CodeZineのMySQLの記事(シーズン2)の元原稿
第2回 再帰With句のサンプル集
第1回 MySQL8.0のWindow関数のサンプル集
今回のテーマ
MySQL8.0の新機能であるWindow関数について、
前半は、学習効率が高いと思われる順序で、Window関数の各機能をイメージを交えて解説します。
後半は、PostgreSQLとOracleのWindow関数の機能をMySQL8.0で模倣する方法を解説します。
動作確認環境
MySQL 8.0.15
目次
01. Window関数とは
select句とorder by句で使うことができます。order by句で使うことは、ほとんどないです。
なお、再帰With句の再帰項のSelect句では、Window関数は、使用不可です。
また、Update文とDelete文のorder by句でも、Window関数は、使用不可です。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
Window関数のメリット
自己結合や相関サブクエリを使ったり、
親言語(PHPやRubyなど)やストアドプロシージャで、求めていた結果を、
SQLで容易に求めることができるようになります。
帳票作成やデータ分析で特に使います。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
MySQL8.0のWindow関数の使用頻度
最頻出 count max min sum Row_Number
頻出 Lag Lead Rank dense_rank
たまに avg First_Value Last_Value nth_Value JSON_ArrayAgg
レア NTile
02. Select文の件数取得
Select文の結果の件数が欲しいといったことは、結構あります。
そんな時に使うのが、Window関数のcount関数です。
create table CountT(ID int,Val int);
insert into CountT values(1,10),
(1,20),
(2,10),
(2,30),
(2,50);
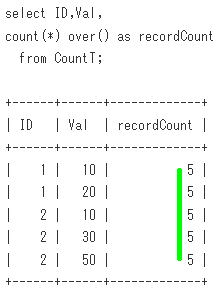
-- Sample01
select ID,Val,
count(*) over() as recordCount
from CountT;
出力結果
+------+------+-------------+
| ID | Val | recordCount |
+------+------+-------------+
| 1 | 10 | 5 |
| 1 | 20 | 5 |
| 2 | 10 | 5 |
| 2 | 30 | 5 |
| 2 | 50 | 5 |
+------+------+-------------+
-- Sample01のサブクエリを使った代替方法
select ID,Val,
(select count(*) from CountT) as recordCount
from CountT;
脳内のイメージは、このようになります。
 where句や、group by句や、having句があっても、select文の結果の件数が求まります。
-- Sample02
select ID,Val,
count(*) over() as recordCount
from CountT
where Val in(10,20);
-- Sample03
select ID,max(Val) as maxVal,
count(*) over() as recordCount
from CountT
group by ID
having max(Val) = 20;
distinct指定、もしくは、Limit句があるselect文の結果の件数を求めるには、インラインビューを使えばいいです。
MySQLのselect文は、下記の順序で動作するからです。
1 from句
2 where句
3 group by句
4 having句
5 select句
6 order by句
7 distinct
8 Limit句
create table disT(ColA int,ColB int);
insert into disT values(1,null),
(1, 3),
(1, 3),
(2,null),
(2,null);
-- Sample04
select ColA,ColB,count(*) over() as recordCount
from (select distinct ColA,ColB
from disT
order by ColA,ColB Limit 2) tmp
order by ColA,ColB;
where句や、group by句や、having句があっても、select文の結果の件数が求まります。
-- Sample02
select ID,Val,
count(*) over() as recordCount
from CountT
where Val in(10,20);
-- Sample03
select ID,max(Val) as maxVal,
count(*) over() as recordCount
from CountT
group by ID
having max(Val) = 20;
distinct指定、もしくは、Limit句があるselect文の結果の件数を求めるには、インラインビューを使えばいいです。
MySQLのselect文は、下記の順序で動作するからです。
1 from句
2 where句
3 group by句
4 having句
5 select句
6 order by句
7 distinct
8 Limit句
create table disT(ColA int,ColB int);
insert into disT values(1,null),
(1, 3),
(1, 3),
(2,null),
(2,null);
-- Sample04
select ColA,ColB,count(*) over() as recordCount
from (select distinct ColA,ColB
from disT
order by ColA,ColB Limit 2) tmp
order by ColA,ColB;
03. 最大値の行の取得
IDごとに、Valが最大値の行を取得します。
create table MaxT(ID int,Val int,extraCol char(1));
insert into MaxT values(1,10,'A'),
(1,20,'B'),
(2,10,'C'),
(2,30,'D'),
(2,50,'E'),
(3,70,'F'),
(3,70,'G');
-- 単純に、IDごとのValの最大値が欲しいなら、これで可
select ID,max(Val)
from MaxT
group by ID;
-- Sample05
select ID,Val,extraCol
from (select ID,Val,extraCol,
max(Val) over(partition by ID) as maxVal
from MaxT) tmp
where Val = maxVal;
出力結果
+------+------+----------+
| ID | Val | extraCol |
+------+------+----------+
| 1 | 20 | B |
| 2 | 50 | E |
| 3 | 70 | F |
| 3 | 70 | G |
+------+------+----------+
-- Sample05の相関サブクエリを使った代替方法
select ID,Val,extraCol
from MaxT a
where Val = (select max(b.Val)
from MaxT b
where b.ID = a.ID);
Window関数が使えるのは、select句かorder by句です。なので、
Window関数の結果をwhere句で使うには、インラインビューを使う必要があります。
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。

04. 順位を付ける
順位や連番を付けたい時に使うのが、Window関数のRow_Number関数,rank関数,dense_rank関数です。
create table rnT(ID int,score int);
insert into rnT values(1,100),
(1,100),
(1, 90),
(1, 80),
(2,100),
(2, 70),
(2, 70);
-- Sample06
select ID,score,
Row_Number() over(partition by ID order by score desc) as "Row_Number",
rank() over(partition by ID order by score desc) as "rank",
dense_rank() over(partition by ID order by score desc) as "dense_rank"
from rnT
order by ID,score desc;
出力結果
+------+-------+------------+------+------------+
| ID | score | Row_Number | rank | dense_rank |
+------+-------+------------+------+------------+
| 1 | 100 | 1 | 1 | 1 |
| 1 | 100 | 2 | 1 | 1 |
| 1 | 90 | 3 | 3 | 2 |
| 1 | 80 | 4 | 4 | 3 |
| 2 | 100 | 1 | 1 | 1 |
| 2 | 70 | 2 | 2 | 2 |
| 2 | 70 | 3 | 2 | 2 |
+------+-------+------------+------+------------+
Row_Number関数は、1から始まって、必ず連番になります。
rank関数は、同点があると順位が飛びます。
dense_rank関数は、同点があっても順位が飛びません。
denseは、形容詞で、密集したという意味です。
-- Sample06の相関サブクエリを使った代替方法 (Row_Number関数以外)
