OracleSQLパズル
明智重蔵のブログ
明智重蔵のTwitter
記事(OTN)
記事(CodeZine)
Oracleの分析関数のサンプル集
概要
Oracleコミュニティでよく見かける分析関数の使用例を
習うより慣れろ形式で、分析関数のイメージを付けて、まとめて紹介します。
Oracle11gR1で動作確認しましたが、Oracle11gR2で追加された分析関数の機能についても解説します。
目次
1. count(*) over()
使用する状況
・親言語側でselect文の件数を元にプログレスバーを表示したり、件数をログファイルに記録したい時
・データ調査において、select文の件数も一緒に表示したい時
count(*) over()は、select文の結果の行数を列に持たせたい時に使います。サンプルを見てみましょう。
create table sampleT01(Val) as
select 10 from dual union all
select 20 from dual union all
select 30 from dual union all
select 30 from dual union all
select 30 from dual;
select Val,count(*) over() as recordCount
from sampleT01;
Val recordCount
--- -----------
10 5
20 5
30 5
30 5
30 5
select文の結果の行数である5がrecordCountの値になってますね。
SQLのイメージは、こうなります。
 select句でdistinctが指定されている場合は、インラインビューを使うといいでしょう。
(select文の評価順序において、select句の分析関数の評価後に、distinctによる重複排除があるため)
select Val,count(*) over() as recordCount
from (select distinct Val
from sampleT01)
order by Val;
Val recordCount
--- -----------
10 3
20 3
30 3
select句でdistinctが指定されている場合は、インラインビューを使うといいでしょう。
(select文の評価順序において、select句の分析関数の評価後に、distinctによる重複排除があるため)
select Val,count(*) over() as recordCount
from (select distinct Val
from sampleT01)
order by Val;
Val recordCount
--- -----------
10 3
20 3
30 3
2. count(*) over() と minus
使用する状況
・データ移行後やバックアップしたテーブルとのデータ比較
・SQLのチューニング後に、2つのselect文の結果が一致するかの確認
テーブル定義が同じテーブル同士や、select文の結果同士のデータが一致するかの確認に使うSQLとして、
count(*) over() と minusを組み合わせたSQLがあります。
サンプルを見てみましょう。
create table compA(ID number,Val number);
create table compB(ID number,Val number);
-- case1 (compAとcompBが一致)
truncate table compA;
truncate table compB;
insert into compA values(10,111);
insert into compA values(20,222);
insert into compB values(10,111);
insert into compB values(20,222);
-- case2 (compAとcompBが不一致)
truncate table compA;
truncate table compB;
insert into compA values(10,111);
insert into compB values(10,111);
insert into compB values(20,222);
-- compAとcompBのデータが一致するか調べる
select a.*,count(*) over() from compA a
minus
select a.*,count(*) over() from compB a;
上記のselect文の結果が0件になるのは、以下の少なくとも1つが成り立つ場合です。
・compAが空集合(レコードが0件)
・compAとcompBのデータが(重複行があれば重複を排除してから)比較して一致する
実際の業務において、空集合や重複行があるということは、まずないので
上記のselect文の結果が0件なら、compAとcompBのデータが同じと判定できます。
3. max(Val) over(partition by PID)
使用する状況
・履歴テーブルなどで、列の組み合わせごとの最大の行の値を取得したい時
max(Val) over(partition by PID)は、
指定した値で区切った(パーティションを切った)中での最大値を求める時に使います。
サンプルを見てみましょう。
create table sampleT03(ID,Val) as
select 111,10 from dual union all
select 111,20 from dual union all
select 111,30 from dual union all
