گ}‚إƒCƒپپ[ƒW‚·‚éOracle‚جSQL‘SڈW‚جŒ³Œ´چe
‘و9‰ٌ Model‹ه
‘و7‰ٌ چؤ‹Awith‹ه
‘و8‰ٌ Pivot‚ئUnPivot
کAچع‚جƒeپ[ƒ}
‘O‰ٌ‚ئ“¯‚¶‚ئ‚ب‚è‚ـ‚·پB
“®چىٹm”Fٹآ‹«
Oracle Database 11g Release 11.2.0.1.0 (Windows 32ƒrƒbƒg”إ)
چ،‰ٌ‚جƒeپ[ƒ}
چ،‰ٌ‚حپA‰؛‹L‚جOracle‚جSQL•¶‚ج•]‰؟ڈ‡ڈک‚ة‚¨‚¢‚ؤ‚جپA
1”ش–ع‚جfrom‹ه‚إچs—ٌ•دٹ·‚ًچs‚¤‚±‚ئ‚ھ‚إ‚«‚éپAPivot‚ئUnPivot‚جژg—p—ل‚ئ
ژ„‚جSQL‚جƒCƒپپ[ƒW‚ً‰ًگà‚µ‚ـ‚·پB
1”ش–ع from‹ه
2”ش–ع where‹ه (Œ‹چ‡ڈًŒڈ)
3”ش–ع start with‹ه
4”ش–ع connect by‹ه
5”ش–ع where‹ه (چs‚جƒtƒBƒ‹ƒ^ڈًŒڈ)
6”ش–ع group by‹ه
7”ش–ع having‹ه
8”ش–ع model‹ه
9”ش–ع select‹ه
10”ش–ع unionپAminusپAintersect‚ب‚ا‚جڈWچ‡‰‰ژZ
11”ش–ع order by‹ه
–عژں
1 Pivot‚ئUnPivot‚ئ‚ح
select•¶‚إ‚جچs—ٌ•دٹ·
Pivot‚ئUnPivot‚حOracle11gR1‚جگV‹@”\‚إپAselect•¶‚إ‚جچs—ٌ•دٹ·‚ً—eˆص‚ةچs‚¤‚±‚ئ‚ھ‚إ‚«‚ـ‚·پB
‰pکaژ«“T‚جPivot‚جˆس–،‚ج’†‚إپAselect•¶‚إ‚جPivot‚جˆس–،‚ة‹ك‚¢‚à‚ج‚ً‘I‚ش‚ئپA
“®ژŒ‚إ‚حپAپuگù‰ٌ‚·‚é,‰ٌ“]‚·‚éپvپB–¼ژŒ‚إ‚حپAپuگù‰ٌژ²,‰ٌ“]ژ²پv‚ئ‚ب‚è‚ـ‚·پB
select•¶‚إ‚ج•]‰؟ڈ‡ڈک‚ة‚¨‚¢‚ؤپAPivot‚ئUnPivot‚حfrom‹ه‚جˆê•”‚ئ‚µ‚ؤ•]‰؟‚³‚ê‚ـ‚·پB
2 select•¶‚إ‚جPivot‚ئUnPivot‚ج•]‰؟ڈ‡ڈک
from‹ه‚جˆê•”‚ئ‚µ‚ؤ•]‰؟‚³‚ê‚ؤ‚¢‚é—ل
Pivot‚ئUnPivot‚حfrom‹ه‚جˆê•”‚ئ‚µ‚ؤ•]‰؟‚³‚ê‚é‚ج‚إ‰؛‹L‚ج‚و‚¤‚بselect•¶‚àژہچs‚إ‚«‚ـ‚·پB
Pivot‚âUnPivot‚µ‚½Œ‹‰ت‚ة•\•ت–¼‚ً•t‚¯‚邱‚ئ‚à‚إ‚«‚ـ‚·پB
-- from‹ه‚جˆê•”‚ئ‚µ‚ؤ•]‰؟‚³‚ê‚ؤ‚¢‚é—ل1
select * from (select 1 as ColA,5 as ColB from dual)
UnPivot(Vals1 for Cols1 in(ColA,ColA,ColA))
UnPivot(Vals2 for Cols2 in(ColB,ColB))
Pivot(count(*) for Vals1 in(1 as C1))
Pivot(count(*) for Vals2 in(5 as C2)) a
Join dual b
on a.C1 = 6;
ڈo—حŒ‹‰ت
Cols1 Cols2 C1 C2 Dummy
----- ----- -- -- -----
COLA COLB 6 1 X
-- from‹ه‚جˆê•”‚ئ‚µ‚ؤ•]‰؟‚³‚ê‚ؤ‚¢‚é—ل2
with work(ColA,ColB) as(
select 1,1 from dual union all
select 2,2 from dual)
select *
from work Join dual on 1=1
UnPivot(Vals for Cols in(ColA,ColB));
ڈo—حŒ‹‰ت
Dummy Cols Vals
----- ---- ----
X COLA 1
X COLB 1
X COLA 2
X COLB 2
3 Pivot‚جژg‚¢•û
چsژ‚؟ƒfپ[ƒ^‚ً—ٌژ‚؟ƒfپ[ƒ^‚ة•دٹ·
create table PivotSample(
ID number(1),
Year number(4),
Val number(3),
primary key (ID,Year));
insert into PivotSample
select 1,2010, 1 from dual union all
select 1,2011, 2 from dual union all
select 1,2012, 6 from dual union all
select 2,2010, 70 from dual union all