select ID,score,
(select count(*)+1 from rnT b
where b.ID = a.ID and b.score > a.score) as "rank",
(select count(distinct b.score)+1 from rnT b
where b.ID = a.ID and b.score > a.score) as "dense_rank"
from rnT a
order by ID,"rank";
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。

05. 最大値の行の取得(ソートキーが複数)
「03 最大値の行の取得」では、ソートキーが1つだったので、Window関数のmax関数を使いましたが、
ソートキーが複数だと、順位を付ける関数を使う必要があります。
create table multiSortKeyT(ID int,SortKey1 int,SortKey2 int,extraCol char(3));
insert into multiSortKeyT values(1,10, 2,'AAA'),
(1,10, 3,'BBB'),
(1,30, 1,'CCC'),
(2,20, 1,'DDD'),
(2,50, 2,'EEE'),
(2,50, 2,'FFF'),
(3,60, 1,'GGG'),
(3,60, 2,'HHH'),
(3,60, 3,'III'),
(4,10,20,'JJJ');
-- Sample07
select ID,SortKey1,SortKey2,extraCol
from (select ID,SortKey1,SortKey2,extraCol,
rank() over(partition by ID order by SortKey1 desc,SortKey2 desc) as rn
from multiSortKeyT) a
where rn = 1
order by ID,extraCol;
出力結果
+------+----------+----------+----------+
| ID | SortKey1 | SortKey2 | extraCol |
+------+----------+----------+----------+
| 1 | 30 | 1 | CCC |
| 2 | 50 | 2 | EEE |
| 2 | 50 | 2 | FFF |
| 3 | 60 | 3 | III |
| 4 | 10 | 20 | JJJ |
+------+----------+----------+----------+
-- Sample07の相関サブクエリを使った代替方法1
select ID,SortKey1,SortKey2,extraCol
from multiSortKeyT a
where (SortKey1,SortKey2) = (select b.SortKey1,b.SortKey2
from multiSortKeyT b
where b.ID = a.ID
order by b.SortKey1 desc,b.SortKey2 desc Limit 1)
order by ID,extraCol;
-- Sample07の相関サブクエリを使った代替方法2
select ID,SortKey1,SortKey2,extraCol
from multiSortKeyT a
where not exists(select 1 from multiSortKeyT b
where b.ID = a.ID
and (b.SortKey1 > a.SortKey1
or b.SortKey1 = a.SortKey1 and b.SortKey2 > a.SortKey2))
order by ID,extraCol;
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。

06. 前後の行の値
指定したソートキーでの、
前の行の値が欲しい時に使われるのが、Lag関数で、
後の行の値が欲しい時に使われるのが、Lead関数です。
create table LagLeadT(ID char(2),SortKey int,Val int);
insert into LagLeadT values('AA',1,10),
('AA',3,20),
('AA',5,60),
('AA',7,30),
('BB',2,40),
('BB',4,80),
('BB',6,50);
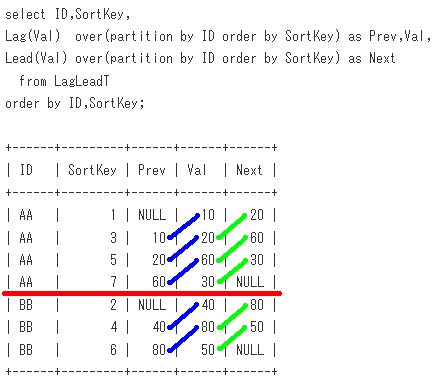
-- Sample08
select ID,SortKey,
Lag(Val) over(partition by ID order by SortKey) as Prev,Val,
Lead(Val) over(partition by ID order by SortKey) as Next
from LagLeadT
order by ID,SortKey;
出力結果
+------+---------+------+------+------+
| ID | SortKey | Prev | Val | Next |
+------+---------+------+------+------+
| AA | 1 | NULL | 10 | 20 |
| AA | 3 | 10 | 20 | 60 |
| AA | 5 | 20 | 60 | 30 |
| AA | 7 | 60 | 30 | NULL |
| BB | 2 | NULL | 40 | 80 |
| BB | 4 | 40 | 80 | 50 |
| BB | 6 | 80 | 50 | NULL |
+------+---------+------+------+------+
-- Sample08の相関サブクエリを使った代替方法
select ID,SortKey,
(select b.Val from LagLeadT b
where b.ID = a.ID and b.SortKey < a.SortKey
order by b.SortKey desc Limit 1) as Prev,
Val,
(select b.Val from LagLeadT b
where b.ID = a.ID and b.SortKey > a.SortKey
order by b.SortKey Limit 1) as Next
from LagLeadT a
order by ID,SortKey;
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。
 Lag関数とLead関数は、キーブレイクの事前検知にも使えます。
ID列,SortKey列をソートキー、ID列をブレークキーとして、 キーブレイクを検知してみます。
case式を使うのが定番ですが、これは、case式を使わなくていいパターンです。
-- case式を使う定番の方法
select ID,SortKey,Val,
case when ID = Lag(ID) over(order by ID,SortKey) then 0 else 1 end as IsKeyBreaked,
case when ID = Lead(ID) over(order by ID,SortKey) then 0 else 1 end as WillKeyBreak
from LagLeadT
order by ID,SortKey;
-- Sample09
select ID,SortKey,Val,
Lag (0,1,1) over(partition by ID order by SortKey) as IsKeyBreaked,
Lead(0,1,1) over(partition by ID order by SortKey) as WillKeyBreak
from LagLeadT
order by ID,SortKey;
Lag関数とLead関数は、キーブレイクの事前検知にも使えます。
ID列,SortKey列をソートキー、ID列をブレークキーとして、 キーブレイクを検知してみます。
case式を使うのが定番ですが、これは、case式を使わなくていいパターンです。
-- case式を使う定番の方法
select ID,SortKey,Val,
case when ID = Lag(ID) over(order by ID,SortKey) then 0 else 1 end as IsKeyBreaked,
case when ID = Lead(ID) over(order by ID,SortKey) then 0 else 1 end as WillKeyBreak
from LagLeadT
order by ID,SortKey;
-- Sample09
select ID,SortKey,Val,
Lag (0,1,1) over(partition by ID order by SortKey) as IsKeyBreaked,
Lead(0,1,1) over(partition by ID order by SortKey) as WillKeyBreak
from LagLeadT
order by ID,SortKey;
07. 累計
帳票で累計を求めたい時に使うのが、order byを指定した、Window関数のsum関数です。
create table runSumT(ID char(2),SortKey int,Val int);
insert into runSumT values('AA',1,10),
('AA',2,20),
('AA',3,40),
('AA',4,80),
('BB',1,10),
('BB',2,30),
('BB',3,90),
('CC',1,50),
('CC',2,60),
('CC',2,60);
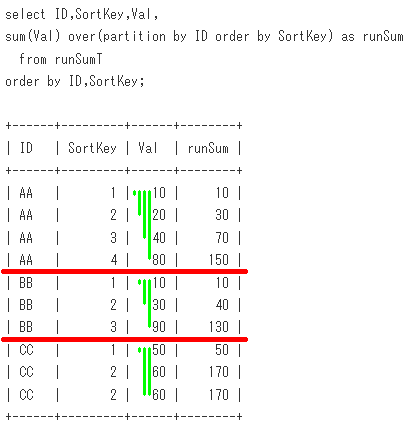
-- Sample10
select ID,SortKey,Val,
sum(Val) over(partition by ID order by SortKey) as runSum
from runSumT
order by ID,SortKey;
出力結果
+------+---------+------+--------+
| ID | SortKey | Val | runSum |
+------+---------+------+--------+
