図でイメージするOracleのSQL全集の元原稿
第8回 PivotとUnPivot
第9回 Model句
[OracleのSQLの各機能をイメージを交えて解説]
連載のテーマ
SQLの初心者から上級者までを広く対象読者として、
SQLの各機能の典型的な使用例を、学習効率が高いと思われる順序で、SQLのイメージを交えて解説します。
SQLをイメージ付で理解し、SQLをイメージで素早く考えられるようになることを目標とします。
動作確認環境
Oracle Database 11g Release 11.2.0.1.0 (Windows 32ビット版)
今回のテーマ
今回は、下記のOracleのSQL文の評価順序においての、
8番目のmodel句の使用例と、私のSQLのイメージを解説します。
1番目 from句
2番目 where句 (結合条件)
3番目 start with句
4番目 connect by句
5番目 where句 (行のフィルタ条件)
6番目 group by句
7番目 having句
8番目 model句
9番目 select句
10番目 union、minus、intersectなどの集合演算
11番目 order by句
目次
01 Model句とは
配列のように、Select文の結果セットを扱う
Model句はOracle10gのSQLの新機能で、
Select文でPL/SQLの結合配列のように、Select文の結果セットを扱うことができます。
having句の次にmodel句が評価されます。
●Model句のメリット
union allを使ったり、親言語(C#やJavaなど)やPL/SQLで、
求めていた結果を、SQLで容易に求めることができるようになります。
●Model句の効果的な使用例
SQLで下記のようなことを行うケースです。
・集計行の追加
・正規表現関数の繰り返し実行
・複雑な計算結果を使った計算
なお、Model句を使ったSelect文は、中間結果を表示してのデバッグがやりづらいため、
再帰With句、分析関数、表関数、相関サブクエリなどを使う選択肢も考慮した上で
Model句を使ったSelect文を使用するといいです。
02 HelloWorld
Model句の基本的な構文
Model句でのHelloWorldを解説します。
-- Model句でHelloWorld その1
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,
1 as soeji from dual)
model
dimension by(soeji)
measures(ArrValue)
rules(ArrValue[1] = 'Hello World');
出力結果
ArrValue soeji
----------- -----
Hello World 1
それぞれの文法について解説します。
●model
Model句を使用する際のキーワードです。
Model句を使用するには必須です。
●dimension by
dimensionは、次元という意味です。
PL/SQLやC#やJavaなどにおける、配列の添字だと理解しておいて問題ないでしょう。
Fortranではdimensionキーワードを使って配列を定義するようです。
Model句を使用するには必須です。
●measures
配列が、どんな値の配列かを指定します。
Model句を使用するには必須です。
●rules
配列の値を操作する式を記述します。
それでは、サンプルを解説します。
まず、インラインビューの実行結果を見てみます。
-- インラインビューの中身
select 'abcdefghijklmn' as ArrValue,
1 as soeji from dual;
インラインビューの実行結果
ArrValue soeji
-------------- -----
abcdefghijklmn 1
次に、
model
dimension by(soeji)
measures(ArrValue)
によって、soejiを添字として、ArrValueを配列値とした、配列が作成されるイメージです。
そして、rules(ArrValue[1] = 'Hello World')によって、
ArrValue[1]の値が、Hello Worldに上書きされるイメージです。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
-- Model句でHelloWorld その2
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,
1 as soeji from dual)
model
dimension by(soeji)
measures(ArrValue)
rules(ArrValue[1] = 'Hello World',
ArrValue[2] = 'Hello Model');
出力結果
ArrValue soeji
----------- -----
Hello World 1
Hello Model 2
rulesは、デフォルトでupsert(あればupdate,なければinsert)です。
なので、
ArrValue[1] = 'Hello World' によって、ArrValue[1]がupdateされ、
ArrValue[2] = 'Hello Model' によって、ArrValue[2]がinsertされます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
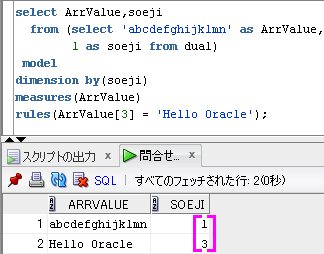
-- Model句でHelloWorld その3
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,
1 as soeji from dual)
model
dimension by(soeji)
measures(ArrValue)
rules(ArrValue[3] = 'Hello Oracle');
出力結果
ArrValue soeji
-------------- -----
abcdefghijklmn 1
Hello Oracle 3
Model句では、配列の添字は、連続してなくても問題ないです。
SQLのイメージは、下のようになります。
dimension by(soeji)に対応する配列の添字を紫色でイメージしてます。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
-- Model句でHelloWorld その4
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,
1 as soeji from dual)
model return updated rows
dimension by(soeji)
measures(ArrValue)
rules(ArrValue[4] = 'Hello OTN');
出力結果
ArrValue soeji
--------- -----
Hello OTN 4
model return updated rowsとすると、
rules句によって、更新(updateかinsert)された行のみ出力することができます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
-- Model句でHelloWorld その4
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,
1 as soeji from dual)
model return updated rows
dimension by(soeji)
measures(ArrValue)
rules(ArrValue[4] = 'Hello OTN');
出力結果
ArrValue soeji
--------- -----
Hello OTN 4
model return updated rowsとすると、
rules句によって、更新(updateかinsert)された行のみ出力することができます。
03 集計行の追加
Model句での行の追加
集計行の追加は、Model句の効果的な使用例の1つです。
create table AddTotal(ID,Val) as
select 1, 10 from dual union
select 2, 80 from dual union