select 2,2011, 80 from dual union all
select 3,2012, 90 from dual union all
select 4,2010,300 from dual union all
select 4,2012,500 from dual;
Pivot‚ًژg‚ء‚ؤپAچsژ‚؟ƒfپ[ƒ^‚ً—ٌژ‚؟ƒfپ[ƒ^‚ة•دٹ·‚µ‚ؤ‚ف‚ـ‚·پB
-- Pivot‚جƒTƒ“ƒvƒ‹
select *
from PivotSample
Pivot (max(Val) for Year in(2010 as Agg2010,
2011 as Agg2011,
2012 as Agg2012))
order by ID;
ڈo—حŒ‹‰ت
ID Agg2010 Agg2011 Agg2012
-- ------- ------- -------
1 1 2 6
2 70 80 null
3 null null 90
4 300 null 500
Pivot‚جچ\•¶‚حپA‰؛‹L‚ج‚و‚¤‚ة—‰ً‚µ‚ؤ‚¨‚‚ئ‚¢‚¢‚إ‚µ‚ه‚¤پB
Pivot(ڈW–ٌٹضگ” for ڈW–ٌڈًŒڈ—ٌ in(ڈW–ٌڈًŒڈ’l1 as ڈW–ٌŒم—ٌ–¼1,
ڈW–ٌڈًŒڈ’l2 as ڈW–ٌŒم—ٌ–¼2,
ڈW–ٌڈًŒڈ’l3 as ڈW–ٌŒم—ٌ–¼3))
Pivot‚إ‚حپA
ڈW–ٌٹضگ”‚إژg—p‚µ‚ؤ‚¢‚é—ٌ‚إ‚ب‚پA‚©‚آڈW–ٌڈًŒڈ—ٌ‚إژg—p‚µ‚ؤ‚¢‚é—ٌ‚إ‚à‚ب‚¢—ٌ‚إپA
ˆأ–ظ‚جgroup by‚ھژہچs‚³‚ê‚ـ‚·پB
ڈم‹L‚جselect•¶‚ة‚¨‚¢‚ؤ‚حپA
ڈW–ٌٹضگ”‚إژg—p‚µ‚ؤ‚¢‚é—ٌ‚حپAVal—ٌ‚إ‚·پBmax(Val)‚ئ‚¢‚ء‚½Œ`‚إVal—ٌ‚ًژg—p‚µ‚ؤ‚¢‚é‚©‚ç‚إ‚·پB
‚»‚µ‚ؤپAڈW–ٌڈًŒڈ—ٌ‚إژg—p‚µ‚ؤ‚¢‚é—ٌ‚حپAYear—ٌ‚إ‚·پB
‚و‚ء‚ؤپAڈW–ٌٹضگ”‚إژg—p‚µ‚ؤ‚¢‚é—ٌ‚إ‚ب‚پA‚©‚آڈW–ٌڈًŒڈ—ٌ‚إژg—p‚µ‚ؤ‚¢‚é—ٌ‚إ‚à‚ب‚¢پA
ID—ٌ‚إˆأ–ظ‚جgroup by‚ھژہچs‚³‚ê‚ـ‚·پB
Pivot‚جSQL‚جƒCƒپپ[ƒW‚ح‰؛‹L‚ئ‚ب‚è‚ـ‚·پB
ˆأ–ظ‚جgroup by‚ة‚و‚éگشگü‚ًƒCƒپپ[ƒW‚µپA
for ڈW–ٌڈًŒڈ—ٌ (ڈم‹L‚جselect•¶‚إ‚حپAfor Year‚ج•”•ھ) ‚إ‰©—خگü‚ًƒCƒپپ[ƒW‚µ‚ؤ‚ـ‚·پB
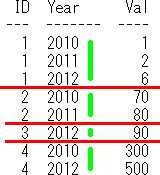 ‰؛‹L‚ج‚و‚¤‚ةپAڈW–ٌŒم—ٌ–¼‚جژw’è‚ًڈب—ھ‚·‚邱‚ئ‚à‚إ‚«‚ـ‚·پB(ڈW–ٌڈًŒڈ’l‚ھ—ٌ–¼‚ة‚ب‚è‚ـ‚·)
-- ڈW–ٌŒم—ٌ–¼‚جژw’è‚ًڈب—ھ
select *
from PivotSample
Pivot (max(Val) for Year in(2010,2011,2012))
order by ID;
ڈo—حŒ‹‰ت
ID 2010 2011 2012
-- ---- ---- ----
1 1 2 6
2 70 80 null
3 null null 90
4 300 null 500
‰؛‹L‚ج‚و‚¤‚ةپAڈW–ٌŒم—ٌ–¼‚جژw’è‚ًڈب—ھ‚·‚邱‚ئ‚à‚إ‚«‚ـ‚·پB(ڈW–ٌڈًŒڈ’l‚ھ—ٌ–¼‚ة‚ب‚è‚ـ‚·)
-- ڈW–ٌŒم—ٌ–¼‚جژw’è‚ًڈب—ھ
select *
from PivotSample
Pivot (max(Val) for Year in(2010,2011,2012))
order by ID;
ڈo—حŒ‹‰ت
ID 2010 2011 2012
-- ---- ---- ----
1 1 2 6
2 70 80 null
3 null null 90
4 300 null 500
4 Pivot‚ج‘م—p–@
ڈW–ٌٹضگ”‚ئdecodeٹضگ”‚ج‘g‚فچ‡‚ي‚¹
-- Pivot‚ج‘م—p (ڈW–ٌٹضگ”‚ئdecodeٹضگ”)
select ID,
max(decode(Year,2010,Val)) as Agg2010,
max(decode(Year,2011,Val)) as Agg2011,
max(decode(Year,2012,Val)) as Agg2012
from PivotSample
group by ID
order by ID;
ڈo—حŒ‹‰ت
