図でイメージするOracleのSQL全集の元原稿
第9回 Model句
第7回 再帰with句
第8回 PivotとUnPivot
連載のテーマ
前回と同じとなります。
動作確認環境
Oracle Database 11g Release 11.2.0.1.0 (Windows 32ビット版)
今回のテーマ
今回は、下記のOracleのSQL文の評価順序においての、
1番目のfrom句で行列変換を行うことができる、PivotとUnPivotの使用例と
私のSQLのイメージを解説します。
1番目 from句
2番目 where句 (結合条件)
3番目 start with句
4番目 connect by句
5番目 where句 (行のフィルタ条件)
6番目 group by句
7番目 having句
8番目 model句
9番目 select句
10番目 union、minus、intersectなどの集合演算
11番目 order by句
目次
1 PivotとUnPivotとは
select文での行列変換
PivotとUnPivotはOracle11gR1の新機能で、select文での行列変換を容易に行うことができます。
英和辞典のPivotの意味の中で、select文でのPivotの意味に近いものを選ぶと、
動詞では、「旋回する,回転する」。名詞では、「旋回軸,回転軸」となります。
select文での評価順序において、PivotとUnPivotはfrom句の一部として評価されます。
2 select文でのPivotとUnPivotの評価順序
from句の一部として評価されている例
PivotとUnPivotはfrom句の一部として評価されるので下記のようなselect文も実行できます。
PivotやUnPivotした結果に表別名を付けることもできます。
-- from句の一部として評価されている例1
select * from (select 1 as ColA,5 as ColB from dual)
UnPivot(Vals1 for Cols1 in(ColA,ColA,ColA))
UnPivot(Vals2 for Cols2 in(ColB,ColB))
Pivot(count(*) for Vals1 in(1 as C1))
Pivot(count(*) for Vals2 in(5 as C2)) a
Join dual b
on a.C1 = 6;
出力結果
Cols1 Cols2 C1 C2 Dummy
----- ----- -- -- -----
COLA COLB 6 1 X
-- from句の一部として評価されている例2
with work(ColA,ColB) as(
select 1,1 from dual union all
select 2,2 from dual)
select *
from work Join dual on 1=1
UnPivot(Vals for Cols in(ColA,ColB));
出力結果
Dummy Cols Vals
----- ---- ----
X COLA 1
X COLB 1
X COLA 2
X COLB 2
3 Pivotの使い方
行持ちデータを列持ちデータに変換
create table PivotSample(
ID number(1),
Year number(4),
Val number(3),
primary key (ID,Year));
insert into PivotSample
select 1,2010, 1 from dual union all
select 1,2011, 2 from dual union all
select 1,2012, 6 from dual union all
select 2,2010, 70 from dual union all
select 2,2011, 80 from dual union all
select 3,2012, 90 from dual union all
select 4,2010,300 from dual union all
select 4,2012,500 from dual;
Pivotを使って、行持ちデータを列持ちデータに変換してみます。
-- Pivotのサンプル
select *
from PivotSample
Pivot (max(Val) for Year in(2010 as Agg2010,
2011 as Agg2011,
2012 as Agg2012))
order by ID;
出力結果
ID Agg2010 Agg2011 Agg2012
-- ------- ------- -------
1 1 2 6
2 70 80 null
3 null null 90
4 300 null 500
Pivotの構文は、下記のように理解しておくといいでしょう。
Pivot(集約関数 for 集約条件列 in(集約条件値1 as 集約後列名1,
集約条件値2 as 集約後列名2,
集約条件値3 as 集約後列名3))
Pivotでは、
集約関数で使用している列でなく、かつ集約条件列で使用している列でもない列で、
暗黙のgroup byが実行されます。
上記のselect文においては、
集約関数で使用している列は、Val列です。max(Val)といった形でVal列を使用しているからです。
そして、集約条件列で使用している列は、Year列です。
よって、集約関数で使用している列でなく、かつ集約条件列で使用している列でもない、
ID列で暗黙のgroup byが実行されます。
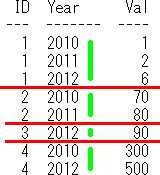
PivotのSQLのイメージは下記となります。
暗黙のgroup byによる赤線をイメージし、
for 集約条件列 (上記のselect文では、for Yearの部分) で黄緑線をイメージしてます。
 下記のように、集約後列名の指定を省略することもできます。(集約条件値が列名になります)
-- 集約後列名の指定を省略
select *
from PivotSample
Pivot (max(Val) for Year in(2010,2011,2012))
order by ID;
出力結果
ID 2010 2011 2012
-- ---- ---- ----
1 1 2 6
2 70 80 null
3 null null 90
4 300 null 500
下記のように、集約後列名の指定を省略することもできます。(集約条件値が列名になります)
