CSVデータの、文字列データでないカンマを検索する。 文字列データは、ダブルコーテーションでくくったデータですが、 \\は文字としての\ \"は文字としてのダブルコーテーション \tはタブ とします(Cのエスケープ方式) 検索前検索後
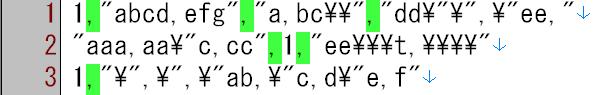
CSVデータの、文字列データでないカンマを検索する。 文字列データは、ダブルコーテーションでくくったデータですが、 \\は文字としての\ \"は文字としてのダブルコーテーション \tはタブ とします(Cのエスケープ方式) 検索前
1,"abcd,efg","a,bc\\","dd\"\",\"ee," "aaa,aa\"c,cc",1,"ee\\\t,\\\\" 1,"\",\",\"ab,\"c,d\"e,f"
,(?=(((((?<=\\)|(?!(\\{2})*")).)*(?<!\\)(?=(\\{2})*").){2})*
(((?<=\\)|(?!(\\{2})*")).)*$)
行末までに、\が偶数個連続した直後の"が
偶数個あれば文字列データでないカンマと考えます。
(?<!\\)(?=(\\{2})*")
の否定はドモルガンの法則を使って
((?<=\\)|(?!(\\{2})*"))
となります。
(?<!\\)(?=(\\{2})*")
は、
"
\\"
\\\\"
などの開始位置マッチします。
いいかえれば、文字データでないダブルコートに1対1で対応した位置にマッチします。