| AA | 1 | 10 | 10 |
| AA | 2 | 20 | 30 |
| AA | 3 | 40 | 70 |
| AA | 4 | 80 | 150 |
| BB | 1 | 10 | 10 |
| BB | 2 | 30 | 40 |
| BB | 3 | 90 | 130 |
| CC | 1 | 50 | 50 |
| CC | 2 | 60 | 170 |
| CC | 2 | 60 | 170 |
+------+---------+------+--------+
-- Sample10の相関サブクエリを使った代替方法
select ID,SortKey,Val,
(select sum(b.Val) from runSumT b
where b.ID = a.ID and b.SortKey <= a.SortKey) as runSum
from runSumT a
order by ID,SortKey;
order byを指定して、frame句を省略すると、
デフォルトの、Range Between Unbounded Preceding and Current rowになります。
frame句は、下記のように解釈すると分かりやすいです。
order by SortKey -- SortKeyの昇順で、
Range Between -- 値の範囲は、
Unbounded Preceding -- 前方は、際限なく、
and Current row -- 後方は、カレント行まで
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。
08. 移動累計
3日移動累計を求めてみます。
create table idouT(DayCol date,Val int);
insert into idouT values(date '2019-05-11', 10),
(date '2019-05-12', 20),
(date '2019-05-15', 60),
(date '2019-05-16', 100),
(date '2019-05-17', 200),
(date '2019-05-18', 600),
(date '2019-05-19',1000),
(date '2019-05-25',2000);
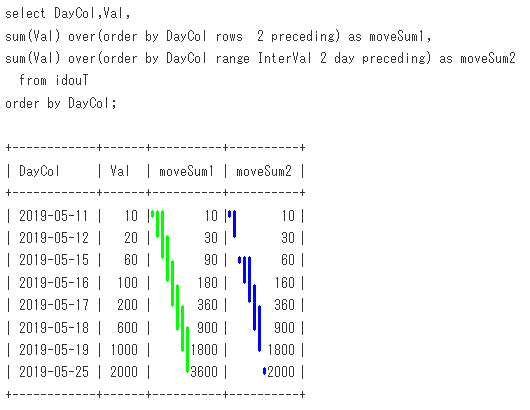
-- Sample11
select DayCol,Val,
sum(Val) over(order by DayCol rows 2 preceding) as moveSum1,
sum(Val) over(order by DayCol range InterVal 2 day preceding) as moveSum2
from idouT
order by DayCol;
出力結果
+------------+------+----------+----------+
| DayCol | Val | moveSum1 | moveSum2 |
+------------+------+----------+----------+
| 2019-05-11 | 10 | 10 | 10 |
| 2019-05-12 | 20 | 30 | 30 |
| 2019-05-15 | 60 | 90 | 60 |
| 2019-05-16 | 100 | 180 | 160 |
| 2019-05-17 | 200 | 360 | 360 |
| 2019-05-18 | 600 | 900 | 900 |
| 2019-05-19 | 1000 | 1800 | 1800 |
| 2019-05-25 | 2000 | 3600 | 2000 |
+------------+------+----------+----------+
-- Sample11の相関サブクエリを使った代替方法
select DayCol,Val,
(select sum(b.Val)
from idouT b
where (select count(*)
from idouT c
where c.DayCol between b.DayCol and a.DayCol)
between 1 and 2 + 1) as moveSum1,
(select sum(b.Val)
from idouT b
where b.DayCol between a.DayCol - 2 and a.DayCol) as moveSum2
from idouT a
order by DayCol;
Window関数のorder by以降の、省略時の仕様として、
order by DayCol rows 2 precedingは、
order by DayCol rows between 2 preceding and current row
と同じ扱いとなります。
同様に、
order by DayCol range InterVal 2 day precedingは、
order by DayCol range between InterVal 2 day preceding and current row
と同じ扱いとなります。
rows指定とrange指定の違いは、
rowsは、ソートキーで並べた時の、前もしくは後ろの行数の指定であり、
rangeは、ソートキーが、どれだけ前もしくは後ろかの指定であることです。
それぞれ、下記のように解釈すると分かりやすいです。
order by DayCol -- DayColの昇順で、
rows between -- 行の範囲は、
2 preceding -- 2行前から
and current row -- カレント行まで
order by DayCol -- DayColの昇順で、
range between -- 値の範囲は、
InterVal 2 day preceding -- 2日前から
and current row -- カレント行まで
脳内のイメージは、このようになります。
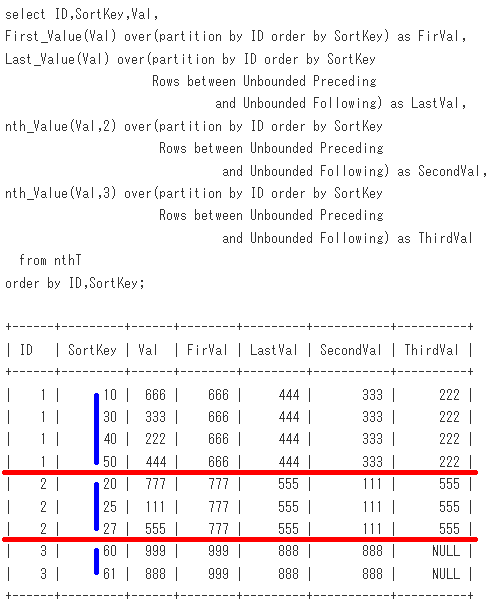
09. First_ValueとLast_Valueとnth_Value
指定したソートキーでの、最初の行の値を求めるのが、First_Value。
指定したソートキーでの、最後の行の値を求めるのが、Last_Value。
指定したソートキーでの、(Row_Numberな順位が) n番目の行の値を求めるのが、nth_Valueとなります。
create table nthT(ID int,SortKey int,Val int);
insert into nthT values(1,10,666),
(1,30,333),
(1,40,222),
(1,50,444),
(2,20,777),
(2,25,111),
(2,27,555),
(3,60,999),
(3,61,888);
-- Sample12
select ID,SortKey,Val,
First_Value(Val) over(partition by ID order by SortKey) as FirVal,
Last_Value(Val) over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as LastVal,
nth_Value(Val,2) over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as SecondVal,
nth_Value(Val,3) over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as ThirdVal
from nthT
order by ID,SortKey;
出力結果
+------+---------+------+--------+---------+-----------+----------+
| ID | SortKey | Val | FirVal | LastVal | SecondVal | ThirdVal |
+------+---------+------+--------+---------+-----------+----------+
| 1 | 10 | 666 | 666 | 444 | 333 | 222 |
| 1 | 30 | 333 | 666 | 444 | 333 | 222 |
| 1 | 40 | 222 | 666 | 444 | 333 | 222 |
| 1 | 50 | 444 | 666 | 444 | 333 | 222 |
| 2 | 20 | 777 | 777 | 555 | 111 | 555 |
| 2 | 25 | 111 | 777 | 555 | 111 | 555 |
| 2 | 27 | 555 | 777 | 555 | 111 | 555 |
| 3 | 60 | 999 | 999 | 888 | 888 | NULL |
| 3 | 61 | 888 | 999 | 888 | 888 | NULL |
+------+---------+------+--------+---------+-----------+----------+
-- Sample12の相関サブクエリを使った代替方法
select ID,SortKey,Val,
(select b.Val from nthT b
where b.ID = a.ID order by b.SortKey Limit 1) as FirVal,
(select b.Val from nthT b
where b.ID = a.ID order by b.SortKey desc Limit 1) as LastVal,
(select b.Val from nthT b
where b.ID = a.ID order by b.SortKey Limit 1 OffSet 1) as SecondVal,
(select b.Val from nthT b
where b.ID = a.ID order by b.SortKey Limit 1 OffSet 2) as ThirdVal
from nthT a
order by ID,SortKey;
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。
10. 全称肯定,全称否定,存在肯定,存在否定
・全ての行が条件を満たすか?