select 3,300 from dual union
select 4,600 from dual;
集計行も表示してみます。
-- Model句で集計行の追加 その1
select ID,Val
from AddTotal
model
dimension by(ID)
measures(Val)
rules(
Val[null] = Val[1]+Val[2]+Val[3]+Val[4]);
出力結果
ID Val
---- ---
1 10
2 80
3 300
4 600
null 990
Model句を使わない方法としては、RollUpを使う方法や、union allを使う方法があります。
-- RollUpで集計行の追加 その1
select ID,sum(Val) as Val
from AddTotal
group by RollUp(ID);
-- union allで集計行の追加 その1
select ID,Val
from AddTotal
union all
select null,Sum(Val)
from addTotal;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
前問をアレンジして、
今度は、IDが3または4の行のみを集計対象として、集計行を表示してみます。
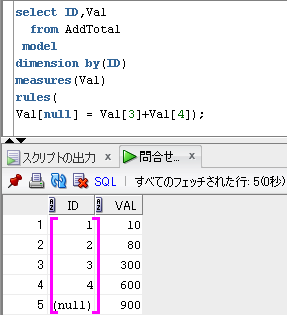
-- Model句で集計行の追加 その2
select ID,Val
from AddTotal
model
dimension by(ID)
measures(Val)
rules(
Val[null] = Val[3]+Val[4]);
出力結果
ID Val
---- ---
1 10
2 80
3 300
4 600
null 900
SQLのイメージは、下のようになります。
dimension by(ID)に対応する配列の添字を紫色でイメージしてます。
 Model句を使わない方法としては、RollUpを使う方法や、union allを使う方法がありますが、
上記のSQLと比較すると、Model句による行の追加は、他の方法と比べてシンプルになることが多いと分かります。
-- RollUpで集計行の追加 その2
select ID,
case grouping(ID) when 0 then sum(Val)
else sum(case when ID in(3,4) then Val end)
end as Val
from AddTotal
group by RollUp(ID);
-- union allで集計行の追加 その2
select ID,Val
from addTotal
union all
select null,Sum(Val)
from AddTotal
where ID in(3,4);
Model句を使わない方法としては、RollUpを使う方法や、union allを使う方法がありますが、
上記のSQLと比較すると、Model句による行の追加は、他の方法と比べてシンプルになることが多いと分かります。
-- RollUpで集計行の追加 その2
select ID,
case grouping(ID) when 0 then sum(Val)
else sum(case when ID in(3,4) then Val end)
end as Val
from AddTotal
group by RollUp(ID);
-- union allで集計行の追加 その2
select ID,Val
from addTotal
union all
select null,Sum(Val)
from AddTotal
where ID in(3,4);
04 Model句でPivot
Model句で行持ちを列持ちに変換
create table ModelPivot(ID,Seq,Val) as
select 10,'01','AAAAA' from dual union all
select 10,'02','BBBBB' from dual union all
select 10,'03','CCCCC' from dual union all
select 20,'01','DDDDD' from dual union all
select 20,'02','EEEEE' from dual union all
select 30,'02','FFFFF' from dual union all
select 30,'03','GGGGG' from dual;
Model句でPivotを模倣してみます。
-- 模倣対象のPivotを使ったSelect文
select * from ModelPivot
Pivot(max(Val) for Seq in('01' as Val01,
'02' as Val02,
'03' as Val03))
order by ID;
出力結果
ID Val01 Val02 Val03
-- ----- ----- -----
10 AAAAA BBBBB CCCCC
20 DDDDD EEEEE null
30 null FFFFF GGGGG
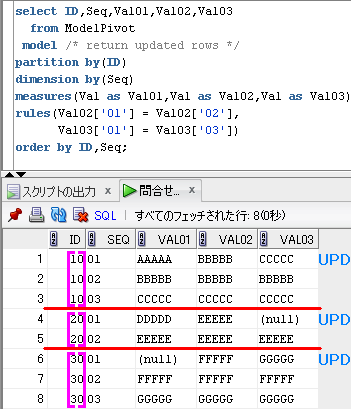
-- Model句でPivotを模倣
select ID,Val01,Val02,Val03
from ModelPivot
model return updated rows
partition by(ID)
dimension by(Seq)
measures(Val as Val01,Val as Val02,Val as Val03)
rules(Val02['01'] = Val02['02'],
Val03['01'] = Val03['03'])
order by ID;
partition by(ID) は、
「rules句が行う処理をパーティションごとに分割する」という意味です。
dimension by(Seq) でSeqを添字とし、
measures句で、Valをそれぞれ、Val01,Val02,Val03 として複製し、
rules句で、添字が01の行に、必要な値を集めてます。
model return updated rows を指定してますので、更新された行のみ出力されます。
SQLのイメージは、下のようになります。
partition by(ID) で、赤線を引いて、
dimension by(Seq)に対応する配列の添字を紫色でイメージしてます。
05 Model句でUnPivot
Model句で列持ちを行持ちに変換
create table ModelUnPivot(ID,ColA,ColB,ColC) as
select 10,'AAAAAA','BBBBBB','CCCCCC' from dual union
select 30,'DDDDDD','EEEEEE','FFFFFF' from dual;
Model句でUnPivotを模倣してみます。
-- 模倣対象のUnPivotを使ったSelect文
select ID,soeji,OutVal
from ModelUnPivot
UnPivot(OutVal for soeji in(ColA as 1,ColB as 2,ColC as 3))
order by ID,soeji;
出力結果
ID soeji OutVal
-- ----- ------
10 1 AAAAAA
10 2 BBBBBB
10 3 CCCCCC
30 1 DDDDDD
30 2 EEEEEE
30 3 FFFFFF
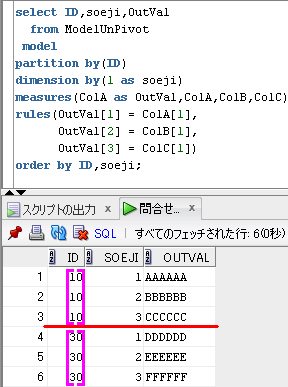
-- Model句でUnPivotを模倣
select ID,soeji,OutVal
from ModelUnPivot
model
partition by(ID)
dimension by(1 as soeji)
measures(ColA as OutVal,ColA,ColB,ColC)
rules(OutVal[1] = ColA[1],
OutVal[2] = ColB[1],
OutVal[3] = ColC[1])
order by ID,soeji;
partition by(ID) で、
rules句が行う処理をIDごとに分割してます。
次に、dimension by(1 as soeji) で整数値を配列の添字とし、
measures句で、OutValという出力用の列を用意し、
rules句で、配列の添字を増やしつつ、ColA,ColB,ColCの各値を設定してます。