-- 集約後列名の指定を省略
select *
from PivotSample
Pivot (max(Val) for Year in(2010,2011,2012))
order by ID;
出力結果
ID 2010 2011 2012
-- ---- ---- ----
1 1 2 6
2 70 80 null
3 null null 90
4 300 null 500
4 Pivotの代用法
集約関数とdecode関数の組み合わせ
-- Pivotの代用 (集約関数とdecode関数)
select ID,
max(decode(Year,2010,Val)) as Agg2010,
max(decode(Year,2011,Val)) as Agg2011,
max(decode(Year,2012,Val)) as Agg2012
from PivotSample
group by ID
order by ID;
出力結果
ID Agg2010 Agg2011 Agg2012
-- ------- ------- -------
1 1 2 6
2 70 80 null
3 null null 90
4 300 null 500
Pivotは、上記のように、集約関数とdecode関数を組み合わせることで代用できます。
decode関数で集約対象外のデータをnullに変換し、集約関数がnullを無視する性質を使ってます。
5 Pivotと、Pivotの代用法を比較
暗黙のgroup byはイメージしにくい
Pivotと、Pivotの代用法(集約関数とdecode関数)の比較結果として、
両者は使い分けるのがいいと思われます。理由は下記です。
・理由1 Pivotでは、暗黙のgroup byが実行され、暗黙のgroup byはイメージしにくい
・理由2 Pivotで、不要な列を暗黙のgroup byの対象外にするには、インラインビューが必要
・理由3 Pivotで計算式を使用するには、インラインビューが必要
理由1の暗黙のgroup byは、Pivotの使い方で説明したので、
理由2と3の例として、月ごとのValの合計を表示するselect文を比較します。
create table PivotCompare(
DayCol date primary key,
Val number(3),
bikou VarChar2(6));
insert into PivotCompare
select date '2012-01-05', 10,'bikou1' from dual union all
select date '2012-01-16', 20,'bikou2' from dual union all
select date '2012-01-28', 60,'bikou3' from dual union all
select date '2012-02-11',200,null from dual union all
select date '2012-02-22',300,null from dual union all
select date '2012-03-30',700,'bikou4' from dual;
-- Pivotの代用 (集約関数とdecode関数)
select
sum(decode(extract(month from DayCol),1,Val)) as sum1,
count(decode(extract(month from DayCol),1,Val)) as cnt1,
sum(decode(extract(month from DayCol),2,Val)) as sum2,
count(decode(extract(month from DayCol),2,Val)) as cnt2,
sum(decode(extract(month from DayCol),3,Val)) as sum3,
count(decode(extract(month from DayCol),3,Val)) as cnt3
from PivotCompare;
出力結果
sum1 cnt1 sum2 cnt2 sum3 cnt3
---- ---- ---- ---- ---- ----
90 3 500 2 700 1
-- Pivotを使用
select *
from (select extract(month from DayCol) as month,Val
from PivotCompare)
Pivot (sum(Val) as sum,
count(*) as cnt
for month in(1,2,3));
出力結果
1_SUM 1_CNT 2_SUM 2_CNT 3_SUM 3_CNT
----- ----- ----- ----- ----- -----
90 3 500 2 700 1
extract(month from DayCol)といった計算式を使ってPivotを行うには、インラインビューが必要となります。
下記のように、文法エラーになるからです。
-- 文法エラー ORA-01738: INキーワードがありません。
select *
from PivotCompare
Pivot (sum(Val) as sum,
count(*) as cnt
for extract(month from DayCol) in(1,2,3));
また、bikou列が、暗黙のgroup byのグループ化のキーの1つになることを防ぐためにも、
bikou列を除いたselect文を使ったインラインビューが必要となります。
6 Pivotのサンプル集
Pivotの雛形
-- 基本的なPivot その1
with t(ID,Seq,Val) as(
select 111,1,77 from dual union all
select 111,2,66 from dual union all
select 111,3,55 from dual union all
select 222,1,44 from dual union all
select 222,3,33 from dual union all
select 333,2,22 from dual)
select * from t
Pivot(max(Val) for Seq in(1,2,3))
order by ID;
出力結果
ID 1 2 3
--- ---- ---- ----
111 77 66 55
222 44 null 33
333 null 22 null
-- 基本的なPivot その2
