val<40 then 1 else 0 end) over(partition by ID) as chk1,
min(case when Val<40 then 0 else 1 end) over(partition by ID) as chk2,
max(case when Val<40 then 1 else 0 end) over(partition by ID) as chk3,
max(case when Val<40 then 0 else 1 end) over(partition by ID) as chk4
from TestTable8
order by ID,Val;
ID Val chk1 chk2 chk3 chk4
-- --- ---- ---- ---- ----
AA 10 1 0 1 0
AA 20 1 0 1 0
BB 10 0 0 1 1
BB 30 0 0 1 1
BB 50 0 0 1 1
CC 80 0 1 0 1
CC 90 0 1 0 1
DD 20 0 0 1 1
DD 70 0 0 1 1
SQL偺儘僕僢僋偺夝愢偼丄妱垽偟傑偡丅嫽枴偑偁傞曽偼丄暘愅娭悢偺徴寕4 (姰寢曇)傪屼棗偵側偭偰壓偝偄丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
 仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
慡徧峬掕,慡徧斲掕,懚嵼峬掕,懚嵼斲掕偺
SQL傊偺曄姺岞幃偼壓婰偲側傝傑偡丅
慡徧 仺 min
懚嵼 仺 max
峬掕 仺 (case when 忦審 then 1 else 0 end)
斲掕 仺 (case when 忦審 then 0 else 1 end)
傑偲傔傞偲
慡徧峬掕柦戣側傜 min(case when 忦審 then 1 else 0 end) = 1
慡徧斲掕柦戣側傜 min(case when 忦審 then 0 else 1 end) = 1
懚嵼峬掕柦戣側傜 max(case when 忦審 then 1 else 0 end) = 1
懚嵼斲掕柦戣側傜 max(case when 忦審 then 0 else 1 end) = 1
恀側傜1丄婾側傜0偵偟偰偍偔偙偲偵傛傝丄僽乕儖抣偲偟偰傕巊偊傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
慡徧峬掕,慡徧斲掕,懚嵼峬掕,懚嵼斲掕偺
SQL傊偺曄姺岞幃偼壓婰偲側傝傑偡丅
慡徧 仺 min
懚嵼 仺 max
峬掕 仺 (case when 忦審 then 1 else 0 end)
斲掕 仺 (case when 忦審 then 0 else 1 end)
傑偲傔傞偲
慡徧峬掕柦戣側傜 min(case when 忦審 then 1 else 0 end) = 1
慡徧斲掕柦戣側傜 min(case when 忦審 then 0 else 1 end) = 1
懚嵼峬掕柦戣側傜 max(case when 忦審 then 1 else 0 end) = 1
懚嵼斲掕柦戣側傜 max(case when 忦審 then 0 else 1 end) = 1
恀側傜1丄婾側傜0偵偟偰偍偔偙偲偵傛傝丄僽乕儖抣偲偟偰傕巊偊傑偡丅
暘愅娭悢偺嶲峫儕僜乕僗
戞2晹 1. model嬪偲偼
Excel傗PL/SQL偺寢崌攝楍偺傛偆偵丄SQL偺寢壥僙僢僩傪埖偆偙偲偑偱偒傞丅
having嬪偺師偵丄model嬪偑昡壙偝傟傞傛偆偱偡丅
Oracle10g偐傜巊梡壜擻(Oracle10g,Oracle11g,OracleXE)
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
model嬪偺儊儕僢僩
Oracle9i傑偱偼丄暘愅娭悢傪壗搙傕巊偭偨傝丄Union all傪巊偭偨傝丄恊尵岅(Java傗VB6側偳)傗PL/SQL偱丄
媮傔偰偄偨寢壥傪丄SQL偱梕堈偵媮傔傞偙偲偑偱偒傞傛偆偵側傝傑偡丅
model嬪偺巊梡椺偱戙昞揑側偺偼丄
丒廤寁峴偺捛壛
丒count(distinct Val) over(order by SortKey)偺戙梡
丒wmsys.wm_concat偺戙梡
丒group_concat傕偳偒
偺傛偆側SQL傪嶌惉偡傞帪偱偡丅
HelloWorld側偳偺娙扨側僒儞僾儖
傑偢偼丄娙扨側僒儞僾儖傪尒偰傒傑偟傚偆丅
-- modelSample1
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,1 as soeji from dual)
model
dimension by (soeji)
measures(ArrValue)
rules(ArrValue[1] = 'Hello World');
ArrValue soeji
----------- -----
Hello World 1
偦傟偧傟偺暥朄偵偮偄偰愢柧偟傑偟傚偆丅
-------------------------------------------------------------------------------------
丒model
model嬪傪巊梡偡傞嵺偺僉乕儚乕僪偱偡丅
model嬪傪巊梡偡傞偵偼昁恵偱偡丅
-------------------------------------------------------------------------------------