ID Agg2010 Agg2011 Agg2012
-- ------- ------- -------
1 1 2 6
2 70 80 null
3 null null 90
4 300 null 500
Pivot‚حپAڈم‹L‚ج‚و‚¤‚ةپAڈW–ٌٹضگ”‚ئdecodeٹضگ”‚ً‘g‚فچ‡‚ي‚¹‚邱‚ئ‚إ‘م—p‚إ‚«‚ـ‚·پB
decodeٹضگ”‚إڈW–ٌ‘خڈغٹO‚جƒfپ[ƒ^‚ًnull‚ة•دٹ·‚µپAڈW–ٌٹضگ”‚ھnull‚ً–³ژ‹‚·‚éگ«ژ؟‚ًژg‚ء‚ؤ‚ـ‚·پB
5 Pivot‚ئپAPivot‚ج‘م—p–@‚ً”نٹr
ˆأ–ظ‚جgroup by‚حƒCƒپپ[ƒW‚µ‚ة‚‚¢
Pivot‚ئپAPivot‚ج‘م—p–@(ڈW–ٌٹضگ”‚ئdecodeٹضگ”)‚ج”نٹrŒ‹‰ت‚ئ‚µ‚ؤپA
—¼ژز‚حژg‚¢•ھ‚¯‚é‚ج‚ھ‚¢‚¢‚ئژv‚ي‚ê‚ـ‚·پB——R‚ح‰؛‹L‚إ‚·پB
پE——R1 Pivot‚إ‚حپAˆأ–ظ‚جgroup by‚ھژہچs‚³‚êپAˆأ–ظ‚جgroup by‚حƒCƒپپ[ƒW‚µ‚ة‚‚¢
پE——R2 Pivot‚إپA•s—v‚ب—ٌ‚ًˆأ–ظ‚جgroup by‚ج‘خڈغٹO‚ة‚·‚é‚ة‚حپAƒCƒ“ƒ‰ƒCƒ“ƒrƒ…پ[‚ھ•K—v
پE——R3 Pivot‚إŒvژZژ®‚ًژg—p‚·‚é‚ة‚حپAƒCƒ“ƒ‰ƒCƒ“ƒrƒ…پ[‚ھ•K—v
——R1‚جˆأ–ظ‚جgroup by‚حپAPivot‚جژg‚¢•û‚إگà–¾‚µ‚½‚ج‚إپA
——R2‚ئ3‚ج—ل‚ئ‚µ‚ؤپAŒژ‚²‚ئ‚جVal‚جچ‡Œv‚ً•\ژ¦‚·‚éselect•¶‚ً”نٹr‚µ‚ـ‚·پB
create table PivotCompare(
DayCol date primary key,
Val number(3),
bikou VarChar2(6));
insert into PivotCompare
select date '2012-01-05', 10,'bikou1' from dual union all
select date '2012-01-16', 20,'bikou2' from dual union all
select date '2012-01-28', 60,'bikou3' from dual union all
select date '2012-02-11',200,null from dual union all
select date '2012-02-22',300,null from dual union all
select date '2012-03-30',700,'bikou4' from dual;
-- Pivot‚ج‘م—p (ڈW–ٌٹضگ”‚ئdecodeٹضگ”)
select
sum(decode(extract(month from DayCol),1,Val)) as sum1,
count(decode(extract(month from DayCol),1,Val)) as cnt1,
sum(decode(extract(month from DayCol),2,Val)) as sum2,
count(decode(extract(month from DayCol),2,Val)) as cnt2,
sum(decode(extract(month from DayCol),3,Val)) as sum3,
count(decode(extract(month from DayCol),3,Val)) as cnt3
from PivotCompare;
ڈo—حŒ‹‰ت
sum1 cnt1 sum2 cnt2 sum3 cnt3
---- ---- ---- ---- ---- ----
90 3 500 2 700 1
-- Pivot‚ًژg—p
select *
from (select extract(month from DayCol) as month,Val
from PivotCompare)
Pivot (sum(Val) as sum,
count(*) as cnt
for month in(1,2,3));
ڈo—حŒ‹‰ت
1_SUM 1_CNT 2_SUM 2_CNT 3_SUM 3_CNT
----- ----- ----- ----- ----- -----
90 3 500 2 700 1
extract(month from DayCol)‚ئ‚¢‚ء‚½ŒvژZژ®‚ًژg‚ء‚ؤPivot‚ًچs‚¤‚ة‚حپAƒCƒ“ƒ‰ƒCƒ“ƒrƒ…پ[‚ھ•K—v‚ئ‚ب‚è‚ـ‚·پB
