図でイメージするOracleのSQL全集の元原稿
第4回 集約関数など
第2回 集合演算など
第3回 分析関数
連載のテーマ,動作確認環境
前回と同じとなります。
今回のテーマ
今回は、下記のOracleのSQL文の評価順序においての、
9番目のselect句と11番目のorder by句で使用可能な、分析関数の典型的な使用例と、
私のSQLのイメージを解説します。
1番目 from句
2番目 where句 (結合条件)
3番目 start with句
4番目 connect by句
5番目 where句 (行のフィルタ条件)
6番目 group by句
7番目 having句
8番目 model句
9番目 select句
10番目 union、minus、intersectなどの集合演算
11番目 order by句
目次
1 分析関数のメリット
分析関数のメリットは、
Oracle8iまでは、自己結合や相関サブクエリを使ったり、親言語(JavaやVB6など)やPL/SQLで求めていた結果を、
SQLで容易に求めることができるようになることです。
帳票作成やデータ分析で特に使います。
さらに、分析関数のメリットについて
Tom Kyteさんの記事、Oracle Database 11g Release 2に関する10の重要なことから引用しておきます。
「分析関数は、SQLにSELECTというキーワードが加わって以来のすばらしい出来事だ」
分析関数はSQLでは、かつては実現できなかったことを可能にしてくれます。
分析関数によって、SQLはプロシージャ言語のようなものに変わり、前の行や次の行へのアクセスが可能となるのです。
これは、もともとのSQLにはなかった発想です。
2 分析関数の使用頻度
使用頻度の高いものからおさえていくと学習効率が高いです。
最頻出
count max min sum Row_Number
頻出
Lag Lead Rank dense_rank
たまに
avg First_Value Last_Value nth_Value ListAgg wmsys.wm_concat
レア
Ratio_To_Report median NTile regr_count
3 count(*) over()
select文の件数取得
count(*) over()は、select文の結果の行数を列に持たせたい時に使います。
create table CountSample(Val) as
select 10 from dual union all
select 20 from dual union all
select 20 from dual union all
select 30 from dual union all
select 30 from dual;
-- count(*) over()を使ったSQL
select Val,count(*) over() as recordCount
from CountSample;
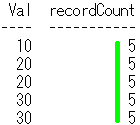
出力結果
Val recordCount
--- -----------
10 5
20 5
20 5
30 5
30 5
select文の結果の行数である5がrecordCount列の値になってますね。
SQLのイメージは下記です。count(*) over()で黄緑線を引いてます。
 distinct指定のあるselect文の件数を取得する場合は、
下記のようにインラインビューを使うといいでしょう。
(select句の評価順序において、分析関数の評価後に、distinctによる重複排除があるため)
-- distinct指定のあるselect文の件数取得
select Val,count(*) over() as recordCount
from (select distinct Val
from CountSample)
order by Val;
出力結果
Val recordCount
--- -----------
10 3
20 3
30 3
distinct指定のあるselect文の件数を取得する場合は、
下記のようにインラインビューを使うといいでしょう。
(select句の評価順序において、分析関数の評価後に、distinctによる重複排除があるため)
-- distinct指定のあるselect文の件数取得
select Val,count(*) over() as recordCount
from (select distinct Val
from CountSample)
order by Val;
出力結果
Val recordCount
--- -----------
10 3
20 3
30 3
4 count(*) over() と minus
2つのselect文の結果が一致するかの確認
テーブル定義が同じテーブル同士や、select文の結果同士のデータが一致するかの確認に、
count(*) over() と minus集合演算を組み合わせたSQLが使えます。
create table cmpA(ID number,Val number);
create table cmpB(ID number,Val number);
-- case1 (cmpAとcmpBが一致)
truncate table cmpA;
truncate table cmpB;
insert into cmpA values(10,111);
insert into cmpA values(20,222);
insert into cmpB values(10,111);
insert into cmpB values(20,222);
-- case2 (cmpAとcmpBが不一致)
truncate table cmpA;
truncate table cmpB;
insert into cmpA values(10,111);
insert into cmpB values(10,111);
insert into cmpB values(20,222);
-- cmpAとcmpBのデータが一致するか調べる
select a.*,count(*) over() from cmpA a
minus
select a.*,count(*) over() from cmpB a;
上記のselect文の結果が0件になるのは、以下の少なくとも1つが成り立つ場合です。
・cmpAが空集合(レコードが0件)
・cmpAとcmpBのデータが(重複行があれば重複を排除してから)比較して一致する