・全ての行が条件を満たさないか?
・少なくとも1行が条件を満たすか?
・少なくとも1行が条件を満たさないか?
といった複数行にまたがったチェックをしたい時に使います。
create table boolCheckT(ID char(2),Val int);
insert into boolCheckT values('AA',10),
('AA',20),
('BB',10),
('BB',30),
('BB',50),
('CC',80),
('CC',90),
('DD',20),
('DD',70);
下記をチェックしてみましょう。
・check1 IDごとで、全ての行が Val < 40 を満たすか?
・check2 IDごとで、全ての行が Val < 40 を満たさないか?
・check3 IDごとで、少なくとも1つの行が Val < 40 を満たすか?
・check4 IDごとで、少なくとも1つの行が Val < 40 を満たさないか?
・check5 IDごとで、少なくとも1つの行が Val = 10 を満たし、
かつ、少なくとも1つの行が Val = 50 を満たすか?
-- Sample13
select ID,Val,
min(Val < 40) over(partition by ID) as chk1,
min((Val < 40) = false) over(partition by ID) as chk2,
max(Val < 40) over(partition by ID) as chk3,
max((Val < 40) = false) over(partition by ID) as chk4,
max(Val = 10) over(partition by ID) and
max(Val = 50) over(partition by ID) as chk5
from boolCheckT
order by ID,Val;
出力結果
+------+------+------+------+------+------+------+
| ID | Val | chk1 | chk2 | chk3 | chk4 | chk5 |
+------+------+------+------+------+------+------+
| AA | 10 | 1 | 0 | 1 | 0 | 0 |
| AA | 20 | 1 | 0 | 1 | 0 | 0 |
| BB | 10 | 0 | 0 | 1 | 1 | 1 |
| BB | 30 | 0 | 0 | 1 | 1 | 1 |
| BB | 50 | 0 | 0 | 1 | 1 | 1 |
| CC | 80 | 0 | 1 | 0 | 1 | 0 |
| CC | 90 | 0 | 1 | 0 | 1 | 0 |
| DD | 20 | 0 | 0 | 1 | 1 | 0 |
| DD | 70 | 0 | 0 | 1 | 1 | 0 |
+------+------+------+------+------+------+------+
Window関数のmax関数やmin関数で、論理演算を使用してます。
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。
 全称肯定,全称否定,存在肯定,存在否定の、SQLへの変換公式は下記となります。
全称肯定命題なら min(条件)
全称否定命題なら min(条件 = false)
存在肯定命題なら max(条件)
存在否定命題なら max(条件 = false)
存在肯定命題の論理積なら max(条件A) and max(条件B)
minやmaxの代わりに、sumを使っても、似たような結果を取得できますので、使い分けるといいです。
-- Sample14
select ID,Val,
sum((Val < 40) = false) over(partition by ID) as chk1,
sum(Val < 40) over(partition by ID) as chk2,
sum(Val < 40) over(partition by ID) as chk3,
sum((Val < 40) = false) over(partition by ID) as chk4,
sum(Val = 10) over(partition by ID) and
sum(Val = 50) over(partition by ID) as chk5
from boolCheckT
order by ID,Val;
出力結果
+------+------+------+------+------+------+------+
| ID | Val | chk1 | chk2 | chk3 | chk4 | chk5 |
+------+------+------+------+------+------+------+
| AA | 10 | 0 | 2 | 2 | 0 | 0 |
| AA | 20 | 0 | 2 | 2 | 0 | 0 |
| BB | 10 | 1 | 2 | 2 | 1 | 1 |
| BB | 30 | 1 | 2 | 2 | 1 | 1 |
| BB | 50 | 1 | 2 | 2 | 1 | 1 |
| CC | 80 | 2 | 0 | 0 | 2 | 0 |
| CC | 90 | 2 | 0 | 0 | 2 | 0 |
| DD | 20 | 1 | 1 | 1 | 1 | 0 |
| DD | 70 | 1 | 1 | 1 | 1 | 0 |
+------+------+------+------+------+------+------+
集約関数のmin関数やmax関数でも似たようなことができます。
-- 集約関数での全称肯定命題など
select ID,group_concat(cast(Val as char(2))) as ConcatVal,
min(Val < 40) as chk1,
min((Val < 40) = false) as chk2,
max(Val < 40) as chk3,
max((Val < 40) = false) as chk4,
max(Val = 10) and max(Val = 50) as chk5
from boolCheckT
group by ID
order by ID;
出力結果
+------+-----------+------+------+------+------+------+
| ID | ConcatVal | chk1 | chk2 | chk3 | chk4 | chk5 |
+------+-----------+------+------+------+------+------+
| AA | 10,20 | 1 | 0 | 1 | 0 | 0 |
| BB | 10,30,50 | 0 | 0 | 1 | 1 | 1 |
| CC | 80,90 | 0 | 1 | 0 | 1 | 0 |
| DD | 20,70 | 0 | 0 | 1 | 1 | 0 |
+------+-----------+------+------+------+------+------+
select句よりも、下記のようにhaving句で使われることが多いです。
-- having句での存在肯定命題
select ID,group_concat(cast(Val as char(2))) as ConcatVal
from boolCheckT
group by ID
having max(Val < 40)
order by ID;
出力結果
+------+-----------+
| ID | ConcatVal |
+------+-----------+
| AA | 10,20 |
| BB | 10,30,50 |
| DD | 20,70 |
+------+-----------+
全称肯定,全称否定,存在肯定,存在否定の、SQLへの変換公式は下記となります。
全称肯定命題なら min(条件)
全称否定命題なら min(条件 = false)
存在肯定命題なら max(条件)
存在否定命題なら max(条件 = false)
存在肯定命題の論理積なら max(条件A) and max(条件B)
minやmaxの代わりに、sumを使っても、似たような結果を取得できますので、使い分けるといいです。
-- Sample14
select ID,Val,
sum((Val < 40) = false) over(partition by ID) as chk1,
sum(Val < 40) over(partition by ID) as chk2,
sum(Val < 40) over(partition by ID) as chk3,
sum((Val < 40) = false) over(partition by ID) as chk4,
sum(Val = 10) over(partition by ID) and
sum(Val = 50) over(partition by ID) as chk5
from boolCheckT
order by ID,Val;
出力結果
+------+------+------+------+------+------+------+
| ID | Val | chk1 | chk2 | chk3 | chk4 | chk5 |
+------+------+------+------+------+------+------+
| AA | 10 | 0 | 2 | 2 | 0 | 0 |
| AA | 20 | 0 | 2 | 2 | 0 | 0 |
| BB | 10 | 1 | 2 | 2 | 1 | 1 |
| BB | 30 | 1 | 2 | 2 | 1 | 1 |
| BB | 50 | 1 | 2 | 2 | 1 | 1 |
| CC | 80 | 2 | 0 | 0 | 2 | 0 |
| CC | 90 | 2 | 0 | 0 | 2 | 0 |
| DD | 20 | 1 | 1 | 1 | 1 | 0 |
| DD | 70 | 1 | 1 | 1 | 1 | 0 |
+------+------+------+------+------+------+------+