select 222,50 from dual union all
select 222,60 from dual union all
select 333,10 from dual union all
select 333,40 from dual;
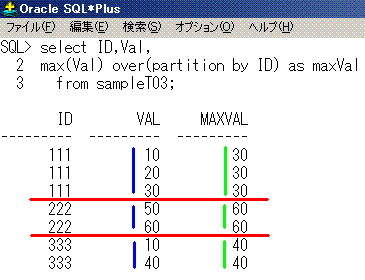
IDごとのValの最大値を求めてみます。
select ID,Val,
max(Val) over(partition by ID) as maxVal
from sampleT03;
ID Val maxVal
--- --- ------
111 10 30
111 20 30
111 30 30
222 50 60
222 60 60
333 10 40
333 40 40
SQLのイメージは、こうなります。partition by IDで赤線をイメージすると分かりやすいでしょう。
 max関数の他に、min関数やsum関数やcount関数やavg関数やmedian関数などでも似たような使い方ができます。
max関数の他に、min関数やsum関数やcount関数やavg関数やmedian関数などでも似たような使い方ができます。
4. count(distinct Val) over(partition by PID)
使用する状況
・列の組み合わせごとに、ある列がユニークかを調査したい時
・列の組み合わせごとに、ある列に重複がないかを調査したい時
distinctオプションを指定した分析関数のcount関数は、列値が何通りあるかを調べる時などに使われます。
サンプルを見てみましょう。
create table sampleT04(ID,Val) as
select 111,1 from dual union all
select 111,1 from dual union all
select 111,2 from dual union all
select 222,4 from dual union all
select 222,5 from dual union all
select 222,6 from dual union all
select 333,7 from dual union all
select 333,7 from dual;
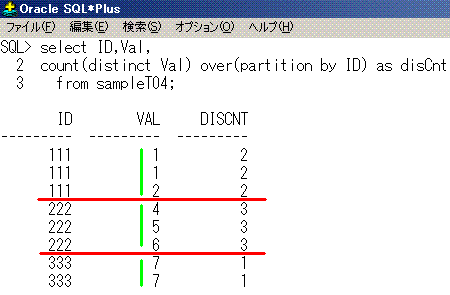
select ID,Val,
count(distinct Val) over(partition by ID) as disCnt
from sampleT04;
ID Val disCnt
--- --- ------
111 1 2
111 1 2
111 2 2
222 4 3
222 5 3
222 6 3
333 7 1
333 7 1
IDごとにValが何通りあるか分かりました。
SQLのイメージは、こうなります。partition by IDで赤線をイメージすると分かりやすいでしょう。
5. Row_Numberとrankとdense_rank
使用する状況
・順位や連番を求めたい時
・順位や連番でupdateしたい時
順位や連番を求めるのに使うのが、Row_Number関数とrank関数とdense_rank関数です。
キーが複数のテーブルへのselect文で、一時的なサロゲートーキーを付与したい時に使うこともあります。
サンプルを見てみましょう。
create table sampleT05(ID,Score) as
select 1,100 from dual union all
select 1, 90 from dual union all
select 1, 90 from dual union all
select 1, 80 from dual union all
select 1, 70 from dual union all
select 2,100 from dual union all
select 2,100 from dual union all
select 2,100 from dual union all
select 2, 90 from dual union all
select 2, 80 from dual;
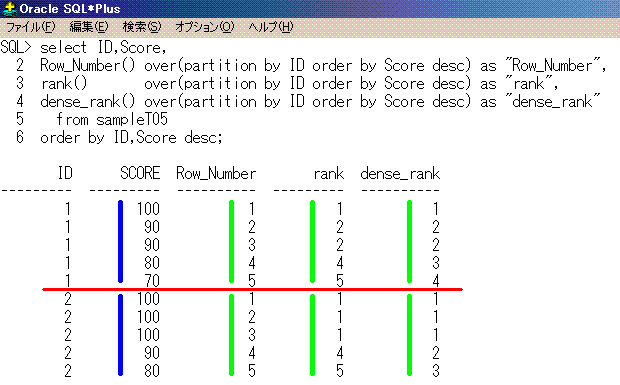
select ID,Score,
Row_Number() over(partition by ID order by Score desc) as "Row_Number",
rank() over(partition by ID order by Score desc) as "rank",
dense_rank() over(partition by ID order by Score desc) as "dense_rank"
from sampleT05
order by ID,Score desc;
ID Score Row_Number rank dense_rank
-- ----- ---------- ---- ----------
1 100 1 1 1
1 90 2 2 2
1 90 3 2 2
1 80 4 4 3
1 70 5 5 4
2 100 1 1 1
2 100 2 1 1
2 100 3 1 1
2 90 4 4 2
2 80 5 5 3
Row_Number関数は、1から始まって、必ず連番になります。
rank関数は、同点があると順位が飛びます。
dense_rank関数は、同点があっても順位が飛びません。denseは、形容詞で、密集したという意味です。
SQLのイメージは、こうなります。partition by IDで赤線をイメージすると分かりやすいでしょう。