with t(ID,Seq,Val) as(
select 111,1,77 from dual union all
select 111,2,66 from dual union all
select 111,3,55 from dual union all
select 222,1,44 from dual union all
select 222,3,33 from dual union all
select 333,2,22 from dual)
select * from t
Pivot(max(Val) for Seq in(1 as Seq1,
2 as Seq2,
3 as Seq3))
order by ID;
出力結果
ID Seq1 Seq2 Seq3
--- ---- ---- ----
111 77 66 55
222 44 null 33
333 null 22 null
-- 複数列でPivot その1
with t(ID,Year,Month,Val) as(
select 1,2012,1, 10 from dual union all
select 1,2012,2, 20 from dual union all
select 1,2012,3, 60 from dual union all
select 2,2012,1,300 from dual union all
select 2,2012,3,500 from dual union all
select 3,2012,2,900 from dual)
select * from t
Pivot(max(Val)
for (Year,Month)
in ((2012,1) as Agg1,
(2012,2) as Agg2,
(2012,3) as Agg3));
出力結果
ID Agg1 Agg2 Agg3
-- ---- ---- ----
1 10 20 60
2 300 null 500
3 null 900 null
-- 複数列でPivot その2
with t(ID,Year,Month,Val) as(
select 1,2012,1, 10 from dual union all
select 1,2012,1,700 from dual union all
select 1,2012,2, 20 from dual union all
select 1,2012,3, 60 from dual union all
select 2,2012,1,300 from dual union all
select 2,2012,1,999 from dual union all
select 2,2012,3,500 from dual union all
select 3,2012,2,900 from dual)
select * from t
Pivot(count(*) as cnt,
max(Val) as max
for (Year,Month)
in ((2012,1) as Agg1,
(2012,2) as Agg2,
(2012,3) as Agg3));
出力結果
ID AGG1_CNT AGG1_MAX AGG2_CNT AGG2_MAX AGG3_CNT AGG3_MAX
-- -------- -------- -------- -------- -------- --------
1 2 700 1 20 1 60
2 2 999 0 null 1 500
3 0 null 1 900 0 null
7 UnPivotの使い方
列持ちデータを行持ちデータに変換
create table UnPivotSample(
ID number(1) primary key,
Val1 number(2),
Val2 number(2),
Val3 number(2));
insert into UnPivotSample
select 1,12, 11, 10 from dual union all
select 3,30, 90,null from dual union all
select 5,50,null,null from dual;
UnPivotを使って、列持ちデータを行持ちデータに変換してみます。
-- UnPivotのサンプル
select ID,Vals,Cols
from UnPivotSample
UnPivot(Vals for Cols in(Val1,Val2,Val3));
出力結果
ID Vals Cols
-- ---- ----
1 12 VAL1
1 11 VAL2
1 10 VAL3
3 30 VAL1
3 90 VAL2
5 50 VAL1
上記の出力結果では、Valsがnullの行が出力されてないですね。
UnPivotは、デフォルトでExclude nullsなため、
UnPivot対象がnullの行も出力するには、Include nullsを指定する必要があります。
-- Include nullsを指定したUnPivot
select ID,Vals,Cols
from UnPivotSample
UnPivot Include nulls
(Vals for Cols in(Val1,Val2,Val3));
出力結果
ID Vals Cols
-- ---- ----
1 12 VAL1
1 11 VAL2
1 10 VAL3
3 30 VAL1
3 90 VAL2
3 null VAL3
5 50 VAL1
5 null VAL2
5 null VAL3
UnPivotの構文は、下記のように理解しておくといいでしょう。
UnPivot(列値を表示する列名 for 元列の識別値を表示する列名 in(元列1,元列2,元列3))
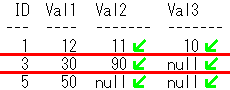
UnPivotのSQLのイメージは下記となります。
行ごとに区切る赤線を引いて、元列2と元列3を、元列1の下に移動させる黄緑線を引いてます。
 下記のように、元列の識別値を指定することもできます。
Val1列の元列の識別値をMoto1,Val2列の元列の識別値をMoto2,Val3列の元列の識別値をMoto3としてみます。
-- 元列の識別値を指定
select ID,Vals,Cols
from UnPivotSample
UnPivot(Vals for Cols in(Val1 as 'Moto1',
Val2 as 'Moto2',
Val3 as 'Moto3'));
出力結果
ID Vals Cols
-- ---- -----
