図でイメージするOracleのSQL全集の元原稿
第5回 RollUp集計など
第3回 分析関数
第4回 集約関数など
連載のテーマ,動作確認環境
前回と同じとなります。
今回のテーマ
今回は、下記のOracleのSQL文の評価順序においての、
7番目のhaving句と9番目のselect句で主に使用される、集約関数などについて
私のSQLのイメージを解説します。
1番目 from句
2番目 where句 (結合条件)
3番目 start with句
4番目 connect by句
5番目 where句 (行のフィルタ条件)
6番目 group by句
7番目 having句
8番目 model句
9番目 select句
10番目 union、minus、intersectなどの集合演算
11番目 order by句
目次
1 集約関数の使用例
集約関数を使うと、複数行を対象として最大値や最小値や合計などを求めることができます。
集約関数を使う際には、group by句でグループ化するキーを指定することが多いですが、
group by句なしで、集約関数を使うこともできます。
2 集約関数の使用頻度
使用頻度の高いものからおさえていくと学習効率が高いです。
最頻出
count max min sum
頻出
ListAgg wmsys.wm_concat
たまに
avg median stats_mode
レア
regr_count dense_rank
3 countとmaxとminとsum
データ件数や最大値や最小値や合計を求める
要素数(データ件数)を求めるのがcount関数。
最大値を求めるのがmax関数。
最小値を求めるのがmin関数。
数値型の合計を求めるのがsum関数となります。
create table AggSample1(ID,Val) as
select 111,0 from dual union all
select 111,2 from dual union all
select 111,6 from dual union all
select 222,4 from dual union all
select 222,5 from dual union all
select 333,7 from dual;
IDごとの、データ件数,Valの最大値,Valの最小値,Valの合計を求めてみます。
select ID,count(*) as cnt,
max(Val) as maxVal,min(Val) as minVal,
sum(Val) as sumVal
from AggSample1
group by ID
order by ID;
出力結果
ID cnt maxVal minVal sumVal
--- --- ------ ------ ------
111 3 6 0 8
222 2 5 4 9
333 1 7 7 7
4 ListAggとwmsys.wm_concat
文字列を連結してまとめる
ListAgg関数やwmsys.wm_concat関数を使うと、文字列を連結してまとめることができます。
wmsys.wm_concat関数は、Oracle11gR2の段階でマニュアルに記載されていないので、注意して使う必要があります。
wmsys.wm_concat関数と似たような機能を持つListAgg関数は、Oracle11gR2で追加された関数です。
create table AggSample2(ID,Val) as
select 111,'A' from dual union all
select 111,'B' from dual union all
select 111,'C' from dual union all
select 222,'D' from dual union all
select 222,'E' from dual union all
select 333,'F' from dual;
IDごとの、Valを連結した値を求めてみます。
select ID,
wmsys.wm_concat(Val) as strAgg1,
ListAgg(Val,',') withIn group(order by Val) as strAgg2,
ListAgg(Val,',') withIn group(order by Val desc) as strAgg3
from AggSample2
group by ID
order by ID;
出力結果
ID strAgg1 strAgg2 strAgg3
--- ------- ------- -------
111 A,C,B A,B,C C,B,A
222 D,E D,E E,D
333 F F F
5 avgとmedianとstats_mode
平均値や中央値や最頻値を求める
数値型の平均値を求めるのがavg関数。
中央値(メジアン)を求めるのがmedian関数。
最頻値(モード)を求めるのがstats_mode関数となります。
create table AggSample3(ID,Val) as
select 111,10 from dual union all
select 111,30 from dual union all
select 222,40 from dual union all
select 222,40 from dual union all
select 333,10 from dual union all
select 333,10 from dual union all
select 333,40 from dual union all
select 444,60 from dual union all
select 444,90 from dual;
IDごとの、Valの平均値,Valの中央値,Valの最頻値を求めてみます。
select ID,
avg(Val) as avgVal,
median(Val) as medianVal,
stats_mode(Val) as modeVal
from AggSample3
group by ID
order by ID;
出力結果
ID avgVal medianVal modeVal