集約関数のmin関数やmax関数でも似たようなことができます。
-- 集約関数での全称肯定命題など
select ID,group_concat(cast(Val as char(2))) as ConcatVal,
min(Val < 40) as chk1,
min((Val < 40) = false) as chk2,
max(Val < 40) as chk3,
max((Val < 40) = false) as chk4,
max(Val = 10) and max(Val = 50) as chk5
from boolCheckT
group by ID
order by ID;
出力結果
+------+-----------+------+------+------+------+------+
| ID | ConcatVal | chk1 | chk2 | chk3 | chk4 | chk5 |
+------+-----------+------+------+------+------+------+
| AA | 10,20 | 1 | 0 | 1 | 0 | 0 |
| BB | 10,30,50 | 0 | 0 | 1 | 1 | 1 |
| CC | 80,90 | 0 | 1 | 0 | 1 | 0 |
| DD | 20,70 | 0 | 0 | 1 | 1 | 0 |
+------+-----------+------+------+------+------+------+
select句よりも、下記のようにhaving句で使われることが多いです。
-- having句での存在肯定命題
select ID,group_concat(cast(Val as char(2))) as ConcatVal
from boolCheckT
group by ID
having max(Val < 40)
order by ID;
出力結果
+------+-----------+
| ID | ConcatVal |
+------+-----------+
| AA | 10,20 |
| BB | 10,30,50 |
| DD | 20,70 |
+------+-----------+
11. 最頻値(モード)
create table DayWeatherT(DayCol date,weather char(6));
insert into DayWeatherT values(date '2018-01-02','sunny' ),
(date '2018-01-15','snowy' ),
(date '2018-01-30','snowy' ),
(date '2018-06-01','cloudy'),
(date '2018-06-13','cloudy'),
(date '2018-06-24','rainy' ),
(date '2018-06-30','rainy' ),
(date '2018-07-02','sunny' ),
(date '2018-07-14','sunny' ),
(date '2018-07-23','sunny' ),
(date '2018-07-31','sunny' ),
(date '2018-11-10','cloudy');
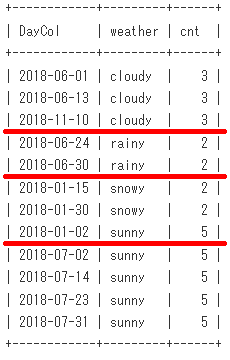
weatherの最頻値(モード)を求めてみます。(最頻値が複数ある場合は、複数行返すようにします)
-- 最頻値が必ず1つだけなら、これでも可
select weather,count(*) as cnt
from DayWeatherT
group by weather
order by count(*) desc Limit 1;
-- Sample15
select weather,cnt
from (select weather,count(*) as cnt,
max(count(*)) over() as maxCnt
from DayWeatherT
group by weather) tmp
where cnt = maxCnt;
出力結果
+---------+-----+
| weather | cnt |
+---------+-----+
| sunny | 5 |
+---------+-----+
-- Sample15のサブクエリを使った代替方法
select weather,count(*) as cnt
from DayWeatherT
group by weather
having count(*) >= all(select count(*)
from DayWeatherT
group by weather);
脳内のイメージは、このようになります。group by weatherに対応する赤線を引いてます。
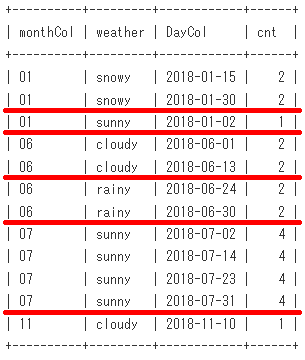
 monthごとの最頻値(モード)を求めてます。
-- Sample16
select monthCol,weather,cnt
from (select Date_Format(DayCol,'%m') as monthCol,weather,
count(*) as cnt,
max(count(*)) over(partition by Date_Format(DayCol,'%m')) as maxCnt
from DayWeatherT
group by monthCol,weather) a
where cnt = maxCnt
order by monthCol,weather;
出力結果
+----------+---------+-----+
| monthCol | weather | cnt |
+----------+---------+-----+
| 01 | snowy | 2 |
| 06 | cloudy | 2 |
| 06 | rainy | 2 |
| 07 | sunny | 4 |
| 11 | cloudy | 1 |
+----------+---------+-----+
-- Sample16の相関サブクエリを使った代替方法
select monthCol,weather,count(*) as cnt
from (select Date_Format(DayCol,'%m') as monthCol,weather
from DayWeatherT) a
group by monthCol,weather
having count(*) >= all(select count(*)
from DayWeatherT b
where Date_Format(b.DayCol,'%m') = a.monthCol
group by b.weather)
order by monthCol,weather;
Sample16の脳内のイメージ(第1段階)は、こうなります。
group by Date_Format(DayCol,'%m'),weather に対応する赤線を引いてます。
monthごとの最頻値(モード)を求めてます。
-- Sample16
select monthCol,weather,cnt
from (select Date_Format(DayCol,'%m') as monthCol,weather,
count(*) as cnt,
max(count(*)) over(partition by Date_Format(DayCol,'%m')) as maxCnt
from DayWeatherT
group by monthCol,weather) a
where cnt = maxCnt
order by monthCol,weather;
出力結果
+----------+---------+-----+
| monthCol | weather | cnt |
+----------+---------+-----+
| 01 | snowy | 2 |
| 06 | cloudy | 2 |
| 06 | rainy | 2 |
| 07 | sunny | 4 |
| 11 | cloudy | 1 |
+----------+---------+-----+
-- Sample16の相関サブクエリを使った代替方法
select monthCol,weather,count(*) as cnt
from (select Date_Format(DayCol,'%m') as monthCol,weather
from DayWeatherT) a
group by monthCol,weather
having count(*) >= all(select count(*)
from DayWeatherT b
where Date_Format(b.DayCol,'%m') = a.monthCol
group by b.weather)
order by monthCol,weather;
Sample16の脳内のイメージ(第1段階)は、こうなります。
group by Date_Format(DayCol,'%m'),weather に対応する赤線を引いてます。
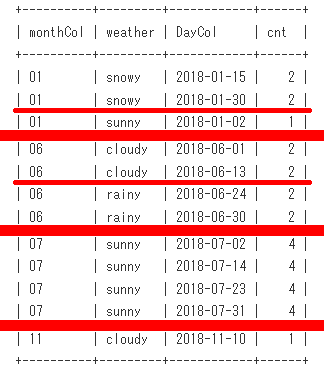
 Sample16の脳内のイメージ(最終段階)は、こうなります。
partition by Date_Format(DayCol,'%m')に対応する超極太赤線を引いてます。
Sample16の脳内のイメージ(最終段階)は、こうなります。
partition by Date_Format(DayCol,'%m')に対応する超極太赤線を引いてます。
12. Range指定で2分前の値を求める
「06. 前後の行の値」で説明したように、Lag関数を使えば、
指定したソートキーの順序での、1行前の行の値や2行前の行の値などが取得できます。
Window関数のRange指定を使えば、
指定した列の値(数値型)が、1小さい行の値や、2小さい行の値などを取得できます。また、
指定した列の値(日時型)が、1分前の行の値や、2分前の行の値なども取得できます。
create table WindowRangeT(DateTimeCol DateTime,Val int);
insert into WindowRangeT values(TimeStamp '2019-05-01 10:00:00',111),