丒dimension by
dimension偼丄師尦偲偄偆堄枴偱偡丅
憃巕嵗(僕僃儈僯)偺僒僈偺昁嶦媄偺傾僫僓乕僨傿儊儞僔儑儞偼丄暿偺師尦偵憲傝旘偽偡媄偱偡 ;-)
PL/SQL傗Java傗Ruby傗Perl側偳偵偍偗傞丄攝楍偺揧帤偩偲棟夝偟偰偍偄偰栤戣側偄偱偟傚偆丅
Fortran偱偼dimension僉乕儚乕僪傪巊偭偰攝楍傪掕媊偡傞傛偆偱偡丅
model嬪傪巊梡偡傞偵偼昁恵偱偡丅
-------------------------------------------------------------------------------------
丒measures
攝楍偑丄偳傫側抣偺攝楍偐傪巜掕偟傑偡丅
model嬪傪巊梡偡傞偵偼昁恵偱偡丅
-------------------------------------------------------------------------------------
丒rules
攝楍偺抣傪憖嶌偡傞幃傪婰弎偟傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
偦傟偱偼丄SQL傪夝愢偟傑偟傚偆丅
-- modelSample1
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,1 as soeji from dual)
model
dimension by (soeji)
measures(ArrValue)
rules(ArrValue[1] = 'Hello World');
ArrValue soeji
----------- -----
Hello World 1
傑偢丄僀儞儔僀儞價儏乕偺幚峴寢壥傪尒偰傒傑偟傚偆丅
select 'abcdefghijklmn' as ArrValue,1 as soeji from dual;
ArrValue soeji
-------------- -----
abcdefghijklmn 1
師偵丄
model
dimension by (soeji)
measures(ArrValue)
偵傛偭偰丄
soeji傪揧帤偲偟偰丄ArrValue傪攝楍抣偲偟偨丄攝楍偑嶌惉偝傟傞僀儊乕僕偱偡丅
偦偟偰丄
rules(ArrValue[1] = 'Hello World')
偵傛偭偰丄ArrValue[1]偺抣偑丄Hello World偵忋彂偒偝傟傞僀儊乕僕偱偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
僒儞僾儖2傕尒偰傒傑偟傚偆丅
-- modelSample2
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,1 as soeji from dual)
model
dimension by (soeji)
measures(ArrValue)
rules(ArrValue[1] = 'Hello World',
ArrValue[2] = 'Hello Model');
ArrValue soeji
----------- -----
Hello World 1
Hello Model 2
rules偼丄僨僼僅儖僩偱upsert(偁傟偽update,側偗傟偽insert)偱偡丅
側偺偱丄
ArrValue[1] = 'Hello World' 偵傛偭偰丄ArrValue[1]偑update偝傟丄
ArrValue[2] = 'Hello Model' 偵傛偭偰丄ArrValue[2]偑insert偝傟傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
僒儞僾儖3傕尒偰傒傑偟傚偆丅
-- modelSample3
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,1 as soeji from dual)
model
dimension by (soeji)
measures(ArrValue)
rules(ArrValue[3] = 'Hello Oracle');
ArrValue soeji
-------------- -----
abcdefghijklmn 1
Hello Oracle 3
攝楍偺揧帤偼丄楢懕偟偰側偔偰傕栤戣側偄偺偱偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
 仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
僒儞僾儖4傕尒偰傒傑偟傚偆丅
-- modelSample4
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,1 as soeji from dual)
model return updated rows
dimension by (soeji)
measures(ArrValue)
rules(ArrValue[4] = 'Hello OOW2009');
ArrValue soeji
------------- -----
Hello OOW2009 4
model return updated rows偲偡傞偲丄
rules嬪偵傛偭偰丄峏怴(update偐insert)偝傟偨峴偺傒弌椡偡傞偙偲偑偱偒傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