実際の業務において、空集合や重複行があるということは、まずないので
上記のselect文の結果が0件なら、cmpAとcmpBのデータが同じと判定できます。
5 max(Val) over(partition by PID)
指定した値で区切った中での最大値を取得
max(Val) over(partition by PID)は、
指定した値で区切った(パーティションを切った)中での最大値を取得する時に使います。
create table MaxPIDSample(ID,Val) as
select 111,10 from dual union all
select 111,30 from dual union all
select 111,40 from dual union all
select 222,20 from dual union all
select 333,60 from dual union all
select 333,60 from dual;
IDごとのValの最大値を求めてみます。
select ID,Val,
max(Val) over(partition by ID) as maxVal
from MaxPIDSample;
出力結果
ID Val maxVal
--- --- ------
111 10 40
111 30 40
111 40 40
222 20 20
333 60 60
333 60 60
SQLのイメージは下記です。partition by IDで、IDごとに区切る赤線を引いて、
max関数で青線と黄緑線を引いてます。
 max関数の他に、min関数やsum関数やcount関数などでも同じような使い方ができます。
max関数の他に、min関数やsum関数やcount関数などでも同じような使い方ができます。
6 count(distinct Val) over(partition by PID)
列値が何通りあるかを調べる
distinctオプションを指定した分析関数のcount関数は、列値が何通りあるかを調べる時などに使われます。
create table CntDisSample(ID,Val) as
select 111,1 from dual union all
select 111,1 from dual union all
select 111,2 from dual union all
select 222,4 from dual union all
select 222,5 from dual union all
select 222,6 from dual union all
select 333,7 from dual union all
select 333,7 from dual;
IDごとにValが何通りあるかを調べてみます。
select ID,Val,
count(distinct Val) over(partition by ID) as disCnt
from CntDisSample;
出力結果
ID Val disCnt
--- --- ------
111 1 2
111 1 2
111 2 2
222 4 3
222 5 3
222 6 3
333 7 1
333 7 1
SQLのイメージは下記です。partition by IDで、IDごとに区切る赤線を引いて、
count関数で黄緑線を引いてます。

7 Row_Numberとrankとdense_rank
順位や連番を求める
順位や連番を求めるのに使うのが、Row_Number関数とrank関数とdense_rank関数です。
create table RankingSample(ID,Score) as
select 1,100 from dual union all
select 1, 90 from dual union all
select 1, 90 from dual union all
select 1, 80 from dual union all
select 1, 70 from dual union all
select 2,100 from dual union all
select 2,100 from dual union all
select 2,100 from dual union all
select 2, 90 from dual union all
select 2, 80 from dual;
select ID,Score,
Row_Number() over(partition by ID order by Score desc) as "Row_Number",
rank() over(partition by ID order by Score desc) as "rank",
dense_rank() over(partition by ID order by Score desc) as "dense_rank"
from RankingSample
order by ID,Score desc;
出力結果
ID Score Row_Number rank dense_rank
-- ----- ---------- ---- ----------
1 100 1 1 1
1 90 2 2 2
1 90 3 2 2
1 80 4 4 3
1 70 5 5 4
2 100 1 1 1
2 100 2 1 1
2 100 3 1 1
2 90 4 4 2
2 80 5 5 3
Row_Number関数は、1から始まって、必ず連番になります。
rank関数は、同点があると順位が飛びます。
dense_rank関数は、同点があっても順位が飛びません。denseは、形容詞で密集したという意味です。
SQLのイメージは下記です。partition by IDで、IDごとに区切る赤線を引いて、
Row_Number関数,rank関数,dense_rank関数で青線と黄緑線を引いてます。

8 LagとLead
指定したソートキーでの、前後の行の値を取得
指定したソートキーでの、
前の行の値が欲しい時に使うのが、Lag関数で、
後の行の値が欲しい時に使うのが、Lead関数です。
create table LagLeadSample(ID,SortKey,Val) as
select 111,1,99 from dual union all
select 111,3,88 from dual union all
select 111,7,77 from dual union all
select 111,9,66 from dual union all