‰؛‹L‚ج‚و‚¤‚ةپA•¶–@ƒGƒ‰پ[‚ة‚ب‚é‚©‚ç‚إ‚·پB
-- •¶–@ƒGƒ‰پ[ ORA-01738: INƒLپ[ƒڈپ[ƒh‚ھ‚ ‚è‚ـ‚¹‚ٌپB
select *
from PivotCompare
Pivot (sum(Val) as sum,
count(*) as cnt
for extract(month from DayCol) in(1,2,3));
‚ـ‚½پAbikou—ٌ‚ھپAˆأ–ظ‚جgroup by‚جƒOƒ‹پ[ƒv‰»‚جƒLپ[‚ج1‚آ‚ة‚ب‚邱‚ئ‚ً–h‚®‚½‚ك‚ة‚àپA
bikou—ٌ‚ًڈœ‚¢‚½select•¶‚ًژg‚ء‚½ƒCƒ“ƒ‰ƒCƒ“ƒrƒ…پ[‚ھ•K—v‚ئ‚ب‚è‚ـ‚·پB
6 Pivot‚جƒTƒ“ƒvƒ‹ڈW
Pivot‚جگ—Œ`
-- ٹî–{“I‚بPivot ‚»‚ج1
with t(ID,Seq,Val) as(
select 111,1,77 from dual union all
select 111,2,66 from dual union all
select 111,3,55 from dual union all
select 222,1,44 from dual union all
select 222,3,33 from dual union all
select 333,2,22 from dual)
select * from t
Pivot(max(Val) for Seq in(1,2,3))
order by ID;
ڈo—حŒ‹‰ت
ID 1 2 3
--- ---- ---- ----
111 77 66 55
222 44 null 33
333 null 22 null
-- ٹî–{“I‚بPivot ‚»‚ج2
with t(ID,Seq,Val) as(
select 111,1,77 from dual union all
select 111,2,66 from dual union all
select 111,3,55 from dual union all
select 222,1,44 from dual union all
select 222,3,33 from dual union all
select 333,2,22 from dual)
select * from t
Pivot(max(Val) for Seq in(1 as Seq1,
2 as Seq2,
3 as Seq3))
order by ID;
ڈo—حŒ‹‰ت
ID Seq1 Seq2 Seq3
--- ---- ---- ----
111 77 66 55
222 44 null 33
333 null 22 null
-- •،گ”—ٌ‚إPivot ‚»‚ج1
with t(ID,Year,Month,Val) as(
select 1,2012,1, 10 from dual union all
select 1,2012,2, 20 from dual union all
select 1,2012,3, 60 from dual union all
select 2,2012,1,300 from dual union all
select 2,2012,3,500 from dual union all
select 3,2012,2,900 from dual)
select * from t
Pivot(max(Val)
for (Year,Month)
in ((2012,1) as Agg1,
(2012,2) as Agg2,
(2012,3) as Agg3));
ڈo—حŒ‹‰ت
ID Agg1 Agg2 Agg3
-- ---- ---- ----
1 10 20 60
2 300 null 500
3 null 900 null
-- •،گ”—ٌ‚إPivot ‚»‚ج2
with t(ID,Year,Month,Val) as(
select 1,2012,1, 10 from dual union all
select 1,2012,1,700 from dual union all
select 1,2012,2, 20 from dual union all
select 1,2012,3, 60 from dual union all
select 2,2012,1,300 from dual union all
select 2,2012,1,999 from dual union all
select 2,2012,3,500 from dual union all
select 3,2012,2,900 from dual)
select * from t
Pivot(count(*) as cnt,