僒儞僾儖4傕尒偰傒傑偟傚偆丅
-- modelSample4
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,1 as soeji from dual)
model return updated rows
dimension by (soeji)
measures(ArrValue)
rules(ArrValue[4] = 'Hello OOW2009');
ArrValue soeji
------------- -----
Hello OOW2009 4
model return updated rows偲偡傞偲丄
rules嬪偵傛偭偰丄峏怴(update偐insert)偝傟偨峴偺傒弌椡偡傞偙偲偑偱偒傑偡丅
model嬪偺椺1 廤寁峴偺捛壛
model嬪偺戙昞揑側巊偄摴偺1偮偱偡丅
Oracle9i傑偱偼丄峴偺捛壛偼丄
union all,rollup,grouping sets,楢斣昞偲偺僋儘僗僕儑僀儞,昞娭悢側偳傪巊偭偰峴傢傟偰傑偟偨偑丄
Oracle10g偐傜偼丄model嬪偱峴偺捛壛偑峴偊傑偡丅
create table modelTest1(ID,Val) as
select 1,10 from dual union all
select 2,20 from dual union all
select 3,40 from dual union all
select 4,80 from dual;
廤寁峴傕昞帵偟偰傒傑偟傚偆丅
-- modelSample5
select ID,Val
from modelTest1
model
dimension by(ID)
measures(Val)
rules(
Val[null] = Val[1]+Val[2]+Val[3]+Val[4]);
ID Val
---- ---
1 10
2 20
3 40
4 80
null 150
-- modelSample5偺戙懼曽朄
select ID,sum(Val) as Val
from modelTest1
group by rollup(ID);
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
ID偑3傑偨偼4偺傒傪廤寁懳徾偲偟偰丄廤寁峴傪昞帵偟偰傒傑偟傚偆丅
-- modelSample6
select ID,Val
from modelTest1
model
dimension by(ID)
measures(Val)
rules(
Val[null] = Val[3]+Val[4]);
ID Val
---- ---
1 10
2 20
3 40
4 80
null 120
-- modelSample6偺戙懼曽朄
select ID,
case grouping(ID) when 0 then sum(Val)
else sum(case when ID in(3,4) then Val end)
end as Val
from modelTest1
group by rollup(ID);
椺偐傜暘偐傞偲偍傝丄model嬪偵傛傞峴偺捛壛偼丄懠偺曽朄偲斾傋偰僔儞僾儖偵側傞偙偲偑懡偄偱偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅

model嬪偺椺2 pivot傪偁偊偰model嬪偱
Pivot傪偁偊偰丄model嬪傪巊偭偰傗偭偰傒傑偟傚偆丅
create table modelPivot(ID,seq,Val) as
select 10,'01','AAAAA' from dual union all
select 10,'02','BBBBB' from dual union all
select 10,'03','CCCCC' from dual union all
select 20,'01','DDDDD' from dual union all
select 20,'02','EEEEE' from dual union all
select 30,'02','FFFFF' from dual union all
select 30,'03','GGGGG' from dual;
-- 堦斒揑側曽朄
select ID,
max(decode(seq,'01',Val)) as Val01,
max(decode(seq,'02',Val)) as Val02,
max(decode(seq,'03',Val)) as Val03
from modelPivot
group by ID
order by ID;
ID Val01 Val02 Val03
-- ----- ----- -----
10 AAAAA BBBBB CCCCC
20 DDDDD EEEEE null
30 null FFFFF GGGGG
-- modelSample7
select ID,Val01,Val02,Val03
from modelPivot
model return updated rows
partition by (ID)
dimension by (seq)
measures(Val as Val01,Val as Val02,Val as Val03)
rules(Val02['01'] = Val02['02'],
Val03['01'] = Val03['03'])
order by ID;
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