SQLのイメージは、下のようになります。
partition by(ID) で、赤線を引いて、
dimension by(1 as soeji)に対応する配列の添字を紫色でイメージしてます。
06 all_objectsやall_catalogやdictの代用
Model句で連番表の作成
1以上の整数の連番が欲しいことは、たまにあります。
all_objectsやall_catalogやdictといった
特に権限がなくてもアクセスできるデータディクショナリを使って、連番表を作成することが多いですが、
Model句の機能を使って連番表を作成してみます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
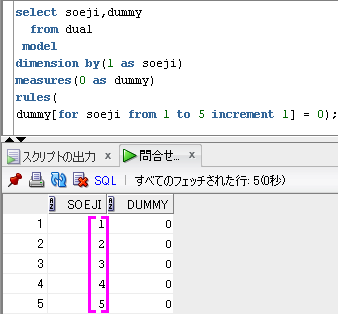
-- forコンストラクトでfrom toを使う方法
select soeji,dummy
from dual
model
dimension by(1 as soeji)
measures(0 as dummy)
rules(
dummy[for soeji from 1 to 5 increment 1] = 0);
出力結果
soeji dummy
----- -----
1 0
2 0
3 0
4 0
5 0
forコンストラクトでfrom toを使って、開始値と終了値と増分値を指定することができます。
dummy[for soeji from 1 to 5 increment 1] = 0は、開始値が1で終了値が5で増分値が1なので、
soejiを添字とした配列の、添字の1,2,3,4,5のdummy列に0がupsert(あればupdate,なければinsert)されます。
SQLのイメージは、下のようになります。
dimension by(1 as soeji)に対応する配列の添字を紫色でイメージしてます。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
-- iterateを使う方法
select soeji,dummy
from dual
model
dimension by(1 as soeji)
measures(0 as dummy)
rules iterate (5)
(dummy[iteration_number+1] = 0);
上記のように、iterateを使って連番表を作成することもできます。
rules iterate (5)と記述すると、rulesが5回評価されます。
そして、ruleが1回評価されるごとにインクリメントされる値として、iteration_numberがあります。
なお、iteration_numberは、0から開始されます。
そして、上記のSQLでは、rulesが5回評価されますので、
dummy[iteration_number+1] = 0を指定して1から5までの連番を作成してます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
-- forコンストラクトでinを使う方法
select soeji,dummy
from dual
model
dimension by(1 as soeji)
measures(0 as dummy)
rules(
dummy[for soeji in(1,2,3,4,5)] = 0);
forコンストラクトでinを使う方法もあります。
配列の添字によっては、inを使ったほうがシンプルなSQLとなります。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
-- 位置参照を何度も使う方法
select soeji,dummy
from dual
model
dimension by(1 as soeji)
measures(0 as dummy)
rules(
dummy[1] = 0,
dummy[2] = 0,
dummy[3] = 0,
dummy[4] = 0,
dummy[5] = 0);
位置参照を何度も使っても同じ結果を取得できますが、
forコンストラクトを使ったほうがシンプルなSQLとなります。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
-- iterateを使う方法
select soeji,dummy
from dual
model
dimension by(1 as soeji)
measures(0 as dummy)
rules iterate (5)
(dummy[iteration_number+1] = 0);
上記のように、iterateを使って連番表を作成することもできます。
rules iterate (5)と記述すると、rulesが5回評価されます。
そして、ruleが1回評価されるごとにインクリメントされる値として、iteration_numberがあります。
なお、iteration_numberは、0から開始されます。
そして、上記のSQLでは、rulesが5回評価されますので、
dummy[iteration_number+1] = 0を指定して1から5までの連番を作成してます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
-- forコンストラクトでinを使う方法
select soeji,dummy
from dual
model
dimension by(1 as soeji)
measures(0 as dummy)
rules(
dummy[for soeji in(1,2,3,4,5)] = 0);
forコンストラクトでinを使う方法もあります。
配列の添字によっては、inを使ったほうがシンプルなSQLとなります。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
-- 位置参照を何度も使う方法
select soeji,dummy
from dual
model
dimension by(1 as soeji)
measures(0 as dummy)
rules(
dummy[1] = 0,
dummy[2] = 0,
dummy[3] = 0,
dummy[4] = 0,
dummy[5] = 0);
位置参照を何度も使っても同じ結果を取得できますが、
forコンストラクトを使ったほうがシンプルなSQLとなります。
07 期間内の日付一覧の作成
Model句で連続した日付の作成
前問では、数値型の連番を作成したので、今度は、
2019年12月30日から2020年1月3日までの連続した日付を作成してみます。
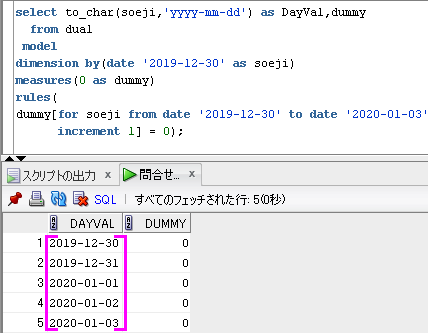
-- 増分値の指定で数値型を使用
select to_char(soeji,'yyyy-mm-dd') as DayVal
from dual
model
dimension by(date '2019-12-30' as soeji)
measures(0 as dummy)
rules(
dummy[for soeji from date '2019-12-30' to date '2020-01-03'
increment 1] = 0);
出力結果
DayVal
----------
2019-12-30
2019-12-31
2020-01-01
2020-01-02
2020-01-03
まず、Model句のdimension by(date '2019-12-30' as soeji)とmeasures(0 as dummy)によって、
Date型のsoejiを添字として、0を要素名dummyとして持つ配列を用意してます。
プログラム言語の配列には、添字に数値型しか指定できないものがありますが、
Model句のdimension by句では、数値型や日付型や文字型を使用できます。
次に、Model句のrules句でのdummy[for soeji from '2019-12-30' to '2020-01-03' increment 1] = 0によって、
soejiを添字とした配列の、添字の2019-12-30,2019-12-31,2020-01-01,2020-01-02,2020-01-03
のdummy列に0をupsert(あればupdate,なければinsert)してます。
SQLのイメージは、下のようになります。