max(Val) as max
for (Year,Month)
in ((2012,1) as Agg1,
(2012,2) as Agg2,
(2012,3) as Agg3));
ڈo—حŒ‹‰ت
ID AGG1_CNT AGG1_MAX AGG2_CNT AGG2_MAX AGG3_CNT AGG3_MAX
-- -------- -------- -------- -------- -------- --------
1 2 700 1 20 1 60
2 2 999 0 null 1 500
3 0 null 1 900 0 null
7 UnPivot‚جژg‚¢•û
—ٌژ‚؟ƒfپ[ƒ^‚ًچsژ‚؟ƒfپ[ƒ^‚ة•دٹ·
create table UnPivotSample(
ID number(1) primary key,
Val1 number(2),
Val2 number(2),
Val3 number(2));
insert into UnPivotSample
select 1,12, 11, 10 from dual union all
select 3,30, 90,null from dual union all
select 5,50,null,null from dual;
UnPivot‚ًژg‚ء‚ؤپA—ٌژ‚؟ƒfپ[ƒ^‚ًچsژ‚؟ƒfپ[ƒ^‚ة•دٹ·‚µ‚ؤ‚ف‚ـ‚·پB
-- UnPivot‚جƒTƒ“ƒvƒ‹
select ID,Vals,Cols
from UnPivotSample
UnPivot(Vals for Cols in(Val1,Val2,Val3));
ڈo—حŒ‹‰ت
ID Vals Cols
-- ---- ----
1 12 VAL1
1 11 VAL2
1 10 VAL3
3 30 VAL1
3 90 VAL2
5 50 VAL1
ڈم‹L‚جڈo—حŒ‹‰ت‚إ‚حپAVals‚ھnull‚جچs‚ھڈo—ح‚³‚ê‚ؤ‚ب‚¢‚إ‚·‚ثپB
UnPivot‚حپAƒfƒtƒHƒ‹ƒg‚إExclude nulls‚ب‚½‚كپA
UnPivot‘خڈغ‚ھnull‚جچs‚àڈo—ح‚·‚é‚ة‚حپAInclude nulls‚ًژw’è‚·‚é•K—v‚ھ‚ ‚è‚ـ‚·پB
-- Include nulls‚ًژw’肵‚½UnPivot
select ID,Vals,Cols
from UnPivotSample
UnPivot Include nulls
(Vals for Cols in(Val1,Val2,Val3));
ڈo—حŒ‹‰ت
ID Vals Cols
-- ---- ----
1 12 VAL1
1 11 VAL2
1 10 VAL3
3 30 VAL1
3 90 VAL2
3 null VAL3
5 50 VAL1
5 null VAL2
5 null VAL3
UnPivot‚جچ\•¶‚حپA‰؛‹L‚ج‚و‚¤‚ة—‰ً‚µ‚ؤ‚¨‚‚ئ‚¢‚¢‚إ‚µ‚ه‚¤پB
UnPivot(—ٌ’l‚ً•\ژ¦‚·‚é—ٌ–¼ for Œ³—ٌ‚جژ¯•ت’l‚ً•\ژ¦‚·‚é—ٌ–¼ in(Œ³—ٌ1,Œ³—ٌ2,Œ³—ٌ3))
UnPivot‚جSQL‚جƒCƒپپ[ƒW‚ح‰؛‹L‚ئ‚ب‚è‚ـ‚·پB
چs‚²‚ئ‚ة‹وگط‚éگشگü‚ًˆّ‚¢‚ؤپAŒ³—ٌ2‚ئŒ³—ٌ3‚ًپAŒ³—ٌ1‚ج‰؛‚ةˆع“®‚³‚¹‚鉩—خگü‚ًˆّ‚¢‚ؤ‚ـ‚·پB
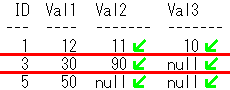 ‰؛‹L‚ج‚و‚¤‚ةپAŒ³—ٌ‚جژ¯•ت’l‚ًژw’è‚·‚邱‚ئ‚à‚إ‚«‚ـ‚·پB
Val1—ٌ‚جŒ³—ٌ‚جژ¯•ت’l‚ًMoto1,Val2—ٌ‚جŒ³—ٌ‚جژ¯•ت’l‚ًMoto2,Val3—ٌ‚جŒ³—ٌ‚جژ¯•ت’l‚ًMoto3‚ئ‚µ‚ؤ‚ف‚ـ‚·پB
-- Œ³—ٌ‚جژ¯•ت’l‚ًژw’è
select ID,Vals,Cols
from UnPivotSample
UnPivot(Vals for Cols in(Val1 as 'Moto1',
Val2 as 'Moto2',
Val3 as 'Moto3'));
ڈo—حŒ‹‰ت
ID Vals Cols
-- ---- -----
1 12 Moto1
1 11 Moto2
1 10 Moto3
3 30 Moto1
3 90 Moto2
5 50 Moto1
‰؛‹L‚ج‚و‚¤‚ةپAŒ³—ٌ‚جژ¯•ت’l‚ئ‚µ‚ؤگ”’lŒ^‚ًژw’肵پA
order by‹ه‚إ‚جƒ\پ[ƒgƒLپ[‚جژw’è‚ةژg‚¤‚±‚ئ‚à‚إ‚«‚ـ‚·پB
-- گ”’lŒ^‚جƒ\پ[ƒgƒLپ[‚ًژ‚½‚¹‚½UnPivot