partition by (ID)
偲偄偆偺偼丄rules嬪偑峴偆張棟傪僷乕僥傿僔儑儞偛偲偵暘妱偡傞
偲偄偆堄枴偲側傝傑偡丅
dimension by (seq)
偱seq傪揧帤偲偟丄
Val傪偦傟偧傟丄Val01,Val02,Val03偲偟偰暋惢偟丄
屻偼丄rules嬪偱丄揧帤偑01偺峴偵丄昁梫側抣傪廤傔偰傑偡丅
model return updated rows傪巜掕偟偰傑偡偺偱丄峏怴偝傟偨峴偺傒弌椡偝傟傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅partition by 偼丄擼撪偱愒慄傪堷偔偲暘偐傝傗偡偄偱偡丅

model嬪偺椺3 all_objects傗all_catalog傗dict偺戙梡
1埲忋偺惍悢偺楢斣偑梸偟偄偙偲偼丄偨傑偵偁傝傑偡丅
model嬪偺婡擻傪巊偭偰丄楢斣傪庢摼偟偰傒傑偡丅
-- modelSample8
select soeji,dummy
from dual
model
dimension by (1 as soeji)
measures(0 as dummy)
rules iterate (5)
(dummy[iteration_number+1] = 0);
soeji dummy
----- -----
1 0
2 0
3 0
4 0
5 0
rules iterate (5)
偲婰弎偡傞偲丄rules偑5夞昡壙偝傟傑偡丅
偦偟偰丄rule偑1夞昡壙偝傟傞偛偲偵丄僀儞僋儕儊儞僩偝傟傞抣偲偟偰丄iteration_number偑偁傝傑偡丅
iteration_number偼丄0偐傜奐巒偝傟傑偡丅
偪側傒偵丄僾儘僌儔儉尵岅偺for暥偺儖乕僾曄悢偱傛偔巊傢傟傞i偼丄iteration偺摢暥帤偑桼棃偩偦偆偱偡丅
for (int i=0;i<=10;i++) //Java偺for儖乕僾
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
rules iterate 傪巊傢偢偵丄for僐儞僗僩儔僋僩偱戙梡偡傞偙偲傕偱偒傑偡丅
select soeji,dummy
from dual
model
dimension by (1 as soeji)
measures(0 as dummy)
rules(
dummy[for soeji from 1 to 5 increment 1]= 0);
soeji dummy
----- -----
1 0
2 0
3 0
4 0
5 0
model嬪偺椺4 Partitioned Outer Join傕偳偒
Oracle10g偐傜丄Partitioned Outer Join偲偄偆怴婡擻偑捛壛偝傟傑偟偨丅
僷乕僥傿僔儑儞壔偝傟偨奜晹寢崌偲傕屇偽傟傑偡丅
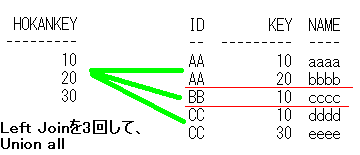
create table LPOTable(ID,Key,Name) as
select 'AA',10,'aaaa' from dual union all
select 'AA',20,'bbbb' from dual union all
select 'BB',10,'cccc' from dual union all
select 'CC',10,'dddd' from dual union all
select 'CC',30,'eeee' from dual;
-- Partitioned Outer Join
select b.ID,a.hokanKey,b.Name
from (select 10 as hokanKey from dual union all
select 20 from dual union all
select 30 from dual) a
Left Outer Join LPOTable b
partition by (b.ID)
on (a.hokanKey = b.Key)
order by b.ID,a.hokanKey;
ID hokanKey Name
-- -------- ----
AA 10 aaaa
AA 20 bbbb
AA 30 null
BB 10 cccc
BB 20 null
BB 30 null
CC 10 dddd
CC 20 null
CC 30 eeee
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
Partitioned Outer Join傪巊偆偲丄
僷乕僥傿僔儑儞傪愗偭偰偱偒偨丄偦傟偧傟偺廤崌偲奜晹寢崌偝偣傞偙偲偑偱偒傑偡丅
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅partition by 偼丄擼撪偱愒慄傪堷偔偲暘偐傝傗偡偄偱偡丅
 仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
偦傟偱偼丄model嬪傪巊偭偰丄摨偠寢壥傪庢摼偟偰傒傑偟傚偆丅
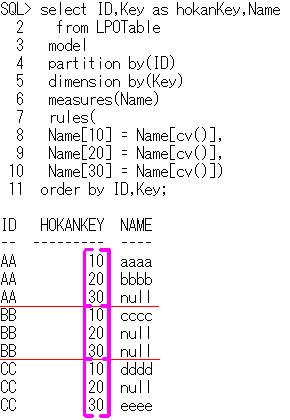
-- modelSample9
select ID,Key as hokanKey,Name
from LPOTable
model
partition by(ID)
dimension by(Key)
measures(Name)
rules(
Name[10] = Name[cv()],
Name[20] = Name[cv()],