dimension by(date '2019-12-30' as soeji)に対応する配列の添字を紫色でイメージしてます。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
下記のように、増分値の指定でInterVal型を使用することもできます。
もちろん、InterVal '5' minuteやInterVal '1' hourなどといった使い方も可能です。
-- 増分値の指定でInterVal型を使用
select to_char(soeji,'yyyy-mm-dd') as DayVal
from dual
model
dimension by(date '2019-12-30' as soeji)
measures(0 as dummy)
rules(
dummy[for soeji from date '2019-12-30' to date '2020-01-03'
increment InterVal '1' day] = 0);
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
下記のように、forコンストラクトを複数列で使用することもできます。
1列目が連続した日付で、2列目を数値型の連番とした行を作成してみます。
-- forコンストラクトを複数列で使用
select to_char(soeji1,'yyyy-mm-dd') as soeji1,soeji2
from dual
model
dimension by(date '2019-12-31' as soeji1, 1 as soeji2)
measures(0 as dummy)
rules(
dummy[for soeji1 from date '2019-12-31' to date '2020-01-01' increment 1,
for soeji2 from 1 to 3 increment 1] = 0);
出力結果
soeji1 soeji2
---------- ------
2019-12-31 1
2019-12-31 2
2019-12-31 3
2020-01-01 1
2020-01-01 2
2020-01-01 3
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
下記のように、増分値の指定でInterVal型を使用することもできます。
もちろん、InterVal '5' minuteやInterVal '1' hourなどといった使い方も可能です。
-- 増分値の指定でInterVal型を使用
select to_char(soeji,'yyyy-mm-dd') as DayVal
from dual
model
dimension by(date '2019-12-30' as soeji)
measures(0 as dummy)
rules(
dummy[for soeji from date '2019-12-30' to date '2020-01-03'
increment InterVal '1' day] = 0);
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
下記のように、forコンストラクトを複数列で使用することもできます。
1列目が連続した日付で、2列目を数値型の連番とした行を作成してみます。
-- forコンストラクトを複数列で使用
select to_char(soeji1,'yyyy-mm-dd') as soeji1,soeji2
from dual
model
dimension by(date '2019-12-31' as soeji1, 1 as soeji2)
measures(0 as dummy)
rules(
dummy[for soeji1 from date '2019-12-31' to date '2020-01-01' increment 1,
for soeji2 from 1 to 3 increment 1] = 0);
出力結果
soeji1 soeji2
---------- ------
2019-12-31 1
2019-12-31 2
2019-12-31 3
2020-01-01 1
2020-01-01 2
2020-01-01 3
08 Model句でPartitioned Outer Join
Model句でパーティションごとに行の補完
create table LPOTable(ID,Key,Name) as
select 'AA',10,'aaaa' from dual union all
select 'AA',20,'bbbb' from dual union all
select 'BB',10,'cccc' from dual union all
select 'CC',10,'dddd' from dual union all
select 'CC',30,'eeee' from dual;
Model句で、Partitioned Outer Joinを模倣してみます。
-- 模倣対象のPartitioned Outer Joinを使ったSelect文
select b.ID,a.HokanKey,b.Name
from (select 10 as HokanKey from dual union all
select 20 from dual union all
select 30 from dual) a
Left Outer Join LPOTable b
partition by (b.ID)
on (a.HokanKey = b.Key)
order by b.ID,a.HokanKey;
出力結果
ID HokanKey Name
-- -------- ----
AA 10 aaaa
AA 20 bbbb
AA 30 null
BB 10 cccc
BB 20 null
BB 30 null
CC 10 dddd
CC 20 null
CC 30 eeee
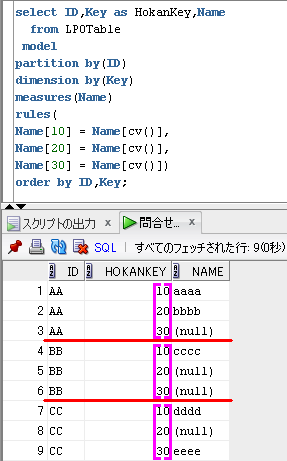
-- Model句でPartitioned Outer Joinを模倣
select ID,Key as HokanKey,Name
from LPOTable
model
partition by(ID)
dimension by(Key)
measures(Name)
rules(
Name[10] = Name[cv()],
Name[20] = Name[cv()],
Name[30] = Name[cv()])
order by ID,Key;
cv関数は、dimension byで指定した添字を引数に取って、rules句の左辺で指定した添字を返します。
角括弧の中であれば、cv関数の引数は省略可能になります。
例えば、Name[10] = Name[cv()]
は、 Name[10] = Name[cv(Key)] と同じ意味です。
partition by(ID)
dimension by(Key)
rules(
Name[10] = Name[cv()],
Name[20] = Name[cv()],
Name[30] = Name[cv()])
によって、IDごとで、
Keyが10の値があれば、Nameの値を上書きで代入、なければ、Nameの値をnullに設定
Keyが20の値があれば、Nameの値を上書きで代入、なければ、Nameの値をnullに設定
Keyが30の値があれば、Nameの値を上書きで代入、なければ、Nameの値をnullに設定
といった処理が行われます。
SQLのイメージは、下のようになります。
partition by(ID) で、赤線を引いて、
dimension by(Key)に対応する配列の添字を紫色でイメージしてます。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
rules句の左辺での、添字の指定方法には、下記のような指定方法もあります。
-- 添字の指定方法
select ID,Key as HokanKey,N1,N2,N3
from LPOTable
model
partition by(ID)
dimension by(Key)
measures(Name as N1,Name as N2,Name as N3)
rules(
N1[for Key in(10,20,30)] = N1[cv()],
N2[for Key from 10 to 30 increment 10] = N2[cv()],