select 222,2,55 from dual union all
select 222,4,44 from dual union all
select 222,5,33 from dual;
IDごとにSortKeyの昇順で、
前の行のValをPrev列として求め、
後の行のValをNext列として求めてみます。
select ID,SortKey,
Lag(Val) over(partition by ID order by SortKey) as Prev,
Val,
Lead(Val) over(partition by ID order by SortKey) as Next
from LagLeadSample
order by ID,SortKey;
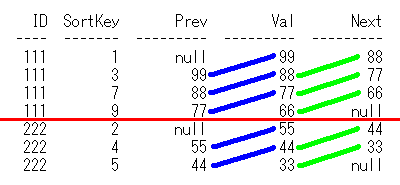
出力結果
ID SortKey Prev Val Next
--- ------- ---- --- ----
111 1 null 99 88
111 3 99 88 77
111 7 88 77 66
111 9 77 66 null
222 2 null 55 44
222 4 55 44 33
222 5 44 33 null
SQLのイメージは下記です。partition by IDで、IDごとに区切る赤線を引いて、
Lag関数で青線、Lead関数で黄緑線を引いてます。
9 sum(Val) over(order by SortKey)
累計を求める
累計を求める時に使われるのが、order byを指定した分析関数のsum関数です。
create table RunSumSample(ID,SortKey,Val) as
select 111,1, 1 from dual union all
select 111,3, 2 from dual union all
select 111,5, 6 from dual union all
select 222,1,10 from dual union all
select 222,2,20 from dual union all
select 222,3,60 from dual union all
select 222,4, 6 from dual union all
select 333,1, 1 from dual union all
select 333,2, 2 from dual union all
select 333,3,20 from dual union all
select 333,3,30 from dual;
IDごとに、SortKeyの昇順でValの累計を求めてみます。
select ID,SortKey,Val,
sum(Val) over(partition by ID order by SortKey) as runSum
from RunSumSample;
出力結果
ID SortKey Val runSum
--- ------- --- ------
111 1 1 1
111 3 2 3
111 5 6 9
222 1 10 10
222 2 20 30
222 3 60 90
222 4 6 96
333 1 1 1
333 2 2 3
333 3 20 53
333 3 30 53
SQLのイメージは下記です。partition by IDで、IDごとに区切る赤線を引いて、
sum(Val) over(partition by ID order by SortKey)で黄緑線を引いてます。

10 First_ValueとLast_Valueとnth_Value
指定したソートキーでの、最初や最後やn番目の行の値を求める
指定したソートキーでの、最初の行の値を求めるのが、First_Value関数。
指定したソートキーでの、最後の行の値を求めるのが、Last_Value関数。
指定したソートキーでの、(Row_Numberな順位が)n番目の行の値を求めるのが、nth_Value関数となります。
Oracle11gR2でnth_Value関数が追加されました。
create table FirstLastSample(ID,SortKey,Val) as
select 111,1,20 from dual union all
select 111,3,60 from dual union all
select 111,9,40 from dual union all
select 222,2,90 from dual union all
select 222,4,70 from dual union all
select 333,5,80 from dual;
IDごとでSortKeyの昇順で、最初の行のValと最後の行のValを求めてみます。
select ID,SortKey,
First_Value(Val)
over(partition by ID order by SortKey) as FirVal,
Val,
Last_Value(Val)
over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as LastVal
from FirstLastSample;
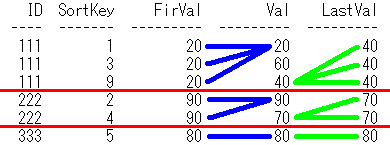
出力結果
ID SortKey FirVal Val LastVal
--- ------- ------ --- -------
111 1 20 20 40
111 3 20 60 40
111 9 20 40 40
222 2 90 90 70
222 4 90 70 70
333 5 80 80 80
SQLのイメージは下記です。partition by IDで、IDごとに区切る赤線を引いて、
First_Value関数で青線、Last_Value関数で黄緑線を引いてます。
11 First_ValueとLast_Valueのignore nulls
ある条件を満たす、最初や最後の行の値を求める
Oracle10gR1から、First_Value関数とLast_Value関数で、ignore nullsを指定できます。
Oracle11gR2からは、Lag関数とLead関数でもignore nullsを指定できます。
Last_Value(値 ignore nulls) over句 が基本的な使い方ですが、
Last_Value(case when 条件 then 値 end ignore nulls) over句 というふうに、