select ID,Vals,SortKeys
from UnPivotSample
UnPivot(Vals for SortKeys in(Val1 as 1,
Val2 as 2,
Val3 as 3))
order by ID,SortKeys;
ڈo—حŒ‹‰ت
ID Vals SortKeys
-- ---- --------
1 12 1
1 11 2
1 10 3
3 30 1
3 90 2
5 50 1
‰؛‹L‚ج‚و‚¤‚ةپAŒ³—ٌ‚جژ¯•ت’l‚ئ‚µ‚ؤگ”’lŒ^‚ئ—ٌ–¼‚ج—¼•û‚ًژw’è‚·‚邱‚ئ‚à‚إ‚«‚ـ‚·پB
ڈَ‹µ‚ة‰‚¶‚ؤژg‚¢•ھ‚¯‚é‚ئ‚¢‚¢‚إ‚µ‚ه‚¤پB
-- Œ³—ٌ‚جژ¯•ت’l‚ئ‚µ‚ؤگ”’lŒ^‚ئ—ٌ–¼‚ج—¼•û‚ًژw’è
select ID,Vals,SortKeys,Moto
from UnPivotSample
UnPivot (Vals for (SortKeys,Moto)
in(Val1 as (1,'Moto1'),
Val2 as (2,'Moto2'),
Val3 as (3,'Moto3')))
order by ID,SortKeys;
ڈo—حŒ‹‰ت
ID Vals SortKeys Moto
-- ---- -------- -----
1 12 1 Moto1
1 11 2 Moto2
1 10 3 Moto3
3 30 1 Moto1
3 90 2 Moto2
5 50 1 Moto1
‰؛‹L‚ج‚و‚¤‚ةپAŒ³—ٌ‚جژ¯•ت’l‚ًژw’è‚·‚邱‚ئ‚à‚إ‚«‚ـ‚·پB
Val1—ٌ‚جŒ³—ٌ‚جژ¯•ت’l‚ًMoto1,Val2—ٌ‚جŒ³—ٌ‚جژ¯•ت’l‚ًMoto2,Val3—ٌ‚جŒ³—ٌ‚جژ¯•ت’l‚ًMoto3‚ئ‚µ‚ؤ‚ف‚ـ‚·پB
-- Œ³—ٌ‚جژ¯•ت’l‚ًژw’è
select ID,Vals,Cols
from UnPivotSample
UnPivot(Vals for Cols in(Val1 as 'Moto1',
Val2 as 'Moto2',
Val3 as 'Moto3'));
ڈo—حŒ‹‰ت
ID Vals Cols
-- ---- -----
1 12 Moto1
1 11 Moto2
1 10 Moto3
3 30 Moto1
3 90 Moto2
5 50 Moto1
‰؛‹L‚ج‚و‚¤‚ةپAŒ³—ٌ‚جژ¯•ت’l‚ئ‚µ‚ؤگ”’lŒ^‚ًژw’肵پA
order by‹ه‚إ‚جƒ\پ[ƒgƒLپ[‚جژw’è‚ةژg‚¤‚±‚ئ‚à‚إ‚«‚ـ‚·پB
-- گ”’lŒ^‚جƒ\پ[ƒgƒLپ[‚ًژ‚½‚¹‚½UnPivot
select ID,Vals,SortKeys
from UnPivotSample
UnPivot(Vals for SortKeys in(Val1 as 1,
Val2 as 2,
Val3 as 3))
order by ID,SortKeys;
ڈo—حŒ‹‰ت
ID Vals SortKeys
-- ---- --------
1 12 1
1 11 2
1 10 3
3 30 1
3 90 2
5 50 1
‰؛‹L‚ج‚و‚¤‚ةپAŒ³—ٌ‚جژ¯•ت’l‚ئ‚µ‚ؤگ”’lŒ^‚ئ—ٌ–¼‚ج—¼•û‚ًژw’è‚·‚邱‚ئ‚à‚إ‚«‚ـ‚·پB
ڈَ‹µ‚ة‰‚¶‚ؤژg‚¢•ھ‚¯‚é‚ئ‚¢‚¢‚إ‚µ‚ه‚¤پB
-- Œ³—ٌ‚جژ¯•ت’l‚ئ‚µ‚ؤگ”’lŒ^‚ئ—ٌ–¼‚ج—¼•û‚ًژw’è
select ID,Vals,SortKeys,Moto
from UnPivotSample
UnPivot (Vals for (SortKeys,Moto)
in(Val1 as (1,'Moto1'),
Val2 as (2,'Moto2'),
Val3 as (3,'Moto3')))
order by ID,SortKeys;
ڈo—حŒ‹‰ت
ID Vals SortKeys Moto
-- ---- -------- -----
1 12 1 Moto1
1 11 2 Moto2
1 10 3 Moto3
3 30 1 Moto1
3 90 2 Moto2
5 50 1 Moto1
8 UnPivot‚ج‘م—p–@
union all‚ب‚ا‚إUnPivot‚ً‘م—p
UnPivot‚ج‘م—p–@‚ئ‚µ‚ؤ‚حپA‰؛‹L‚ج‚و‚¤‚ةunion all‚ًژg‚¤•û–@‚ھ‚ ‚è‚ـ‚·پB
-- UnPivot‚ج‘م—p (union all)
with tmp(ID,Vals,SortKeys) as(