N3[for Key in(select * from table(sys.odciNumberList(10,20,30)))] = N3[cv()])
order by ID,Key;
出力結果
ID HokanKey N1 N2 N3
-- -------- ---- ---- ----
AA 10 aaaa aaaa aaaa
AA 20 bbbb bbbb bbbb
AA 30 null null null
BB 10 cccc cccc cccc
BB 20 null null null
BB 30 null null null
CC 10 dddd dddd dddd
CC 20 null null null
CC 30 eeee eeee eeee
N1[for Key in(10,20,30)] は、値を列挙してます。
N2[for Key from 10 to 30 increment 10] は、forコンストラクトで初期値と終了値と増分を指定してます。
N3[for Key in(select * from table(sys.odciNumberList(10,20,30)))] は、Select文の結果を使用してます。
下記のように、多次元配列でもSelect文の結果を使用できます。
-- 多次元配列でSelect文の結果を使用
select *
from dual
model
dimension by(0 as Key1,0 as Key2)
measures(0 as dummy)
rules(
dummy[for (Key1,Key2) in(select 10,50 from dual)] = 0);
出力結果
Key1 Key2 dummy
---- ---- -----
0 0 0
10 50 0
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
rules句の左辺での、添字の指定方法には、下記のような指定方法もあります。
-- 添字の指定方法
select ID,Key as HokanKey,N1,N2,N3
from LPOTable
model
partition by(ID)
dimension by(Key)
measures(Name as N1,Name as N2,Name as N3)
rules(
N1[for Key in(10,20,30)] = N1[cv()],
N2[for Key from 10 to 30 increment 10] = N2[cv()],
N3[for Key in(select * from table(sys.odciNumberList(10,20,30)))] = N3[cv()])
order by ID,Key;
出力結果
ID HokanKey N1 N2 N3
-- -------- ---- ---- ----
AA 10 aaaa aaaa aaaa
AA 20 bbbb bbbb bbbb
AA 30 null null null
BB 10 cccc cccc cccc
BB 20 null null null
BB 30 null null null
CC 10 dddd dddd dddd
CC 20 null null null
CC 30 eeee eeee eeee
N1[for Key in(10,20,30)] は、値を列挙してます。
N2[for Key from 10 to 30 increment 10] は、forコンストラクトで初期値と終了値と増分を指定してます。
N3[for Key in(select * from table(sys.odciNumberList(10,20,30)))] は、Select文の結果を使用してます。
下記のように、多次元配列でもSelect文の結果を使用できます。
-- 多次元配列でSelect文の結果を使用
select *
from dual
model
dimension by(0 as Key1,0 as Key2)
measures(0 as dummy)
rules(
dummy[for (Key1,Key2) in(select 10,50 from dual)] = 0);
出力結果
Key1 Key2 dummy
---- ---- -----
0 0 0
10 50 0
09 count(distinct Val) over(order by SortKey)の代用
rules句で下界を集約
US-OTNで何度か見かけた問題です。訪問者が、リピーターか新規かを見分ける時に使うSQLのようです。
create table VisiterT(SortKey,Visit) as
select 10,'AAA' from dual union
select 20,'BBB' from dual union
select 30,'AAA' from dual union
select 40,'BBB' from dual union
select 50,'CCC' from dual union
select 60,'CCC' from dual union
select 70,'DDD' from dual union
select 80,'AAA' from dual;
-- ORA-30487エラーになるSelect文
select SortKey,Visit,
count(distinct Visit) over(order by SortKey) as DisVisit
from VisiterT
order by SortKey;
count(distinct Visit) over(order by SortKey) as DisVisit
*
行2でエラーが発生しました。: ORA-30487: ここでORDER BYは使用できません。
分析関数でdistinctオプションを使用して、order byを指定するとORA-30487エラーになりますが、
どうにかして同じ結果を取得してみます。
-- 分析関数を使った代替方法
with tmp as(
select SortKey,Visit,
case Row_Number() over(partition by Visit order by SortKey)
when 1 then 1 else 0 end as WillSum
from VisiterT)
select SortKey,Visit,sum(WillSum) over(order by SortKey) as DisVisit
from tmp
order by SortKey;
-- 相関サブクエリを使った代替方法
select SortKey,Visit,
(select count(distinct b.Visit)
from VisiterT b
where b.SortKey <= a.SortKey) as DisVisit
from VisiterT a
order by SortKey;
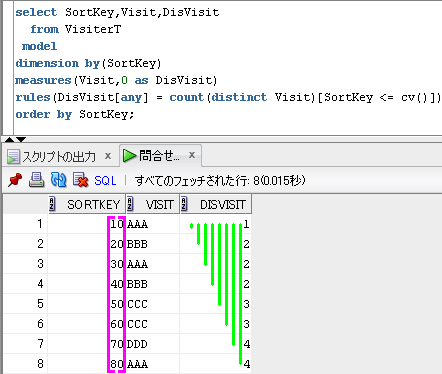
-- rules句で下界を集約
select SortKey,Visit,DisVisit
from VisiterT
model
dimension by(SortKey)
measures(Visit,0 as DisVisit)
rules(DisVisit[any] = count(distinct Visit)[SortKey <= cv()])
order by SortKey;
出力結果
SortKey Visit DisVisit
------- ----- --------
10 AAA 1 ← AAAで1
20 BBB 2 ← AAA,BBBで2
30 AAA 2 ← AAA,BBBで2
40 BBB 2 ← AAA,BBBで2
50 CCC 3 ← AAA,BBB,CCCで3
60 CCC 3 ← AAA,BBB,CCCで3
70 DDD 4 ← AAA,BBB,CCC,DDDで4
80 AAA 4 ← AAA,BBB,CCC,DDDで4
DisVisit[any] によって、配列の全ての添字を対象として、
count(distinct Visit)[SortKey <= cv()]) を求めてます。
count(distinct Visit)[SortKey <= cv()]) で集約関数の対象となるのは、
SortKey <= cv() が成立する行のみとなります。
結果として、相関サブクエリを使った代替方法と似た記述になります。