Name[30] = Name[cv()])
order by ID,Key;
cv娭悢偼丄dimension by偱巜掕偟偨揧帤傪堷悢偵庢偭偰丄rules嬪偺嵍曈偱巜掕偟偨揧帤傪曉偟傑偡丅
妏妵屖偺拞偱偁傟偽丄cv娭悢偺堷悢偼徣棯壜擻偵側傝傑偡丅
椺偊偽丄Name[10] = Name[cv()]
偼丄 Name[10] = Name[cv(Key)] 偲摨偠堄枴偱偡丅
partition by(ID)
dimension by(Key)
rules(
Name[10] = Name[cv()],
Name[20] = Name[cv()],
Name[30] = Name[cv()])
偵傛偭偰丄ID偛偲偱丄
Key偑10偺抣偑偁傟偽丄Name偺抣傪忋彂偒偱戙擖丄側偗傟偽丄Name偺抣傪null偵愝掕
Key偑20偺抣偑偁傟偽丄Name偺抣傪忋彂偒偱戙擖丄側偗傟偽丄Name偺抣傪null偵愝掕
Key偑30偺抣偑偁傟偽丄Name偺抣傪忋彂偒偱戙擖丄側偗傟偽丄Name偺抣傪null偵愝掕
偲偄偭偨張棟偑峴傢傟傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
偦傟偱偼丄model嬪傪巊偭偰丄摨偠寢壥傪庢摼偟偰傒傑偟傚偆丅
-- modelSample9
select ID,Key as hokanKey,Name
from LPOTable
model
partition by(ID)
dimension by(Key)
measures(Name)
rules(
Name[10] = Name[cv()],
Name[20] = Name[cv()],
Name[30] = Name[cv()])
order by ID,Key;
cv娭悢偼丄dimension by偱巜掕偟偨揧帤傪堷悢偵庢偭偰丄rules嬪偺嵍曈偱巜掕偟偨揧帤傪曉偟傑偡丅
妏妵屖偺拞偱偁傟偽丄cv娭悢偺堷悢偼徣棯壜擻偵側傝傑偡丅
椺偊偽丄Name[10] = Name[cv()]
偼丄 Name[10] = Name[cv(Key)] 偲摨偠堄枴偱偡丅
partition by(ID)
dimension by(Key)
rules(
Name[10] = Name[cv()],
Name[20] = Name[cv()],
Name[30] = Name[cv()])
偵傛偭偰丄ID偛偲偱丄
Key偑10偺抣偑偁傟偽丄Name偺抣傪忋彂偒偱戙擖丄側偗傟偽丄Name偺抣傪null偵愝掕
Key偑20偺抣偑偁傟偽丄Name偺抣傪忋彂偒偱戙擖丄側偗傟偽丄Name偺抣傪null偵愝掕
Key偑30偺抣偑偁傟偽丄Name偺抣傪忋彂偒偱戙擖丄側偗傟偽丄Name偺抣傪null偵愝掕
偲偄偭偨張棟偑峴傢傟傑偡丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
 仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
rules嬪偺嵍曈偱偺丄揧帤偺巜掕曽朄偵偼丄壓婰偺傛偆側巜掕曽朄傕偁傝傑偡丅
-- modelSample10
select ID,Key as hokanKey,N1,N2,N3
from LPOTable
model
partition by(ID)
dimension by(Key)
measures(Name as N1,Name as N2,Name as N3)
rules(
N1[for Key in(10,20,30)] = N1[cv()],
N2[for Key from 10 to 30 increment 10] = N2[cv()],
N3[for Key in(select * from table(sys.odciNumberList(10,20,30)))] = N3[cv()])
order by ID,Key;
ID hokanKey N1 N2 N3
-- -------- ---- ---- ----
AA 10 aaaa aaaa aaaa
AA 20 bbbb bbbb bbbb
AA 30 null null null
BB 10 cccc cccc cccc
BB 20 null null null
BB 30 null null null
CC 10 dddd dddd dddd
CC 20 null null null
CC 30 eeee eeee eeee
N1[for Key in(10,20,30)] 偼丄抣傪楍嫇偟偰傑偡丅
N2[for Key from 10 to 30 increment 10] 偼丄for僐儞僗僩儔僋僩偱弶婜抣偲廔椆抣偲憹暘傪巜掕偟偰傑偡丅
N3[for Key in(select * from table(sys.odciNumberList(10,20,30)))] 偼丄select暥偺寢壥傪巊梡偟偰傑偡丅
壓婰偺傛偆偵丄懡師尦攝楍偱傕select暥偺寢壥傪巊梡偱偒傑偡丅
-- modelSample11
select *
from dual
model
dimension by(0 as key1,0 as key2)
measures(0 as dummy)
rules(
dummy[for (key1,key2) in(select 10,50 from dual)] = 0);
key1 key2 dummy
---- ---- -----
0 0 0
10 50 0
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