6. LagとLead
使用する状況
・帳票などで前の行や後の行との差を計算したい時
・キーブレイクしたかを調べたい時
指定したソートキーでの、
前の行の値が欲しい時に使われるのが、Lag関数で、
後の行の値が欲しい時に使われるのが、Lead関数です。
create table sampleT06(ID,sortKey,Val) as
select 111,1,99 from dual union all
select 111,2,88 from dual union all
select 111,3,77 from dual union all
select 111,5,66 from dual union all
select 222,7,55 from dual union all
select 222,8,44 from dual union all
select 222,9,33 from dual;
IDごとに、sortKeyの昇順での前の行のValを列別名Prevとして求め、
後の行のValを列別名Nextとして求めてみます。
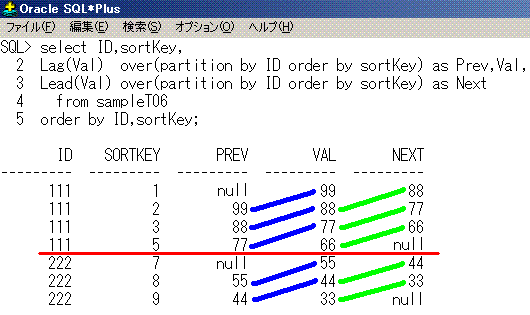
select ID,sortKey,
Lag(Val) over(partition by ID order by sortKey) as Prev,Val,
Lead(Val) over(partition by ID order by sortKey) as Next
from sampleT06
order by ID,sortKey;
ID sortKey Prev Val Next
--- ------- ---- --- ----
111 1 null 99 88
111 2 99 88 77
111 3 88 77 66
111 5 77 66 null
222 7 null 55 44
222 8 55 44 33
222 9 44 33 null
SQLのイメージは、こうなります。
partition by IDが赤線、Lag関数が青線、Lead関数が黄緑線となります。
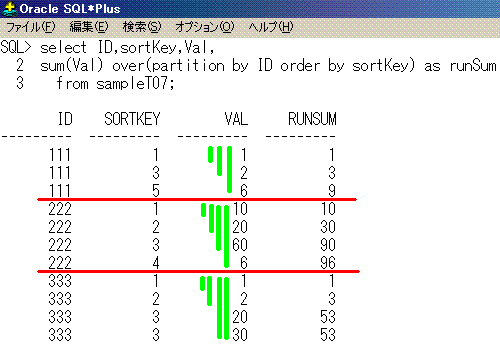
7. sum(Val) over(order by SK)
使用する状況
・帳票などで累計を求めたい時
帳票などで累計を求めたい時に、使われるのがorder byを指定した分析関数のsum関数です。
create table sampleT07(ID,sortKey,Val) as
select 111,1, 1 from dual union all
select 111,3, 2 from dual union all
select 111,5, 6 from dual union all
select 222,1,10 from dual union all
select 222,2,20 from dual union all
select 222,3,60 from dual union all
select 222,4, 6 from dual union all
select 333,1, 1 from dual union all
select 333,2, 2 from dual union all
select 333,3,20 from dual union all
select 333,3,30 from dual;
IDごとに、sortKeyの昇順でValの累計を求めてみます。
select ID,sortKey,Val,
sum(Val) over(partition by ID order by sortKey) as runSum
from sampleT07;
ID sortKey Val runSum
--- ------- --- ------
111 1 1 1
111 3 2 3
111 5 6 9
222 1 10 10
222 2 20 30
222 3 60 90
222 4 6 96
333 1 1 1
333 2 2 3
333 3 20 53
333 3 30 53
SQLのイメージは、こうなります。
partition by IDが赤線、sum(Val) over(partition by ID order by sortKey)が黄緑線となります。
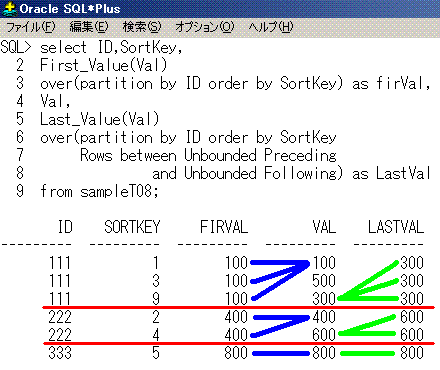
8. First_ValueとLast_Value
使用する状況
・帳票などで最初や最後の値を求めたい時
指定したソートキーでの、最初の行の値を求めるのが、First_Value関数。
指定したソートキーでの、最後の行の値を求めるのが、Last_Value関数。
指定したソートキーでの、(Row_Numberな順位が)n番目の行の値を求めるのが、nth_Value関数となります。
Oracle11gR2でnth_Value関数が追加されました。
サンプルを見てみましょう。
create table sampleT08(ID,SortKey,Val) as
select 111,1,100 from dual union all
select 111,3,500 from dual union all
select 111,9,300 from dual union all
select 222,2,400 from dual union all
select 222,4,600 from dual union all
select 333,5,800 from dual;
IDごとでSortKeyの昇順で、最初の行のValと最後の行のValを求めてみます。