SQLのイメージは、下のようになります。
dimension by(SortKey)に対応する配列の添字を紫色でイメージしてます。
10 Model句でListAgg関数(集約関数)
iterateとuntilを使った繰り返し処理
create table EmuListAggT(ID,SortKey,Str) as
select 1,10,'AA' from dual union all
select 1,35,'BB' from dual union all
select 2,10,'CC' from dual union all
select 2,30,'DD' from dual union all
select 2,35,'CC' from dual union all
select 3,10,'EE' from dual;
Model句でListAgg関数(集約関数)を模倣してみます。
-- 模倣対象のListAgg関数(集約関数)を使ったSelect文
select ID,ListAgg(Str,',') WithIn group(order by SortKey) as ListStr
from EmuListAggT
group by ID
order by ID;
出力結果
ID ListStr
-- --------
1 AA,BB
2 CC,DD,CC
3 EE
-- 添字の0番に集める方法
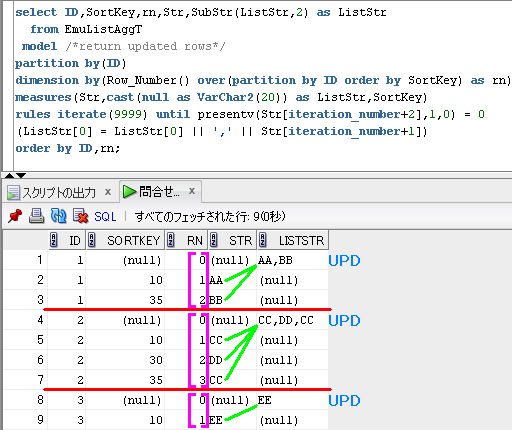
select ID,SubStr(ListStr,2) as ListStr
from EmuListAggT
model return updated rows
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(Str,cast(null as VarChar2(20)) as ListStr)
rules iterate(9999) until presentv(Str[iteration_number+2],1,0) = 0
(ListStr[0] = ListStr[0] || ',' || Str[iteration_number+1])
order by ID;
model return updated rowsで集約した行のみを出力するようにしてます。
iterateとuntilを使ったときの処理順序は、下記となります。
処理1 iteration_numberを宣言 (初期値 = 0)
処理2 rule適用
処理3 終了条件判定
処理4 iteration_numberをインクリメント
処理5 処理2へ戻る
終了条件判定は、until presentv(Str[iteration_number+2],1,0) = 0 とし、
Str[iteration_number+2]が、ベースのクエリからのプレゼント(贈り物)でなかったら、
終了するようにしてます。
SQLのイメージは、下のようになります。
partition by(ID) で、赤線を引いて、
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
に対応する配列の添字を紫色でイメージしてます。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
添字の0番ではなく、添字の1番に集めてもいいです。
-- 添字の1番に集める方法
select ID,SubStr(ListStr,2) as ListStr
from EmuListAggT
model return updated rows
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(Str,cast(null as VarChar2(20)) as ListStr)
rules iterate(9999) until presentv(Str[iteration_number+2],1,0) = 0
(ListStr[1] = ListStr[1] || ',' || Str[iteration_number+1])
order by ID;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
添字の0番ではなく、添字の1番に集めてもいいです。
-- 添字の1番に集める方法
select ID,SubStr(ListStr,2) as ListStr
from EmuListAggT
model return updated rows
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(Str,cast(null as VarChar2(20)) as ListStr)
rules iterate(9999) until presentv(Str[iteration_number+2],1,0) = 0
(ListStr[1] = ListStr[1] || ',' || Str[iteration_number+1])
order by ID;
11 Model句でListAgg関数(集約関数、distinct)
measures句で分析関数の使用
Model句でListAgg関数(集約関数、distinct)を模倣してみます。
-- ORA-30482エラーになるSelect文
select ID,ListAgg(distinct Str,',') WithIn group(order by SortKey) as ListStr
from EmuListAggT
group by ID
order by ID;
*
行1でエラーが発生しました。:
ORA-30482: この機能にDISTINCTオプションは使用できません
ListAgg関数でdistinctオプションを指定するとORA-30482エラーになりますが、
Model句を使って、同じ結果を取得してみます。
-- measures句で分析関数の使用
select ID,SubStr(ListStr,2) as ListStr
from EmuListAggT
model return updated rows
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(case Row_Number() over(partition by ID,Str order by SortKey)
when 1 then Str end as Str,
cast(null as VarChar2(20)) as ListStr)
rules iterate(9999) until presentv(Str[iteration_number+2],1,0) = 0
(ListStr[0] = ListStr[0] || nvl2(Str[iteration_number+1] ,
',' || Str[iteration_number+1] , null))
order by ID;
出力結果
ID ListStr
-- --------
1 AA,BB
2 CC,DD
3 EE
measures句で、単純case式とRow_Number関数を組み合わせて、
重複したStrの2つ目以降はnullになるようにしてから、
rules句で、nvl2関数で場合分けしつつ集約してます。
12 Model句でListAgg関数(分析関数)
iterateとanyの組み合わせ
Model句でListAgg関数(分析関数)を模倣してみます。
-- 模倣対象のListAgg関数(分析関数)を使ったSelect文
select ID,SortKey,Str,
ListAgg(Str,',') WithIn group(order by SortKey)
over(partition by ID) as ListStr
from EmuListAggT
order by ID,SortKey;
出力結果
ID SortKey Str ListStr
-- ------- --- --------
1 10 AA AA,BB
1 35 BB AA,BB
2 10 CC CC,DD,CC
2 30 DD CC,DD,CC
2 35 CC CC,DD,CC
3 10 EE EE
-- iterateとanyの組み合わせ
select ID,SortKey,Str,SubStr(ListStr,2) as ListStr
from EmuListAggT
model