rules嬪偺嵍曈偱偺丄揧帤偺巜掕曽朄偵偼丄壓婰偺傛偆側巜掕曽朄傕偁傝傑偡丅
-- modelSample10
select ID,Key as hokanKey,N1,N2,N3
from LPOTable
model
partition by(ID)
dimension by(Key)
measures(Name as N1,Name as N2,Name as N3)
rules(
N1[for Key in(10,20,30)] = N1[cv()],
N2[for Key from 10 to 30 increment 10] = N2[cv()],
N3[for Key in(select * from table(sys.odciNumberList(10,20,30)))] = N3[cv()])
order by ID,Key;
ID hokanKey N1 N2 N3
-- -------- ---- ---- ----
AA 10 aaaa aaaa aaaa
AA 20 bbbb bbbb bbbb
AA 30 null null null
BB 10 cccc cccc cccc
BB 20 null null null
BB 30 null null null
CC 10 dddd dddd dddd
CC 20 null null null
CC 30 eeee eeee eeee
N1[for Key in(10,20,30)] 偼丄抣傪楍嫇偟偰傑偡丅
N2[for Key from 10 to 30 increment 10] 偼丄for僐儞僗僩儔僋僩偱弶婜抣偲廔椆抣偲憹暘傪巜掕偟偰傑偡丅
N3[for Key in(select * from table(sys.odciNumberList(10,20,30)))] 偼丄select暥偺寢壥傪巊梡偟偰傑偡丅
壓婰偺傛偆偵丄懡師尦攝楍偱傕select暥偺寢壥傪巊梡偱偒傑偡丅
-- modelSample11
select *
from dual
model
dimension by(0 as key1,0 as key2)
measures(0 as dummy)
rules(
dummy[for (key1,key2) in(select 10,50 from dual)] = 0);
key1 key2 dummy
---- ---- -----
0 0 0
10 50 0
model嬪偺椺5 count(distinct Val) over(order by SortKey)偺戙梡
US-OTN偱寢峔尒偐偗傞栤戣偱偡丅朘栤幰偑丄儕僺乕僞乕偐怴婯偐傪尒暘偗傞帪偵巊偆SQL偺傛偆偱偡丅
create table VisiterT(SortKey,Visit) as
select 10,'AAAA' from dual union all
select 20,'BBBB' from dual union all
select 30,'AAAA' from dual union all
select 40,'BBBB' from dual union all
select 50,'CCCC' from dual union all
select 60,'CCCC' from dual union all
select 70,'DDDD' from dual union all
select 80,'AAAA' from dual;
SQL> select SortKey,Visit,
2 count(distinct Visit) over(order by SortKey) as disVisit
3 from VisiterT
4 order by SortKey;
count(distinct Visit) over(order by SortKey) as disVisit
*
峴2偱僄儔乕偑敪惗偟傑偟偨丅: ORA-30487: 偙偙偱ORDER BY偼巊梡偱偒傑偣傫丅
暘愅娭悢偱distinct僆僾僔儑儞傪巊梡偟偰丄order by傪巜掕偡傞偲ORA-30487僄儔乕偵側傝傑偡丅
偳偆偵偐偟偰摨偠寢壥傪庢摼偟偰傒傑偟傚偆丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
-- modelSample12偺暘愅娭悢傪巊偭偨戙懼曽朄
select SortKey,Visit,sum(willSum) over(order by SortKey) as disVisit
from (select SortKey,Visit,
case Row_Number() over(partition by Visit order by SortKey)
when 1 then 1 else 0 end as willSum
from VisiterT)
order by SortKey;
-- modelSample12偺憡娭僒僽僋僄儕傪巊偭偨戙懼曽朄
select SortKey,Visit,
(select count(distinct b.Visit)
from VisiterT b
where b.SortKey <= a.SortKey) as disVisit
from VisiterT a
order by SortKey;
-- modelSample12
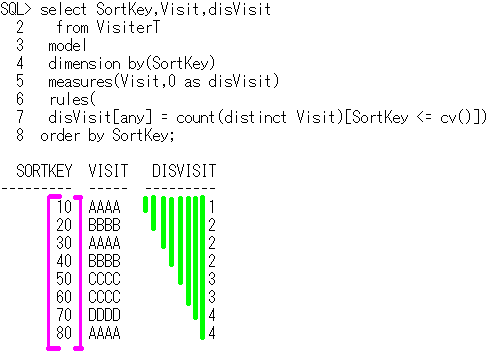
select SortKey,Visit,disVisit