(TimeStamp '2019-05-01 10:02:00',222),
(TimeStamp '2019-05-01 10:05:00',333),
(TimeStamp '2019-05-01 10:09:00',444),
(TimeStamp '2019-05-01 10:10:00',555),
(TimeStamp '2019-05-01 10:11:00',666),
(TimeStamp '2019-05-01 10:12:00',777),
(TimeStamp '2019-05-01 10:15:00',888);
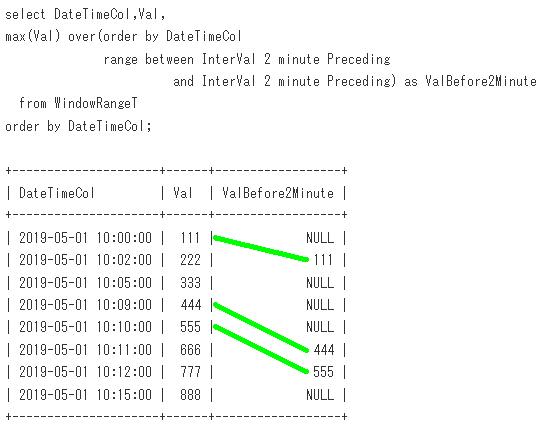
DateTimeColが2分前の行のValを取得してみます。
-- Sample17
select DateTimeCol,Val,
max(Val) over(order by DateTimeCol
range between InterVal 2 minute Preceding
and InterVal 2 minute Preceding) as ValBefore2Minute
from WindowRangeT
order by DateTimeCol;
出力結果
+---------------------+------+------------------+
| DateTimeCol | Val | ValBefore2Minute |
+---------------------+------+------------------+
| 2019-05-01 10:00:00 | 111 | NULL |
| 2019-05-01 10:02:00 | 222 | 111 |
| 2019-05-01 10:05:00 | 333 | NULL |
| 2019-05-01 10:09:00 | 444 | NULL |
| 2019-05-01 10:10:00 | 555 | NULL |
| 2019-05-01 10:11:00 | 666 | 444 |
| 2019-05-01 10:12:00 | 777 | 555 |
| 2019-05-01 10:15:00 | 888 | NULL |
+---------------------+------+------------------+
-- Sample17の相関サブクエリを使った代替方法
select DateTimeCol,Val,
(select max(b.Val)
from WindowRangeT b
where b.DateTimeCol = a.DateTimeCol - InterVal 2 minute) as ValBefore2Minute
from WindowRangeT a
order by DateTimeCol;
Window関数のorder by以降は、下記のように解釈すると分かりやすいでしょう。
order by DateTimeCol -- DateTimeColの昇順で、
range between -- 値の範囲は、
InterVal 2 minute Preceding -- 小さいほうは、2分前の行から
and InterVal 2 minute Preceding -- 大きいほうは、2分前の行まで
脳内のイメージは、このようになります。
13. PostgreSQLのstring_aggを模倣
create table StringAggT(ID int,Val char(1));
insert into StringAggT values(111,'a'),
(111,'b'),
(111,'c'),
(222,'d'),
(222,'e'),
(222,'f');
PostgreSQLでは、文字列を集約するstring_agg関数がWindow関数として使用できます。
-- 模倣対象のPostgreSQLのSQL
select ID,Val,
string_agg(Val,',') over(partition by ID) as strAgg1,
string_agg(Val,',') over(order by Val) as strAgg2
from StringAggT
order by ID,Val;
出力結果
ID | Val | strAgg1 | strAgg2
-----+-----+---------+-------------
111 | a | a,b,c | a
111 | b | a,b,c | a,b
111 | c | a,b,c | a,b,c
222 | d | d,e,f | a,b,c,d
222 | e | d,e,f | a,b,c,d,e
222 | f | d,e,f | a,b,c,d,e,f
MySQL8.0.15では、gruop_concat関数がWindow関数として使用できませんが、
JSON_ArrayAgg関数で似たような結果を取得可能です。
Window関数の集約の内訳を見るといった用途であれば、JSON_ArrayAgg関数でも問題ないと思います。
-- Sample18
select ID,Val,
JSON_ArrayAgg(Val) over(partition by ID) as strAgg1,
JSON_ArrayAgg(Val) over(order by Val) as strAgg2
from StringAggT
order by ID,Val;
出力結果
+------+------+-----------------+--------------------------------+
| ID | Val | strAgg1 | strAgg2 |
+------+------+-----------------+--------------------------------+
| 111 | a | ["a", "b", "c"] | ["a"] |
| 111 | b | ["a", "b", "c"] | ["a", "b"] |
| 111 | c | ["a", "b", "c"] | ["a", "b", "c"] |
| 222 | d | ["d", "e", "f"] | ["a", "b", "c", "d"] |
| 222 | e | ["d", "e", "f"] | ["a", "b", "c", "d", "e"] |
| 222 | f | ["d", "e", "f"] | ["a", "b", "c", "d", "e", "f"] |
+------+------+-----------------+--------------------------------+
14. PostgreSQLのgroups指定を模倣
PostgreSQLのWindow関数では、rows指定やrange指定の他に、groups指定が使えます。
参考サイト そーだいなるらくがき帳
create table groupsT(ID int,Val int);
insert into groupsT values(1, 1),
(2, 1),
(3, 3),
(4, 5),
(5, 5),
(6, 5),
(7, 6);
-- 模倣対象のPostgreSQLのSQL
select id,Val,
array_agg(id) over(order by Val
groups between 1 preceding and 1 following) as groups_id,
array_agg(Val) over(order by Val
groups between 1 preceding and 1 following) as groups_Val
from t;
出力結果
id | Val | groups_id | groups_Val
----+-----+---------------+---------------
1 | 1 | {1,2,3} | {1,1,3}
2 | 1 | {1,2,3} | {1,1,3}
3 | 3 | {1,2,3,4,5,6} | {1,1,3,5,5,5}
4 | 5 | {3,4,5,6,7} | {3,5,5,5,6}
5 | 5 | {3,4,5,6,7} | {3,5,5,5,6}
6 | 5 | {3,4,5,6,7} | {3,5,5,5,6}
7 | 6 | {4,5,6,7} | {5,5,5,6}
MySQL8.0で模倣しようとすると、
dense_rankで、競技プログラミングの座標圧縮みたいなことをしてから、
range指定を使う必要があります。
-- Sample19
with tmp as(
select id,Val,dense_rank() over(order by Val) as rn
from groupsT)
select id,Val,
JSON_ArrayAgg(id) over(order by rn
range between 1 preceding and 1 following) as groups_id,
JSON_ArrayAgg(Val) over(order by rn
range between 1 preceding and 1 following) as groups_Val
from tmp
order by id;
出力結果
+------+------+--------------------+--------------------+
| id | Val | groups_id | groups_Val |
+------+------+--------------------+--------------------+
| 1 | 1 | [1, 2, 3] | [1, 1, 3] |
| 2 | 1 | [1, 2, 3] | [1, 1, 3] |
| 3 | 3 | [1, 2, 3, 4, 5, 6] | [1, 1, 3, 5, 5, 5] |
| 4 | 5 | [3, 4, 5, 6, 7] | [3, 5, 5, 5, 6] |
| 5 | 5 | [3, 4, 5, 6, 7] | [3, 5, 5, 5, 6] |
| 6 | 5 | [3, 4, 5, 6, 7] | [3, 5, 5, 5, 6] |