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(SortKey,Str,cast(null as VarChar2(20)) as ListStr)
rules iterate(9999) until presentv(Str[iteration_number+2],1,0) = 0
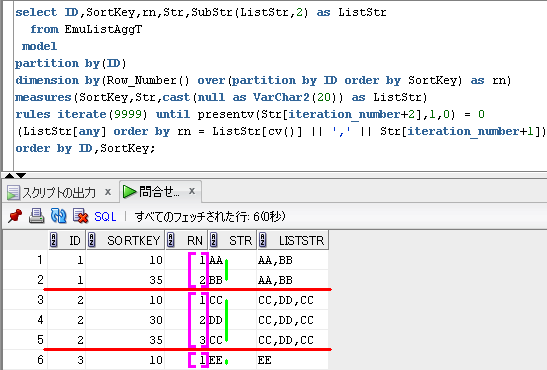
(ListStr[any] order by rn = ListStr[cv()] || ',' || Str[iteration_number+1])
order by ID,SortKey;
iterateとanyの組み合わせで、各行のListStr列に集約してます。
SQLのイメージは、下のようになります。
partition by(ID) で、赤線を引いて、
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
に対応する配列の添字を紫色でイメージしてます。
13 Model句でListAgg関数(分析関数、OrderBy)
rules句でルールの評価順序を指定
Model句でListAgg関数(分析関数、OrderBy)を模倣してみます。
-- ORA-30487エラーになるSelect文
select ID,SortKey,Str,
ListAgg(Str,',') WithIn group(order by SortKey)
over(partition by ID order by SortKey) as ListStr
from EmuListAggT
order by ID;
*
行3でエラーが発生しました。:
ORA-30487: ここでORDER BYは使用できません。
ListAgg関数を分析関数として使用し、OrderByを指定するとORA-30487エラーになりますが、
どうにかして同じ結果を取得してみます。
-- rules句でルールの評価順序を指定
select ID,SortKey,Str,ListStr
from EmuListAggT
model
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(SortKey,Str,cast(null as VarChar2(20)) as ListStr)
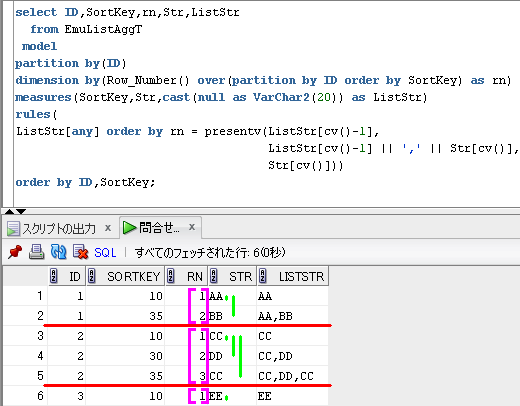
rules(
ListStr[any] order by rn = presentv(ListStr[cv()-1],
ListStr[cv()-1] || ',' || Str[cv()],
Str[cv()]))
order by ID,SortKey;
出力結果
ID SortKey Str ListStr
-- ------- --- --------
1 10 AA AA
1 35 BB AA,BB
2 10 CC CC
2 30 DD CC,DD
2 35 CC CC,DD,CC
3 10 EE EE
Row_Number関数で作成した連番を使って、
最初からセルが存在したかどうか、
いいかえれば、セルがベースのクエリからのプレゼント(贈り物)かどうかを、
presentv関数で判断しつつ、文字列を順番に連結させてます。
連結順序が重要なので、
ListStr[any] order by rn
といった形で、order byでルールの評価順序を指定してます。
SQLのイメージは、下のようになります。
partition by(ID) で、赤線を引いて、
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
に対応する配列の添字を紫色でイメージしてます。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
09 count(distinct Val) over(order by SortKey)の代用のように
rules句で下界を集約する方法もあります。
-- rules句で下界を集約
select ID,SortKey,Str,ListStr
from EmuListAggT
model
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(SortKey,Str,cast(null as VarChar2(20)) as ListStr)
rules(ListStr[any] = ListAgg(Str,',') WithIn group(order by SortKey)[rn <= cv()])
order by ID,SortKey;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
09 count(distinct Val) over(order by SortKey)の代用のように
rules句で下界を集約する方法もあります。
-- rules句で下界を集約
select ID,SortKey,Str,ListStr
from EmuListAggT
model
partition by(ID)
dimension by(Row_Number() over(partition by ID order by SortKey) as rn)
measures(SortKey,Str,cast(null as VarChar2(20)) as ListStr)
rules(ListStr[any] = ListAgg(Str,',') WithIn group(order by SortKey)[rn <= cv()])
order by ID,SortKey;
14 正規表現関数の繰り返し実行
正規表現の可変長戻り読みの代用
create table SeqRegex(Str) as
select 'ABBBCBA' from dual union all
select 'BABCBA' from dual union all
select 'BCABAC' from dual union all
select 'CBABC' from dual;
各行のStrを1文字目から見て行って、
最初に登場した文字のみを残した文字列を求めます。
-- 正規表現関数の繰り返し実行
select Str,NewStr
from SeqRegex
model
dimension by(RowNum as soeji)
measures(Str,Str as NewStr)
rules iterate (100) (
NewStr[any] = RegExp_Replace(NewStr[cv()],'(.)(.*)\1','\1\2'));
出力結果
Str NewStr
------- ------
ABBBCBA ABC
BABCBA BAC
BCABAC BCA
CBABC CBA
C#の正規表現のように可変長戻り読みが使えれば、
(.)(?<=.*\1.*\1)
を削除すればいいのですが、Oracle18cの正規表現ですら、可変長戻り読みが使えないので、
Model句で、RegExp_Replace関数を繰り返し実行してます。
再帰With句を使った代替方法もあります。
-- 再帰With句を使った代替方法
with rec(Str,NewStr,LV) as(
select Str,Str,1
from SeqRegex
union all
select Str,RegExp_Replace(NewStr,'(.)(.*)\1','\1\2'),LV+1
from rec
where LV+1 <= 100)
select Str,NewStr
from rec
where LV = 100;
15 正規表現関数の繰り返し実行(Work変数有り)
中間変数を更新しつつ繰り返し処理
create table StrReverse(Str) as
select '/123/' from dual union all
select '/123/456/' from dual union all
select '/123/456/789/' from dual union all
select '/123/456/789/abc/' from dual;
/を区切りとして、Strを左右反転させます。
-- 中間変数を更新しつつ繰り返し処理
select Str,NewStr
from StrReverse
model
dimension by(RowNum as soeji)