case式を組み合わせて使うほうが多いです。
create table IgnoreNullsSample1(ID,SortKey,Val) as
select 555,1, 600 from dual union all
select 555,3, 300 from dual union all
select 555,5,null from dual union all
select 555,9,null from dual union all
select 666,2, 400 from dual union all
select 666,3,null from dual union all
select 666,4,null from dual union all
select 666,5, 600 from dual union all
select 777,1,null from dual union all
select 777,3,null from dual union all
select 777,5, 900 from dual union all
select 777,6,null from dual;
IDごとでSortKeyの昇順で、最初のnullでないValと、最後のnullでないValを求めてみます。
select ID,SortKey,
First_Value(Val ignore nulls)
over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as FirVal,
Val,
Last_Value(Val ignore nulls)
over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as LastVal
from IgnoreNullsSample1;
出力結果
ID SortKey FirVal Val LastVal
--- ------- ------ ---- -------
555 1 600 600 300
555 3 600 300 300
555 5 600 null 300
555 9 600 null 300
666 2 400 400 600
666 3 400 null 600
666 4 400 null 600
666 5 400 600 600
777 1 900 null 900
777 3 900 null 900
777 5 900 900 900
777 6 900 null 900
SQLのイメージは下記です。partition by IDで、IDごとに区切る赤線を引いて、
First_Value関数で青線、Last_Value関数で黄緑線を引いてます。
 ignore nullsの、別の使い方として、
その行以降で最初のnullでないValや、
その行までで最後のnullでないValを求めるといった使い方もあります。
create table IgnoreNullsSample2(SortKey,Val) as
select 1,null from dual union all
select 2, 500 from dual union all
select 3,null from dual union all
select 5,null from dual union all
select 6, 300 from dual union all
select 10,null from dual union all
select 11,null from dual union all
select 12, 700 from dual union all
select 13,null from dual;
select SortKey,
First_Value(Val ignore nulls)
over(order by SortKey
Rows between current row
and Unbounded Following) as FirVal,
Val,
Last_Value(Val ignore nulls)
over(order by SortKey) as LastVal
from IgnoreNullsSample2;
出力結果
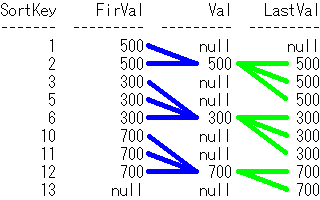
SortKey FirVal Val LastVal
------- ------ ---- -------
1 500 null null
2 500 500 500
3 300 null 500
5 300 null 500
6 300 300 300
10 700 null 300
11 700 null 300
12 700 700 700
13 null null 700
SQLのイメージは下記です。First_Value関数で青線、Last_Value関数で黄緑線を引いてます。
ignore nullsの、別の使い方として、
その行以降で最初のnullでないValや、
その行までで最後のnullでないValを求めるといった使い方もあります。
create table IgnoreNullsSample2(SortKey,Val) as
select 1,null from dual union all
select 2, 500 from dual union all
select 3,null from dual union all
select 5,null from dual union all
select 6, 300 from dual union all
select 10,null from dual union all
select 11,null from dual union all
select 12, 700 from dual union all
select 13,null from dual;
select SortKey,
First_Value(Val ignore nulls)
over(order by SortKey
Rows between current row
and Unbounded Following) as FirVal,
Val,
Last_Value(Val ignore nulls)
over(order by SortKey) as LastVal
from IgnoreNullsSample2;
出力結果
SortKey FirVal Val LastVal
------- ------ ---- -------