1 12 Moto1
1 11 Moto2
1 10 Moto3
3 30 Moto1
3 90 Moto2
5 50 Moto1
下記のように、元列の識別値として数値型を指定し、
order by句でのソートキーの指定に使うこともできます。
-- 数値型のソートキーを持たせたUnPivot
select ID,Vals,SortKeys
from UnPivotSample
UnPivot(Vals for SortKeys in(Val1 as 1,
Val2 as 2,
Val3 as 3))
order by ID,SortKeys;
出力結果
ID Vals SortKeys
-- ---- --------
1 12 1
1 11 2
1 10 3
3 30 1
3 90 2
5 50 1
下記のように、元列の識別値として数値型と列名の両方を指定することもできます。
状況に応じて使い分けるといいでしょう。
-- 元列の識別値として数値型と列名の両方を指定
select ID,Vals,SortKeys,Moto
from UnPivotSample
UnPivot (Vals for (SortKeys,Moto)
in(Val1 as (1,'Moto1'),
Val2 as (2,'Moto2'),
Val3 as (3,'Moto3')))
order by ID,SortKeys;
出力結果
ID Vals SortKeys Moto
-- ---- -------- -----
1 12 1 Moto1
1 11 2 Moto2
1 10 3 Moto3
3 30 1 Moto1
3 90 2 Moto2
5 50 1 Moto1
下記のように、元列の識別値を指定することもできます。
Val1列の元列の識別値をMoto1,Val2列の元列の識別値をMoto2,Val3列の元列の識別値をMoto3としてみます。
-- 元列の識別値を指定
select ID,Vals,Cols
from UnPivotSample
UnPivot(Vals for Cols in(Val1 as 'Moto1',
Val2 as 'Moto2',
Val3 as 'Moto3'));
出力結果
ID Vals Cols
-- ---- -----
1 12 Moto1
1 11 Moto2
1 10 Moto3
3 30 Moto1
3 90 Moto2
5 50 Moto1
下記のように、元列の識別値として数値型を指定し、
order by句でのソートキーの指定に使うこともできます。
-- 数値型のソートキーを持たせたUnPivot
select ID,Vals,SortKeys
from UnPivotSample
UnPivot(Vals for SortKeys in(Val1 as 1,
Val2 as 2,
Val3 as 3))
order by ID,SortKeys;
出力結果
ID Vals SortKeys
-- ---- --------
1 12 1
1 11 2
1 10 3
3 30 1
3 90 2
5 50 1
下記のように、元列の識別値として数値型と列名の両方を指定することもできます。
状況に応じて使い分けるといいでしょう。
-- 元列の識別値として数値型と列名の両方を指定
select ID,Vals,SortKeys,Moto
from UnPivotSample
UnPivot (Vals for (SortKeys,Moto)
in(Val1 as (1,'Moto1'),
Val2 as (2,'Moto2'),
Val3 as (3,'Moto3')))
order by ID,SortKeys;
出力結果
ID Vals SortKeys Moto
-- ---- -------- -----
1 12 1 Moto1
1 11 2 Moto2
1 10 3 Moto3
3 30 1 Moto1
3 90 2 Moto2
5 50 1 Moto1
8 UnPivotの代用法
union allなどでUnPivotを代用
UnPivotの代用法としては、下記のようにunion allを使う方法があります。
-- UnPivotの代用 (union all)
with tmp(ID,Vals,SortKeys) as(
select ID,Val1,1 from UnPivotSample union all
select ID,Val2,2 from UnPivotSample union all
select ID,Val3,3 from UnPivotSample)
select ID,Vals,SortKeys
from tmp
order by ID,SortKeys;
出力結果
ID Vals SortKeys
-- ---- --------
1 12 1
1 11 2
1 10 3
3 30 1
3 90 2
3 null 3
5 50 1
5 null 2
5 null 3
下記のように連番表とクロスジョインさせる方法も、UnPivotの代用法として使えます。
-- UnPivotの代用 (連番表とクロスジョイン)
select a.ID,
case b.Cnter
when 1 then a.Val1
when 2 then a.Val2
when 3 then a.Val3 end as Vals,b.Cnter
from UnPivotSample a,
(select 1 as Cnter from dual union all
select 2 from dual union all
select 3 from dual) b
order by a.ID,b.Cnter;
出力結果
ID Vals Cnter
-- ---- -----
1 12 1
1 11 2
1 10 3
3 30 1
3 90 2
3 null 3
5 50 1
5 null 2
5 null 3
下記のようにsys.odciNumberListも、UnPivotの代用法として使えます。
ただし、この代用法では、元々どの列の値だったかが分からなくなります。
例えば、下記のselect文では、各Vals列が元々は、Val1列,Val2列,Val3列のどれだったかが分からないです。
そのため、order by句でソート順序を明示できなくなってしまいます。
-- UnPivotの代用 (sys.odciNumberList)
select ID,column_value as Vals
from UnPivotSample,table(sys.odciNumberList(Val1,Val2,Val3));