measures(Str,Str as Work,cast('/' as VarChar2(100)) as NewStr)
rules iterate (100)
(NewStr[any] = NewStr[cv()] || RegExp_SubStr(Work[cv()],'[^/]+/$'),
Work[any] = RegExp_Replace(Work[cv()],'[^/]+/$'));
出力結果
Str NewStr
----------------- -----------------
/123/ /123/
/123/456/ /456/123/
/123/456/789/ /789/456/123/
/123/456/789/abc/ /abc/789/456/123/
rules iterate(3)であれば、
処理1 rules句の上から1番目のrule適用を1回
処理2 rules句の上から2番目のrule適用を1回
として、
処理1,処理2,処理1,処理2,処理1,処理2
の順序で3回繰り返されます。
なので、上記のSQLのように、Workという中間変数を用意し、
中間変数を更新しつつ、rules句の処理を繰り返すことができます。
16 列値を昇順にソート
rules句でバブルソート
create table SortTable(ID,Val1,Val2,Val3,Val4,Val5) as
select 'AA',1,2,3,4,5 from dual union all
select 'BB',5,4,3,2,1 from dual union all
select 'CC',1,1,1,1,5 from dual union all
select 'DD',1,5,5,5,5 from dual union all
select 'EE',1,2,3,2,1 from dual union all
select 'FF',1,2,3,1,5 from dual;
行ごとに、
Val1,Val2,Val3,Val4,Val5
を昇順にソートします。
-- rules句でバブルソート
select ID,Val1,Val2,Val3,Val4,Val5
from SortTable
model
dimension by(ID)
measures(Val1,Val2,Val3,Val4,Val5,0 as GWork,0 as LWork)
rules iterate(4)
(GWork[any] = Least(Val1[cv()],Val2[cv()]),
LWork[any] = Greatest(Val1[cv()],Val2[cv()]),
Val1[any] = GWork[cv()],
Val2[any] = LWork[cv()],
GWork[any] = Least(Val2[cv()],Val3[cv()]),
LWork[any] = Greatest(Val2[cv()],Val3[cv()]),
Val2[any] = GWork[cv()],
Val3[any] = LWork[cv()],
GWork[any] = Least(Val3[cv()],Val4[cv()]),
LWork[any] = Greatest(Val3[cv()],Val4[cv()]),
Val3[any] = GWork[cv()],
Val4[any] = LWork[cv()],
GWork[any] = Least(Val4[cv()],Val5[cv()]),
LWork[any] = Greatest(Val4[cv()],Val5[cv()]),
Val4[any] = GWork[cv()],
Val5[any] = LWork[cv()])
order by ID;
出力結果
ID Val1 Val2 Val3 Val4 Val5
-- ---- ---- ---- ---- ----
AA 1 2 3 4 5
BB 1 2 3 4 5
CC 1 1 1 1 5
DD 1 5 5 5 5
EE 1 1 2 2 3
FF 1 1 2 3 5
LWorkとGWorkというWork変数を用意して、要素の交換を行ってます。
ソートアルゴリズムとしては、バブルソートを使ってます。
17 複雑な計算結果を使った計算
rules句で、計算結果を使った計算
create table ComplexCalc(Val1,Val2,Val3,Val4,Flag) as
select 1,2,3,4,0 from dual union all
select 2,3,4,5,1 from dual union all
select 3,4,5,6,0 from dual union all
select 4,5,6,7,1 from dual;
下記の代入演算を(上から順に)行った結果を求めます。
Val1 := Val1+Val2+Val3+Val4;
Val2 := case when Flag = 0 then Val3+Val4
else Val1+Val2 end;
Val3 := Val3+Val2;
Val4 := Val1+Val2+Val3;
出力結果
Val1 Val2 Val3 Val4 Flag
---- ---- ---- ---- ----
10 7 10 27 0
14 17 21 52 1
18 11 16 45 0
22 27 33 82 1
--Model句を使う方法
select Val1,Val2,Val3,Val4,Flag
from complexCalc
model
dimension by(RowNum as rn)
measures(Val1,Val2,Val3,Val4,Flag)
rules(
Val1[any] = Val1[cv()]+Val2[cv()]+Val3[cv()]+Val4[cv()],
Val2[any] = case when Flag[cv()] = 0 then Val3[cv()]+Val4[cv()]
else Val1[cv()]+Val2[cv()] end,
Val3[any] = Val3[cv()]+Val2[cv()],
Val4[any] = Val1[cv()]+Val2[cv()]+Val3[cv()])
order by Val1;
複雑な計算結果を使った計算を、Model句で行うことができます。
下記の表関数を使った代替方法では、packageとfunctionを定義する必要がありますが、
Model句を使う方法では、必要ありません。
-- 表関数を使った代替方法
create or replace package PackModel17 Is
type PrintType is record(
Val1 ComplexCalc.Val1%type,
Val2 ComplexCalc.Val2%type,
Val3 ComplexCalc.Val3%type,
Val4 ComplexCalc.Val4%type,
Flag ComplexCalc.Flag%type);
type PrintTypeSet is table of PrintType;
end;
/
create or replace function PrintModel17 return PackModel17.PrintTypeSet PipeLined IS
OutR PackModel17.PrintType;
begin
for rec in (select Val1,Val2,Val3,Val4,Flag
from ComplexCalc) Loop
OutR.Val1 := rec.Val1;
OutR.Val2 := rec.Val2;
OutR.Val3 := rec.Val3;
OutR.Val4 := rec.Val4;
OutR.Flag := rec.Flag;
OutR.Val1 := OutR.Val1+OutR.Val2+OutR.Val3+OutR.Val4;
OutR.Val2 := case when OutR.Flag = 0 then OutR.Val3+OutR.Val4
else OutR.Val1+OutR.Val2 end;
OutR.Val3 := OutR.Val3+OutR.Val2;
OutR.Val4 := OutR.Val1+OutR.Val2+OutR.Val3;
pipe row(OutR);
end loop;
end;
/
select Val1,Val2,Val3,Val4,Flag from table(PrintModel17) order by Val1;