| 7 | 6 | [4, 5, 6, 7] | [5, 5, 5, 6] |
+------+------+--------------------+--------------------+
15. OracleのCountでのdistinct指定を模倣
create table OracleDistinctT(ID int,Val int not null);
insert into OracleDistinctT values(1,111);
insert into OracleDistinctT values(1,111);
insert into OracleDistinctT values(1,222);
insert into OracleDistinctT values(1,222);
insert into OracleDistinctT values(1,333);
insert into OracleDistinctT values(2,111);
insert into OracleDistinctT values(2,111);
insert into OracleDistinctT values(3,111);
insert into OracleDistinctT values(3,222);
insert into OracleDistinctT values(4,333);
Oracleでは、分析関数のcount関数でdistinctオプションが使えます。
MySQL8.0で、下記のOracleのSQLと同じ結果を取得してみます。
-- 模倣対象のOracleのSQL
select ID,Val,count(distinct Val) over(partition by ID) as disCnt
from OracleDistinctT;
出力結果
ID Val disCnt
-- --- ------
1 111 3
1 111 3
1 222 3
1 222 3
1 333 3
2 111 1
2 111 1
3 111 2
3 222 2
4 333 1
-- Sample20
select ID,Val,max(rn) over(partition by ID) as disCnt
from (select ID,Val,dense_rank() over(partition by ID order by Val) as rn
from OracleDistinctT) tmp
order by ID,Val;
-- Sample20の相関サブクエリを使った代替方法
select ID,Val,
(select count(distinct b.Val)
from OracleDistinctT b where b.ID = a.ID) as disCnt
from OracleDistinctT a
order by ID,Val;
dense_rank関数の結果の最大値を取得して模倣してます。
脳内のイメージは、このようになります。partition by IDで赤線を引いてます。
 ちなみに、count(distinct Val)は、Valがnullだとカウントしませんので、
Valがnullの場合も考慮するなら、下記のように存在肯定命題を使う必要があります。
-- Sample21
select ID,Val,max(rn) over(partition by ID) - HasNull as disCnt
from (select ID,Val,dense_rank() over(partition by ID order by Val) as rn,
max(Val is null) over(partition by ID) as HasNull
from OracleDistinctT) tmp
order by ID,Val;
ちなみに、count(distinct Val)は、Valがnullだとカウントしませんので、
Valがnullの場合も考慮するなら、下記のように存在肯定命題を使う必要があります。
-- Sample21
select ID,Val,max(rn) over(partition by ID) - HasNull as disCnt
from (select ID,Val,dense_rank() over(partition by ID order by Val) as rn,
max(Val is null) over(partition by ID) as HasNull
from OracleDistinctT) tmp
order by ID,Val;
16. Oracleのnth_Valueでのfrom Lastを模倣
create table OracleFromLastT(ID char(1),SortKey1 int,SortKey2 int,Val int);
insert into OracleFromLastT values('A',1,1,111);
insert into OracleFromLastT values('A',1,2,222);
insert into OracleFromLastT values('A',3,1,333);
insert into OracleFromLastT values('A',3,2,444);
insert into OracleFromLastT values('B',5,1,555);
insert into OracleFromLastT values('B',5,2,666);
insert into OracleFromLastT values('B',5,3,777);
insert into OracleFromLastT values('B',7,1,888);
Oracleでは、分析関数のnth_Value関数でfrom Lastが使えます。
MySQL8.0で、下記のOracleのSQLと同じ結果を取得してみます。
-- 模倣対象のOracleのSQL
select ID,SortKey1,SortKey2,Val,
nth_Value(Val,2) from Last
over(partition by ID order by SortKey1,SortKey2
Rows between Unbounded Preceding
and Unbounded Following) as SecondVal
from OracleFromLastT
order by SortKey1,SortKey2;
出力結果
ID SortKey1 SortKey2 Val SecondVal
-- -------- -------- --- ---------
A 1 1 111 333
A 1 2 222 333
A 3 1 333 333
A 3 2 444 333
B 5 1 555 777
B 5 2 666 777
B 5 3 777 777
B 7 1 888 777
-- Sample22
select ID,SortKey1,SortKey2,Val,
nth_Value(Val,2)
over(partition by ID order by SortKey1 desc,SortKey2 desc
Rows between Unbounded Preceding
and Unbounded Following) as SecondVal
from OracleFromLastT
order by SortKey1,SortKey2;
-- Sample22の相関サブクエリを使った代替方法
select ID,SortKey1,SortKey2,Val,
(select b.Val
from OracleFromLastT b
where b.ID = a.ID
order by b.SortKey1 desc,b.SortKey2 desc Limit 1 OffSet 1) as SecondVal
from OracleFromLastT a
order by ID,Val;
order by句のascとdescを入れ替えると、逆ソートができることをふまえてます。
例1 order by X,Y,Zの逆ソートは、
order by X desc,Y desc,Z desc
例2 order by X desc,Y,Z ascの逆ソートは、
order by X asc,Y desc,Z desc
17. OracleのLast_Valueでのignore nullsを模倣(entire)
create table ignLastValT(ID int,SortKey int,Val int);
insert into ignLastValT values(1,1, 555);
insert into ignLastValT values(1,2,null);
insert into ignLastValT values(1,3, 111);
insert into ignLastValT values(1,4,null);
insert into ignLastValT values(2,1, 888);
insert into ignLastValT values(2,2, 222);
insert into ignLastValT values(2,3,null);
insert into ignLastValT values(2,4, 444);
insert into ignLastValT values(3,1, 777);
insert into ignLastValT values(3,2,null);
insert into ignLastValT values(3,3,null);
insert into ignLastValT values(3,4,null);
insert into ignLastValT values(3,5, 333);
insert into ignLastValT values(4,1,null);
insert into ignLastValT values(4,2,null);
Oracleの分析関数では、First_Value関数やLast_Value関数やnth_Value関数で、ignore nullsを指定できます。
Last_Value(値 ignore nulls) over句 が基本的な使い方ですが、