select ID,Val1,1 from UnPivotSample union all
select ID,Val2,2 from UnPivotSample union all
select ID,Val3,3 from UnPivotSample)
select ID,Vals,SortKeys
from tmp
order by ID,SortKeys;
ڈo—حŒ‹‰ت
ID Vals SortKeys
-- ---- --------
1 12 1
1 11 2
1 10 3
3 30 1
3 90 2
3 null 3
5 50 1
5 null 2
5 null 3
‰؛‹L‚ج‚و‚¤‚ةکA”ش•\‚ئƒNƒچƒXƒWƒ‡ƒCƒ“‚³‚¹‚é•û–@‚àپAUnPivot‚ج‘م—p–@‚ئ‚µ‚ؤژg‚¦‚ـ‚·پB
-- UnPivot‚ج‘م—p (کA”ش•\‚ئƒNƒچƒXƒWƒ‡ƒCƒ“)
select a.ID,
case b.Cnter
when 1 then a.Val1
when 2 then a.Val2
when 3 then a.Val3 end as Vals,b.Cnter
from UnPivotSample a,
(select 1 as Cnter from dual union all
select 2 from dual union all
select 3 from dual) b
order by a.ID,b.Cnter;
ڈo—حŒ‹‰ت
ID Vals Cnter
-- ---- -----
1 12 1
1 11 2
1 10 3
3 30 1
3 90 2
3 null 3
5 50 1
5 null 2
5 null 3
‰؛‹L‚ج‚و‚¤‚ةsys.odciNumberList‚àپAUnPivot‚ج‘م—p–@‚ئ‚µ‚ؤژg‚¦‚ـ‚·پB
‚½‚¾‚µپA‚±‚ج‘م—p–@‚إ‚حپAŒ³پX‚ا‚ج—ٌ‚ج’l‚¾‚ء‚½‚©‚ھ•ھ‚©‚ç‚ب‚‚ب‚è‚ـ‚·پB
—ل‚¦‚خپA‰؛‹L‚جselect•¶‚إ‚حپAٹeVals—ٌ‚ھŒ³پX‚حپAVal1—ٌ,Val2—ٌ,Val3—ٌ‚ج‚ا‚ꂾ‚ء‚½‚©‚ھ•ھ‚©‚ç‚ب‚¢‚إ‚·پB
‚»‚ج‚½‚كپAorder by‹ه‚إƒ\پ[ƒgڈ‡ڈک‚ً–¾ژ¦‚إ‚«‚ب‚‚ب‚ء‚ؤ‚µ‚ـ‚¢‚ـ‚·پB
-- UnPivot‚ج‘م—p (sys.odciNumberList)
select ID,column_value as Vals
from UnPivotSample,table(sys.odciNumberList(Val1,Val2,Val3));
ڈo—حŒ‹‰ت
ID Vals
-- ----
1 12
1 11
1 10
3 30
3 90
3 null
5 50
5 null
5 null
9 UnPivot‚ئپAUnPivot‚ج‘م—p–@‚ً”نٹr
UnPivot‚جچ\•¶‚حƒVƒ“ƒvƒ‹
UnPivot‚ئپAUnPivot‚ج‘م—p–@‚ج”نٹrŒ‹‰ت‚ئ‚µ‚ؤپA
UnPivot‚جچ\•¶‚حƒVƒ“ƒvƒ‹‚إ“ا‚ف‚â‚·‚¢‚ج‚إپAUnPivot‚ھژg‚¦‚éOracle11gR1ˆبچ~‚إ‚حپAUnPivot‚ًژg‚¢پA
UnPivot‚ھژg‚¦‚ب‚¢Oracle10g‚ب‚ا‚إ‚حپA‘Oڈq‚µ‚½UnPivot‚ج‘م—p–@‚ًژg‚¢•ھ‚¯‚é‚ج‚ھ‚¢‚¢‚ئژv‚ي‚ê‚ـ‚·پB
10 UnPivot‚جƒTƒ“ƒvƒ‹ڈW
UnPivot‚جگ—Œ`
-- ٹî–{“I‚بUnPivot ‚»‚ج1
with t(ID,Val1,Val2) as(
select 5,10,90 from dual union all
select 6,20,80 from dual union all
select 7,30,70 from dual)
select * from t
UnPivot(Vals for Cols in(Val1,Val2));
ڈo—حŒ‹‰ت
ID Cols Vals
-- ---- ----
5 VAL1 10
5 VAL2 90
6 VAL1 20
6 VAL2 80
7 VAL1 30
7 VAL2 70
-- ٹî–{“I‚بUnPivot ‚»‚ج2
with t(ID,Val1,Val2) as(
select 5,10,90 from dual union all
select 6,20,80 from dual union all
select 7,30,70 from dual)
select * from t
UnPivot(Vals for SortKeys
in(Val1 as 1,
Val2 as 2))