1 500 null null
2 500 500 500
3 300 null 500
5 300 null 500
6 300 300 300
10 700 null 300
11 700 null 300
12 700 700 700
13 null null 700
SQLのイメージは下記です。First_Value関数で青線、Last_Value関数で黄緑線を引いてます。
12 Rows 2 Preceding
移動累計を求める (行数を指定)
Rows 2 Precedingといった指定は、移動平均や移動累計を求める時などに使われます。
create table MoveSumSample(SortKey,Val) as
select 1, 10 from dual union all
select 2, 20 from dual union all
select 5, 60 from dual union all
select 7,100 from dual union all
select 8,200 from dual union all
select 9,600 from dual;
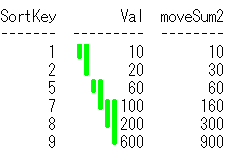
SortKeyの昇順での、前の2行と自分の行を加算対象とした移動累計を求めてみます。
select SortKey,Val,
sum(Val) over(order by SortKey Rows 2 Preceding) as moveSum
from MoveSumSample;
出力結果
SortKey Val moveSum
------- --- -------
1 10 10
2 20 30
5 60 90
7 100 180
8 200 360
9 600 900
SQLのイメージは下記です。sum(Val) over(order by SortKey Rows 2 Preceding)で黄緑線を引いてます。

13 Range 2 Preceding
移動累計を求める (ソートキーの範囲を指定)
Range 2 Precedingといった指定は、移動平均や移動累計を求める時などに、使われます。
Rows 2 Precedingとの違いは、Rowsが行数の指定なのに対して、Rangeはソートキーの範囲の指定という点です。
SortKeyが自分の行より2小さい行から、自分の行までを加算対象とした移動累計を求めてみます。
select SortKey,Val,
sum(Val) over(order by SortKey Range 2 Preceding) as moveSum2
from MoveSumSample;
出力結果
SortKey Val moveSum2
------- --- --------
1 10 10
2 20 30
5 60 60
7 100 160
8 200 300
9 600 900
SQLのイメージは下記です。sum(Val) over(order by SortKey Range 2 Preceding)で黄緑線を引いてます。
14 全称肯定,全称否定,存在肯定,存在否定
複数行にまたがった条件のチェック
・全ての行が条件を満たすか?
・全ての行が条件を満たさないか?
・少なくとも1行が条件を満たすか?
・少なくとも1行が条件を満たさないか?
といった複数行にまたがったチェックをしたい時には、
分析関数のmin関数やmax関数と、case式を組み合わせると有効です。
create table BoolSample(ID,Val) as
select 111,3 from dual union all
select 111,3 from dual union all
select 111,3 from dual union all
select 222,3 from dual union all
select 222,1 from dual union all
select 333,0 from dual union all
select 333,4 from dual;
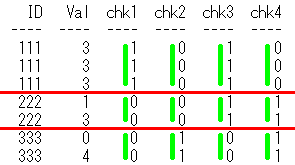
・check1 IDごとで、全ての行が Val=3 を満たすか?
・check2 IDごとで、全ての行が Val=3 を満たさないか?
・check3 IDごとで、少なくとも1つの行が Val=3 を満たすか?
・check4 IDごとで、少なくとも1つの行が Val=3 を満たさないか?
をチェックしてみます。
select ID,Val,
min(case when Val=3 then 1 else 0 end) over(partition by ID) as chk1,
min(case when Val=3 then 0 else 1 end) over(partition by ID) as chk2,
max(case when Val=3 then 1 else 0 end) over(partition by ID) as chk3,
max(case when Val=3 then 0 else 1 end) over(partition by ID) as chk4
from BoolSample
order by ID,Val;
出力結果
ID Val chk1 chk2 chk3 chk4
--- --- ---- ---- ---- ----
111 3 1 0 1 0
111 3 1 0 1 0
111 3 1 0 1 0
222 1 0 0 1 1
222 3 0 0 1 1
333 0 0 1 0 1
333 4 0 1 0 1
SQLのイメージは下記です。partition by IDで、IDごとに区切る赤線を引いて、
min関数とmax関数で黄緑線を引いてます。
 ちなみに、IDごとで、少なくとも1つの行が Val=0を満たし、
かつ、少なくとも1つの行が Val=4を満たかをチェックするSQLは、下記となります。
掛け算で論理積を代用しています。
select ID,Val,
max(case when Val=0 then 1 else 0 end) over(partition by ID)
*max(case when Val=4 then 1 else 0 end) over(partition by ID) as chk
from BoolSample
order by ID,Val;
出力結果
ID Val chk
--- --- ---
111 3 0
111 3 0
111 3 0