Last_Value(case when 条件 then 値 end ignore nulls) over句 というふうに、
case式を組み合わせて使うほうが多いです。
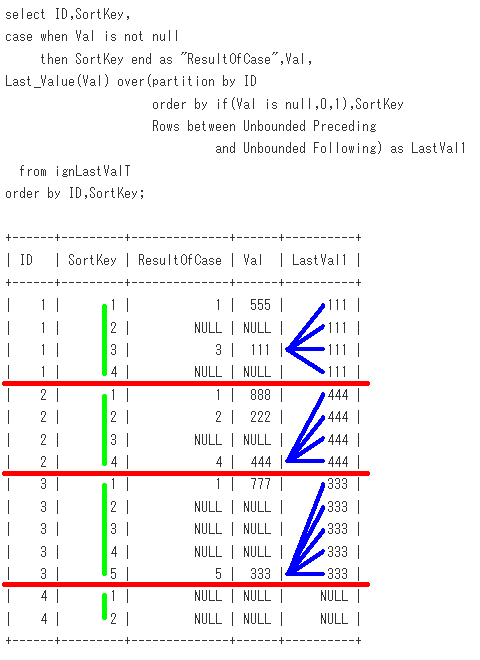
MySQL8.0で、下記のOracleのSQLと同じ結果を取得してみます。
-- 模倣対象のOracleのSQL
select ID,SortKey,Val,
Last_Value(Val ignore nulls)
over(partition by ID
order by SortKey Rows between Unbounded Preceding
and Unbounded Following) as LastVal1
from ignLastValT
order by ID,SortKey;
出力結果
ID SortKey Val LastVal1
-- ------- ---- --------
1 1 555 111
1 2 null 111
1 3 111 111
1 4 null 111
2 1 888 444
2 2 222 444
2 3 null 444
2 4 444 444
3 1 777 333
3 2 null 333
3 3 null 333
3 4 null 333
3 5 333 333
4 1 null null
4 2 null null
-- Sample23
select ID,SortKey,Val,
Last_Value(Val) over(partition by ID
order by if(Val is null,0,1),SortKey
Rows between Unbounded Preceding
and Unbounded Following) as LastVal1
from ignLastValT
order by ID,SortKey;
if関数で、Valがnullな行が最後にならないようにしてます。
-- Sample23の相関サブクエリを使った代替方法
select ID,SortKey,Val,
(select b.Val
from ignLastValT b
where b.ID = a.ID
and b.Val is not null
order by b.SortKey desc Limit 1) as LastVal1
from ignLastValT a
order by ID,SortKey;
脳内のイメージは、このようになります。
18. OracleのLast_Valueでのignore nullsを模倣(until)
今度は、その行までを対象としたLast_Value関数(ignore nulls)を模倣します。
-- 模倣対象のOracleのSQL
select ID,SortKey,Val,
Last_Value(Val ignore nulls)
over(partition by ID order by SortKey) as LastVal2
from ignLastValT
order by ID,SortKey;
出力結果
ID SortKey Val LastVal2
-- ------- ---- --------
1 1 555 555
1 2 null 555
1 3 111 111
1 4 null 111
2 1 888 888
2 2 222 222
2 3 null 222
2 4 444 444
3 1 777 777
3 2 null 777
3 3 null 777
3 4 null 777
3 5 333 333
4 1 null null
4 2 null null
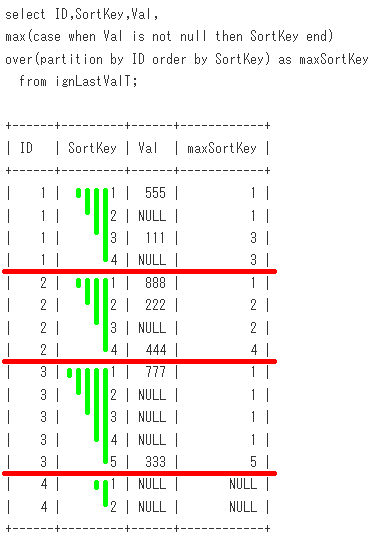
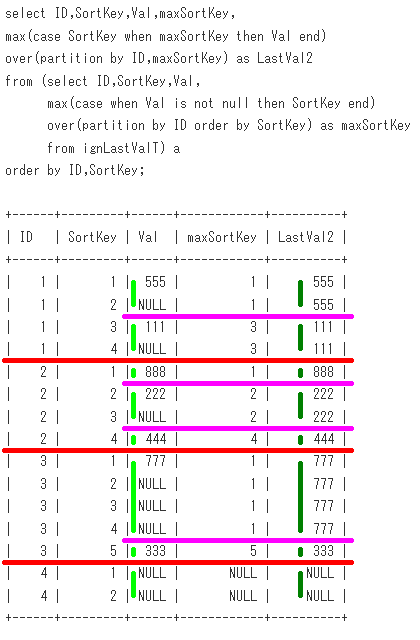
-- Sample24
select ID,SortKey,Val,
max(case SortKey when maxSortKey then Val end)
over(partition by ID,maxSortKey) as LastVal2
from (select ID,SortKey,Val,
max(case when Val is not null then SortKey end)
over(partition by ID order by SortKey) as maxSortKey
from ignLastValT) a
order by ID,SortKey;
最初にインラインビューでWindow関数のmax関数を使って、
SortKeyの昇順で、その行以前で最後にValがnullでなかったSortKeyを求めてます。
次に、そのSortKeyの行のValの値を、Pivotクエリでよく使われるmax関数とcase式を組み合わせる手法で求めてます。
-- Sample24の相関サブクエリを使った代替方法
select ID,SortKey,Val,
(select b.Val
from ignLastValT b
where b.ID = a.ID
and b.SortKey <= a.SortKey
and b.Val is not null
order by b.SortKey desc Limit 1) as LastVal2
from ignLastValT a
order by ID,SortKey;
脳内のイメージ(第1段階)は、こうなります。partition by IDに対応する赤線を引いてます。
 脳内のイメージ(最終段階)は、こうなります。partition by ID,maxSortKeyに対応する紫線を引いてます。
脳内のイメージ(最終段階)は、こうなります。partition by ID,maxSortKeyに対応する紫線を引いてます。
19. OracleのLag,Leadでのignore nullsを模倣
Oracleでは、Lag関数とLead関数でもignore nullsを指定することができます。
MySQL8.0で、下記のOracleのSQLと同じ結果を取得してみます。
create table ignLagLeadT(SortKey int,Val int);
insert into ignLagLeadT values( 1, 2);
insert into ignLagLeadT values( 2,null);
insert into ignLagLeadT values( 5, 4);
insert into ignLagLeadT values( 9,null);
insert into ignLagLeadT values(11, 6);
insert into ignLagLeadT values(12,null);
insert into ignLagLeadT values(14,null);
insert into ignLagLeadT values(16, 5);
insert into ignLagLeadT values(17,null);
insert into ignLagLeadT values(20, 3);
insert into ignLagLeadT values(21,null);
insert into ignLagLeadT values(22, 4);
-- 模倣対象のOracleのSQL
select SortKey,Val,
Lag (Val,2,999) ignore nulls over(order by SortKey) as Lag2,
Lead(Val,2,999) ignore nulls over(order by SortKey) as Lead2
from ignLagLeadT;
出力結果
SortKey Val Lag2 Lead2
------- ---- ---- -----
1 2 999 6
2 null 999 6
5 4 999 5
9 null 2 5
11 6 2 3
12 null 4 3
14 null 4 3
16 5 4 4
17 null 6 4
20 3 6 999
21 null 5 999
22 4 5 999
-- Sample25
select SortKey,Val,
IfNull(max(Val) over(order by NonNullCnt1
range between 2 Preceding
and 2 Preceding),999) as Lag2,
IfNull(max(Val) over(order by NonNullCnt2
range between 2 Preceding
and 2 Preceding),999) as Lead2
from (select SortKey,Val,
count(Val) over(order by SortKey Rows
between Unbounded Preceding
and 1 Preceding) as NonNullCnt1,
count(Val) over(order by SortKey Rows
between 1 Following
and Unbounded Following) as NonNullCnt2
from ignLagLeadT) a
order by SortKey;
Window関数のcount関数で、
その行の1つ前までのNullでない行数と、
その行の1つ後からのNullでない行数を求めておき、
その行数でorder byしてrange指定してます。
-- Sample25の相関サブクエリを使った代替方法
select SortKey,Val,
IfNull((select b.Val
from ignLagLeadT b
where b.Val is not null
and b.SortKey < a.SortKey
order by b.SortKey desc Limit 1 offset 1),999) as Lag2,
IfNull((select b.Val
from ignLagLeadT b
where b.Val is not null
and b.SortKey > a.SortKey
order by b.SortKey Limit 1 offset 1),999) as Lead2
from ignLagLeadT a
order by SortKey;
参考資料