--- ------ --------- -------
111 20 20 10
222 40 40 40
333 20 10 10
444 75 75 60
6 group by句のイメージ
グループ化のキーごとに区切る赤線
create table AggImage(ID,Val) as
select 111,0 from dual union all
select 111,2 from dual union all
select 222,7 from dual union all
select 222,8 from dual union all
select 222,9 from dual union all
select 333,1 from dual union all
select 333,2 from dual union all
select 444,6 from dual union all
select 444,8 from dual union all
select 444,9 from dual;
select ID,count(*) as cnt
from AggImage
group by ID
order by ID;
出力結果
ID cnt
--- ---
111 2
222 3
333 2
444 3
group by句のイメージは、分析関数のpartition byのイメージと似ていて、
group by句で指定されたグループ化のキーごとに区切る赤線になります。

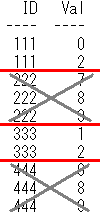
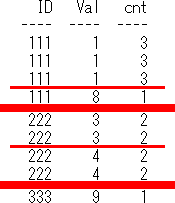
7 having句のイメージ
赤線で区切ったグループに、バツを付けるグレー線
select ID,count(*) as cnt
from AggImage
group by ID
having count(*) != 3
order by ID;
出力結果
ID cnt
--- ---
111 2
333 2
having句のイメージは、where句のイメージと似ていて、
group by句のイメージの赤線で区切ったグループの中で、
having句での論理演算の結果が、Trueではないグループにバツを付けるグレー線になります。
8 distinctオプション
重複を排除して集計
distinctオプションは、主にcount関数で使用されます。
distinctオプションを使うと、重複を排除して集計できます。
create table DistinctSample(ID,Val) as
select 111,2 from dual union all
select 111,2 from dual union all
select 111,7 from dual union all
select 222,3 from dual union all
select 222,4 from dual union all
select 222,6 from dual union all
select 333,8 from dual;
IDごとの、データ件数,重複を排除したValの数を求めてみます。
select ID,count(*) as cnt,
count(distinct Val) as distinctValCnt
from DistinctSample
group by ID
order by ID;
出力結果
ID cnt distinctValCnt
--- --- --------------
111 3 2
222 3 3
333 1 1
9 Keep指定
順位付けしてから、集計対象を限定
Keep指定は、count関数,max関数,min関数,sum関数,avg関数などで使用されます。
Keep指定を使うと、指定したソート条件で(dense_rankな順位で)順位付けしてから、
先頭や最後といった形で、集計対象を限定することができます。
create table KeepSample(ID,SortKey,Val) as
select 111,2,10 from dual union all
select 111,2,20 from dual union all
select 111,3,40 from dual union all
select 111,7,30 from dual union all
select 222,4,90 from dual union all
select 222,6,60 from dual union all
select 222,6,70 from dual union all
select 333,5,90 from dual;
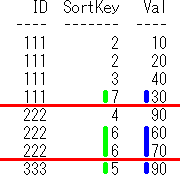
IDごとで、データ件数,SortKeyが最大なデータの件数,
Valの最大値,SortKeyが最大なデータのValの最大値,
Valの合計,SortKeyが最大なデータのValの合計
を求めてみます。
select ID,
count(*) as cnt1,
count(*) Keep(Dense_Rank Last order by SortKey) as cnt2,
max(Val) as maxVal1,
max(Val) Keep(Dense_Rank Last order by SortKey) as maxVal2,
sum(Val) as sumVal1,
sum(Val) Keep(Dense_Rank Last order by SortKey) as sumVal2
from KeepSample
group by ID
order by ID;
出力結果
ID cnt1 cnt2 maxVal1 maxVal2 sumVal1 sumVal2
--- ---- ---- ------- ------- ------- -------
111 4 1 40 30 100 30
222 3 2 90 70 220 130
333 1 1 90 90 90 90
上記のSQLのイメージは下記になります。