from VisiterT
model
dimension by(SortKey)
measures(Visit,0 as disVisit)
rules(
disVisit[any] = count(distinct Visit)[SortKey <= cv()])
order by SortKey;
SortKey Visit disVisit
------- ----- --------
10 AAAA 1 仼 AAAA偱1
20 BBBB 2 仼 AAAA,BBBB偱2
30 AAAA 2 仼 AAAA,BBBB偱2
40 BBBB 2 仼 AAAA,BBBB偱2
50 CCCC 3 仼 AAAA,BBBB,CCCC偱3
60 CCCC 3 仼 AAAA,BBBB,CCCC偱3
70 DDDD 4 仼 AAAA,BBBB,CCCC,DDDD偱4
80 AAAA 4 仼 AAAA,BBBB,CCCC,DDDD偱4
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
夝愢偟傑偡偲丄
disVisit[any] 偵傛偭偰丄攝楍偺慡偰偺揧帤傪懳徾偲偟偰丄
count(distinct Visit)[SortKey <= cv()]) 傪媮傔偰傑偡丅
count(distinct Visit)[SortKey <= cv()]) 偱廤崌娭悢偺懳徾偲側傞偺偼丄
SortKey <= cv() 偑惉棫偡傞峴偺傒偲側傝傑偡丅
寢壥偲偟偰丄憡娭僒僽僋僄儕傪巊偭偨戙懼曽朄偲帡偨婰弎偵側傝傑偡偹丅
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
model嬪偺椺6 wmsys.wm_concat偺戙梡
暘愅娭悢偺wmsys.wm_concat偼丄Oracle11g偺儅僯儏傾儖偵偡傜嵹偭偰側偄偺偱丄model嬪偱戙梡偟偰傒傑偡丅
create table EmuWmTable(ID,SortKey,Str) as
select 1,10,'AA' from dual union all
select 1,20,'BB' from dual union all
select 1,35,'CC' from dual union all
select 2,10,'DD' from dual union all
select 2,25,'EE' from dual union all
select 3,10,'FF' from dual;
col ConStr for a10
-- 暘愅娭悢偺wmsys.wm_concat
select ID,SortKey,Str,
wmsys.wm_concat(Str) over(partition by ID order by SortKey) as ConStr
from EmuWmTable
order by ID,SortKey;
-- modelSample13
select ID,SortKey,Str,ConStr
from EmuWmTable
model
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(SortKey,Str,cast(null as varChar2(10)) as ConStr)
rules(
ConStr[any] order by rn = case when ConStr[cv()-1] is present
then ConStr[cv()-1] || ',' || Str[cv()]
else Str[cv()] end)
order by ID,SortKey;
ID SortKey Str ConStr
-- ------- --- --------
1 10 AA AA
1 20 BB AA,BB
1 35 CC AA,BB,CC
2 10 DD DD
2 25 EE DD,EE
3 10 FF FF
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
乽Row_Number娭悢偺partition by ID偼丄徣棯偱偒傞偺偱偼丠丠丠乿丄偲峫偊傑偟偨偐丠
model嬪偺partition by嬪偼丄rules嬪偑峴偆張棟傪僷乕僥傿僔儑儞偛偲偵暘妱偡傞嬪偱偡偺偱丄
dimension by嬪偺Row_Number娭悢偱傕丄partition by ID傪巜掕偟側偄偲偄偗傑偣傫丅
Row_Number娭悢偱嶌惉偟偨楢斣傪巊偭偰丄
嵟弶偐傜僙儖偑懚嵼偟偨偐偳偆偐丄
偄偄偐偊傟偽丄僙儖偑儀乕僗偺僋僄儕偐傜偺僾儗僛儞僩(憽傝暔)偐偳偆偐傪丄
case幃偱is present弎岅傪巊偭偰敾抐偟丄暥帤楍傪弴斣偵楢寢偝偣偰傑偡丅
楢寢弴彉偑廳梫側偺偱丄
ConStr[any] order by rn
偲偄偭偨宍偱order by偱儖乕儖偺昡壙弴彉傪巜掕偟偰傑偡丅
is present弎岅偺戙梡昳偲偟偰丄presentv娭悢偲偄偆娭悢傕偁傝傑偡丅
堷悢偺庢傝曽偼丄nvl2娭悢偲帡偰傑偡偹丅
-- modelSample14
select ID,SortKey,Str,ConStr
from EmuWmTable
model
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(SortKey,Str,cast(null as varChar2(10)) as ConStr)
rules(
ConStr[any] order by rn = presentv(ConStr[cv()-1],