出力結果
ID Vals
-- ----
1 12
1 11
1 10
3 30
3 90
3 null
5 50
5 null
5 null
9 UnPivotと、UnPivotの代用法を比較
UnPivotの構文はシンプル
UnPivotと、UnPivotの代用法の比較結果として、
UnPivotの構文はシンプルで読みやすいので、UnPivotが使えるOracle11gR1以降では、UnPivotを使い、
UnPivotが使えないOracle10gなどでは、前述したUnPivotの代用法を使い分けるのがいいと思われます。
10 UnPivotのサンプル集
UnPivotの雛形
-- 基本的なUnPivot その1
with t(ID,Val1,Val2) as(
select 5,10,90 from dual union all
select 6,20,80 from dual union all
select 7,30,70 from dual)
select * from t
UnPivot(Vals for Cols in(Val1,Val2));
出力結果
ID Cols Vals
-- ---- ----
5 VAL1 10
5 VAL2 90
6 VAL1 20
6 VAL2 80
7 VAL1 30
7 VAL2 70
-- 基本的なUnPivot その2
with t(ID,Val1,Val2) as(
select 5,10,90 from dual union all
select 6,20,80 from dual union all
select 7,30,70 from dual)
select * from t
UnPivot(Vals for SortKeys
in(Val1 as 1,
Val2 as 2))
order by ID,SortKeys;
出力結果
ID SortKeys Vals
-- -------- ----
5 1 10
5 2 90
6 1 20
6 2 80
7 1 30
7 2 70
-- 基本的なUnPivot その3
with t(ID,Val1,Val2) as(
select 5,10,90 from dual union all
select 6,20,80 from dual union all
select 7,30,70 from dual)
select * from t
UnPivot(Vals for (SortKeys,Moto)
in(Val1 as (1,'Moto1'),
Val2 as (2,'Moto2')))
order by ID,SortKeys;
出力結果
ID SortKeys Moto Vals
-- -------- ----- ----
5 1 Moto1 10
5 2 Moto2 90
6 1 Moto1 20
6 2 Moto2 80
7 1 Moto1 30
7 2 Moto2 70
-- 複数列でUnPivot その1
with t(ID,Val1,Name1,Val2,Name2) as(
select 1,11,'AA',66,'FF' from dual union all
select 2,22,'BB',77,'GG' from dual union all
select 3,33,'CC',88,'HH' from dual union all
select 4,44,'DD',99,'II' from dual union all
select 5,55,'EE',20,'JJ' from dual)
select * from t
UnPivot((Vals,Names) for Cols
in((Val1,Name1) as 'V1N1',
(Val2,Name2) as 'V2N2'));
出力結果
ID Cols Vals Names
-- ---- ---- -----
1 V1N1 11 AA
1 V2N2 66 FF
2 V1N1 22 BB
2 V2N2 77 GG
3 V1N1 33 CC
3 V2N2 88 HH
4 V1N1 44 DD
4 V2N2 99 II
5 V1N1 55 EE
5 V2N2 20 JJ
-- 複数列でUnPivot その2
with t(ID,Val1,Name1,Val2,Name2) as(
select 1,11,'AA',66,'FF' from dual union all
select 2,22,'BB',77,'GG' from dual union all
select 3,33,'CC',88,'HH' from dual union all
select 4,44,'DD',99,'II' from dual union all
select 5,55,'EE',20,'JJ' from dual)
select * from t
UnPivot((Vals,Names) for (Col1,Col2)
in((Val1,Name1) as ('V1','N1'),
(Val2,Name2) as ('V2','N2')));
出力結果
ID Col1 Col2 Vals Names
-- ---- ---- ---- -----
1 V1 N1 11 AA
1 V2 N2 66 FF
2 V1 N1 22 BB
2 V2 N2 77 GG
3 V1 N1 33 CC
3 V2 N2 88 HH
4 V1 N1 44 DD
4 V2 N2 99 II
5 V1 N1 55 EE
5 V2 N2 20 JJ
-- UnPivotしてPivot
with t(ID,Val1,Val2,Val3,Val4) as(
select 'Sat',10,15,20,25 from dual union all
select 'Sun',30,35,40,45 from dual union all
select 'Mon',50,55,60,65 from dual)
select * from t
UnPivot(Vals for Cols in(Val1,Val2,Val3,Val4))
Pivot (max(Vals) for ID in('Sat' as Sat,'Sun' as Sun,'Mon' as Mon))
order by Cols;
出力結果
Cols Sat Sun Mon
---- --- --- ---
VAL1 10 30 50
VAL2 15 35 55
VAL3 20 40 60
VAL4 25 45 65
参考リソース