group by句に対応する赤線をイメージしてから、Keep指定に対応する黄緑線と青線をイメージしてます。
 ちなみに、上記のSQLと同じ結果を取得できるSQLは、下記となります。
-- 集約関数のKeep指定と同じ結果を取得できるSQL
select ID,
count(*) as cnt1,
count(case rn when 1 then 1 end) as cnt2,
max(Val) as maxVal1,
max(case rn when 1 then Val end) as maxVal2,
sum(Val) as sumVal1,
sum(case rn when 1 then Val end) as sumVal2
from (select ID,Val,
Dense_Rank() over(partition by ID
order by SortKey desc) as rn
from KeepSample)
group by ID
order by ID;
ちなみに、上記のSQLと同じ結果を取得できるSQLは、下記となります。
-- 集約関数のKeep指定と同じ結果を取得できるSQL
select ID,
count(*) as cnt1,
count(case rn when 1 then 1 end) as cnt2,
max(Val) as maxVal1,
max(case rn when 1 then Val end) as maxVal2,
sum(Val) as sumVal1,
sum(case rn when 1 then Val end) as sumVal2
from (select ID,Val,
Dense_Rank() over(partition by ID
order by SortKey desc) as rn
from KeepSample)
group by ID
order by ID;
10 集約関数のネスト
2段階の集約
集約関数は、ネストさせることができます。
集約関数のネストを使えば、2段階の集約を行えます。
create table nestedAggSample(ID,Val) as
select 111,1 from dual union all
select 111,3 from dual union all
select 111,8 from dual union all
select 222,5 from dual union all
select 222,6 from dual union all
select 333,9 from dual;
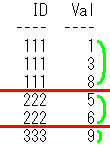
IDごとのデータ件数の最大値,
IDごとのデータ件数の最小値,
IDごとのValの合計の最大値,
IDごとのValの最大値の合計
を求めてみます。
select max(count(*)) as maxCount,
min(count(*)) as minCount,
max(sum(Val)) as maxSumVal,
sum(max(Val)) as sumMaxVal
from nestedAggSample
group by ID;
出力結果
maxCount minCount maxSumVal sumMaxVal
-------- -------- --------- ---------
3 1 12 23
上記のSQLの第1段階のイメージは下記になります。group by句のgroup by IDに対応する赤線をイメージしてます。
 上記のSQLの第2段階のイメージは下記になります。内側の集約関数に対応する黄緑の楕円をイメージしてます。
上記のSQLの第2段階のイメージは下記になります。内側の集約関数に対応する黄緑の楕円をイメージしてます。
11 集約関数と分析関数
集約関数と分析関数の併用
集約関数と分析関数は併用することができます。
create table aggOlapSample(ID,Val) as
select 111,1 from dual union all
select 111,1 from dual union all
select 111,1 from dual union all
select 111,8 from dual union all
select 222,3 from dual union all
select 222,3 from dual union all
select 222,4 from dual union all
select 222,4 from dual union all
select 333,9 from dual;
IDごとのValの最頻値を求めてみます。
最頻値が複数ある場合には、複数の最頻値を出力します。
ちなみに、avgとmedianとstats_modeで扱ったstats_mode関数は、
最頻値が複数ある場合に、複数ある最頻値の中のどれかを返します。
select ID,Val,cnt
from (select ID,Val,count(*) as cnt,
max(count(*)) over(partition by ID) as maxCnt
from aggOlapSample
group by ID,Val)
where cnt=maxCnt
order by ID,Val;
出力結果
ID Val cnt
--- --- ---
111 1 3
222 3 2
222 4 2
333 9 1
上記のSQLのインラインビューでは、分析関数のmax関数の引数に集約関数のcount関数を使用してます。
上記のSQLの第1段階のイメージは下記になります。group by句のgroup by ID,Valに対応する赤線をイメージしてます。
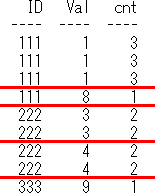 上記のSQLの第2段階のイメージは下記になります。partition by IDに対応する超極太赤線をイメージしてます。
上記のSQLの第2段階のイメージは下記になります。partition by IDに対応する超極太赤線をイメージしてます。
参考リソース