ConStr[cv()-1] || ',' || Str[cv()],
Str[cv()]))
order by ID,SortKey;
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅

model嬪偺椺7 group_concat傕偳偒
wmsys.wm_concat偼丄楢寢弴彉傪order by偱巜掕偱偒傑偣傫偑丄
MySQL偺group_concat娭悢偼楢寢弴彉傪order by偱巜掕偱偒傑偡丅
MySQL偺group_concat娭悢傪model嬪偱戙梡偟偰傒傑偡丅
create table EmuGrConT(ID,SortKey,Str) as
select 1,10,'AA' from dual union all
select 1,20,'BB' from dual union all
select 1,35,'CC' from dual union all
select 2,10,'DD' from dual union all
select 2,25,'DD' from dual union all
select 2,30,'EE' from dual union all
select 2,35,'DD' from dual union all
select 3,10,'FF' from dual;
-- MySQL偱幚峴
select ID,group_Concat(Str order by SortKey) as conStr
from EmuGrConT
group by ID;
+----+-------------+
| ID | conStr |
+----+-------------+
| 1 | AA,BB,CC |
| 2 | DD,DD,EE,DD |
| 3 | FF |
+----+-------------+
col ConStr for a20
-- modelSample15
select ID,substr(ConStr,2) as ConStr
from EmuGrConT
model return updated rows
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(Str,cast(null as varChar2(20)) as ConStr)
rules iterate(50) until presentv(Str[iteration_number+2],1,0) = 0
(ConStr[0] = ConStr[0] || ',' || Str[iteration_number+1])
order by ID;
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
model return updated rows偑
寢壥僙僢僩偺峴傪尭傜偟偨偄帪偺掕斣偱偡丅
ITERATE偲until傪巊偭偨偲偒偺張棟弴彉偵偮偄偰棟夝偟偰偍偔偲偄偄偱偟傚偆丅
張棟1 ITERATION_NUMBER傪愰尵 (弶婜抣=0)
張棟2 rule揔梡
張棟3 廔椆忦審敾掕
張棟4 ITERATION_NUMBER傪僀儞僋儕儊儞僩
張棟5 張棟2傊栠傞
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
擼撪偺僀儊乕僕偼丄壓偺傛偆偵側傝傑偡丅
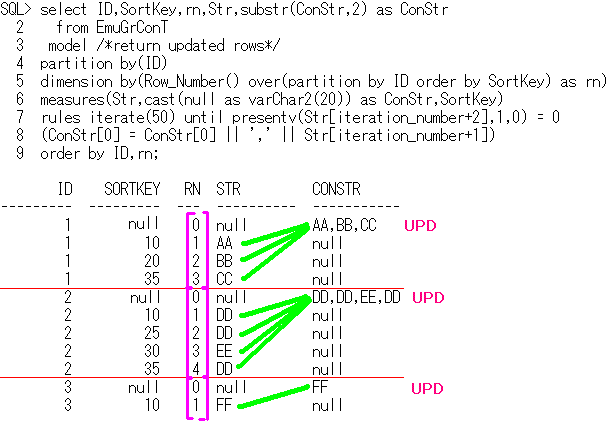 仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
揧帤偺0斣偱偼側偔丄揧帤偺1斣偵廤傔偰傕偄偄偱偡丅
-- modelSample16
select ID,substr(ConStr,2) as ConStr
from EmuGrConT
model return updated rows
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(Str,cast(null as varChar2(20)) as ConStr)
rules iterate(50) until presentv(Str[iteration_number+2],1,0) = 0
(ConStr[1] = ConStr[1] || ',' || Str[iteration_number+1])
order by ID;
仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭仭
揧帤偺0斣偱偼側偔丄揧帤偺1斣偵廤傔偰傕偄偄偱偡丅
-- modelSample16
select ID,substr(ConStr,2) as ConStr
from EmuGrConT
model return updated rows
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(Str,cast(null as varChar2(20)) as ConStr)
rules iterate(50) until presentv(Str[iteration_number+2],1,0) = 0
(ConStr[1] = ConStr[1] || ',' || Str[iteration_number+1])
order by ID;
model嬪偺嶲峫儕僜乕僗