222 1 0
222 3 0
333 0 1
333 4 1
参考リソース
SQLアタマアカデミー:第8回 SQLにおける論理演算
OracleSQLパズル 9-22 存在有無のブール値で論理演算
ちなみに、IDごとで、少なくとも1つの行が Val=0を満たし、
かつ、少なくとも1つの行が Val=4を満たかをチェックするSQLは、下記となります。
掛け算で論理積を代用しています。
select ID,Val,
max(case when Val=0 then 1 else 0 end) over(partition by ID)
*max(case when Val=4 then 1 else 0 end) over(partition by ID) as chk
from BoolSample
order by ID,Val;
出力結果
ID Val chk
--- --- ---
111 3 0
111 3 0
111 3 0
222 1 0
222 3 0
333 0 1
333 4 1
参考リソース
SQLアタマアカデミー:第8回 SQLにおける論理演算
OracleSQLパズル 9-22 存在有無のブール値で論理演算
15 ListAggとwmsys.wm_concat
文字列を連結してまとめる
MySQLのGroup_Concat関数のように文字列を連結する機能として、ListAgg関数やwmsys.wm_concat関数があります。
wmsys.wm_concat関数は、Oracle11gR2の段階でマニュアルに記載されていないので、注意して使う必要があります。
wmsys.wm_concat関数と似たような機能を持つListAgg関数は、Oracle11gR2で追加された関数です。
create table strAggSample(ID,Val) as
select 111,'a' from dual union all
select 111,'b' from dual union all
select 111,'c' from dual union all
select 222,'d' from dual union all
select 222,'e' from dual union all
select 222,'f' from dual;
select ID,Val,
wmsys.wm_concat(Val) over(partition by ID order by Val desc) as strAgg1,
wmsys.wm_concat(Val) over(order by Val) as strAgg2,
ListAgg(Val,',') withIn group(order by Val) over() as strAgg3,
ListAgg(Val,',') withIn group(order by Val) over(partition by ID) as strAgg4
from strAggSample
order by ID,Val;
出力結果
ID Val strAgg1 strAgg2 strAgg3 strAgg4
--- --- ------- ----------- ----------- -------
111 a c,b,a a a,b,c,d,e,f a,b,c
111 b c,b a,b a,b,c,d,e,f a,b,c
111 c c a,b,c a,b,c,d,e,f a,b,c
222 d f,e,d a,b,c,d a,b,c,d,e,f d,e,f
222 e f,e a,b,c,d,e a,b,c,d,e,f d,e,f
222 f f a,b,c,d,e,f a,b,c,d,e,f d,e,f
16 Range指定でInterVal型の使用
InterVal型で、ソートキーの範囲を指定
13. Range 2 Precedingで扱ったように、
分析関数でのRange指定はソートキーの範囲を指定するのに使いますが、
ソートキーがDate型やTimeStamp型であれば、InterVal型を使ってソートキーの範囲を指定できます。
create table dateRangeSample(dayCol) as
select to_date('2010-11-01 10:10','YYYY-MM-DD HH24:MI') from dual union
select to_date('2010-11-01 10:14','YYYY-MM-DD HH24:MI') from dual union
select to_date('2010-11-01 10:17','YYYY-MM-DD HH24:MI') from dual union
select to_date('2010-11-01 10:19','YYYY-MM-DD HH24:MI') from dual union
select to_date('2010-11-01 10:20','YYYY-MM-DD HH24:MI') from dual union
select to_date('2010-11-01 10:26','YYYY-MM-DD HH24:MI') from dual union
select to_date('2010-11-01 10:30','YYYY-MM-DD HH24:MI') from dual;
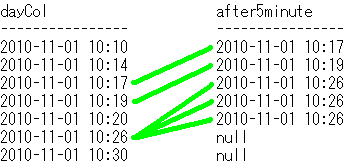
行ごとに、5分後以降で最小のdayColを求めます。
select dayCol,
min(dayCol)
over(order by dayCol
range between InterVal '5' minute Following
and UnBounded Following) as after5minute
from dateRangeSample;
出力結果
dayCol after5minute
---------------- ----------------
2010-11-01 10:10 2010-11-01 10:17
2010-11-01 10:14 2010-11-01 10:19
2010-11-01 10:17 2010-11-01 10:26
2010-11-01 10:19 2010-11-01 10:26
2010-11-01 10:20 2010-11-01 10:26
2010-11-01 10:26 null
2010-11-01 10:30 null
SQLのイメージは下記です。min関数で黄緑線を引いてます。
参考リソース