order by ID,SortKeys;
ڈo—حŒ‹‰ت
ID SortKeys Vals
-- -------- ----
5 1 10
5 2 90
6 1 20
6 2 80
7 1 30
7 2 70
-- ٹî–{“I‚بUnPivot ‚»‚ج3
with t(ID,Val1,Val2) as(
select 5,10,90 from dual union all
select 6,20,80 from dual union all
select 7,30,70 from dual)
select * from t
UnPivot(Vals for (SortKeys,Moto)
in(Val1 as (1,'Moto1'),
Val2 as (2,'Moto2')))
order by ID,SortKeys;
ڈo—حŒ‹‰ت
ID SortKeys Moto Vals
-- -------- ----- ----
5 1 Moto1 10
5 2 Moto2 90
6 1 Moto1 20
6 2 Moto2 80
7 1 Moto1 30
7 2 Moto2 70
-- •،گ”—ٌ‚إUnPivot ‚»‚ج1
with t(ID,Val1,Name1,Val2,Name2) as(
select 1,11,'AA',66,'FF' from dual union all
select 2,22,'BB',77,'GG' from dual union all
select 3,33,'CC',88,'HH' from dual union all
select 4,44,'DD',99,'II' from dual union all
select 5,55,'EE',20,'JJ' from dual)
select * from t
UnPivot((Vals,Names) for Cols
in((Val1,Name1) as 'V1N1',
(Val2,Name2) as 'V2N2'));
ڈo—حŒ‹‰ت
ID Cols Vals Names
-- ---- ---- -----
1 V1N1 11 AA
1 V2N2 66 FF
2 V1N1 22 BB
2 V2N2 77 GG
3 V1N1 33 CC
3 V2N2 88 HH
4 V1N1 44 DD
4 V2N2 99 II
5 V1N1 55 EE
5 V2N2 20 JJ
-- •،گ”—ٌ‚إUnPivot ‚»‚ج2
with t(ID,Val1,Name1,Val2,Name2) as(
select 1,11,'AA',66,'FF' from dual union all
select 2,22,'BB',77,'GG' from dual union all
select 3,33,'CC',88,'HH' from dual union all
select 4,44,'DD',99,'II' from dual union all
select 5,55,'EE',20,'JJ' from dual)
select * from t
UnPivot((Vals,Names) for (Col1,Col2)
in((Val1,Name1) as ('V1','N1'),
(Val2,Name2) as ('V2','N2')));
ڈo—حŒ‹‰ت
ID Col1 Col2 Vals Names
-- ---- ---- ---- -----
1 V1 N1 11 AA
1 V2 N2 66 FF
2 V1 N1 22 BB
2 V2 N2 77 GG
3 V1 N1 33 CC
3 V2 N2 88 HH
4 V1 N1 44 DD
4 V2 N2 99 II
5 V1 N1 55 EE
5 V2 N2 20 JJ
-- UnPivot‚µ‚ؤPivot
with t(ID,Val1,Val2,Val3,Val4) as(
select 'Sat',10,15,20,25 from dual union all
select 'Sun',30,35,40,45 from dual union all
select 'Mon',50,55,60,65 from dual)
select * from t
UnPivot(Vals for Cols in(Val1,Val2,Val3,Val4))
Pivot (max(Vals) for ID in('Sat' as Sat,'Sun' as Sun,'Mon' as Mon))
order by Cols;
ڈo—حŒ‹‰ت
Cols Sat Sun Mon
---- --- --- ---
VAL1 10 30 50
VAL2 15 35 55
VAL3 20 40 60
VAL4 25 45 65
ژQچlƒٹƒ\پ[ƒX