select ID,SortKey,
First_Value(Val)
over(partition by ID order by SortKey) as firVal,
Val,
Last_Value(Val)
over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as LastVal
from sampleT08;
ID SortKey firVal Val LastVal
--- --------- ------ --- -------
111 1 100 100 300
111 3 100 500 300
111 9 100 300 300
222 2 400 400 600
222 4 400 600 600
333 5 800 800 800
SQLのイメージは、こうなります。
partition by IDが赤線、First_Valueが青線、Last_Valueが黄緑線となります。
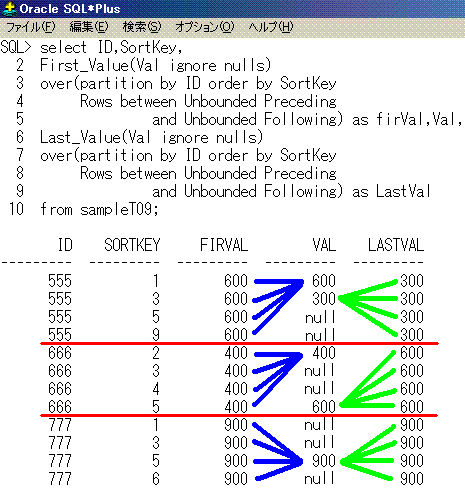
9. First_ValueとLast_Value(ignore nullsオプション付き)
使用する状況
・ある条件を満たす最初や最後の行の値を求めたい時
Oracle10gR1から、First_Value関数とLast_Value関数で、ignore nullsを指定できます。
ちなみに、Oracle11gR2からは、Lag関数とLead関数でもignore nullsを指定できます。
Last_Value(値 ignore nulls) over句 が基本的な使い方ですが、
Last_Value(case when 条件 then 値 end ignore nulls) over句 というふうに、
case式を組み合わせて使うほうが多いです。
サンプルを見てみましょう。
create table sampleT09(ID,SortKey,Val) as
select 555,1, 600 from dual union all
select 555,3, 300 from dual union all
select 555,5,null from dual union all
select 555,9,null from dual union all
select 666,2, 400 from dual union all
select 666,3,null from dual union all
select 666,4,null from dual union all
select 666,5, 600 from dual union all
select 777,1,null from dual union all
select 777,3,null from dual union all
select 777,5, 900 from dual union all
select 777,6,null from dual;
IDごとでSortKeyの昇順で、最初のnullでないValと、最後のnullでないValを求めてみます。
select ID,SortKey,
First_Value(Val ignore nulls)
over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as firVal,Val,
Last_Value(Val ignore nulls)
over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as LastVal
from sampleT09;
ID SortKey firVal Val LastVal
--- ------- ------ ---- -------
555 1 600 600 300
555 3 600 300 300
555 5 600 null 300
555 9 600 null 300
666 2 400 400 600
666 3 400 null 600
666 4 400 null 600
666 5 400 600 600
777 1 900 null 900
777 3 900 null 900
777 5 900 900 900
777 6 900 null 900
SQLのイメージは、こうなります。
partition by IDが赤線、First_Valueが青線、Last_Valueが黄緑線となります。
 ignore nullsの、別の使い方として、
その行以降で最初のnullでないValや、
その行までで最後のnullでないValを求めるといった使い方もあります。
サンプルを見てみましょう。
create table sampleT09_2(SortKey,Val) as
select 1,null from dual union all
select 2, 500 from dual union all
select 3,null from dual union all
select 5,null from dual union all
select 6, 300 from dual union all
select 10,null from dual union all
select 11,null from dual union all
select 12, 700 from dual union all
select 13,null from dual;
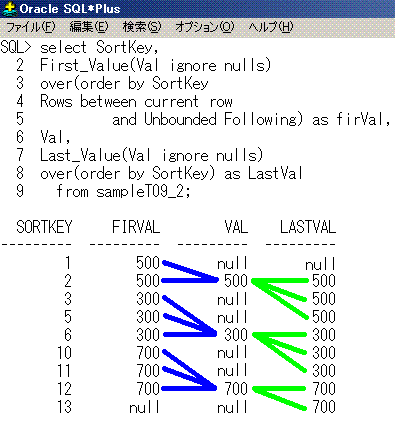
select SortKey,
First_Value(Val ignore nulls)
over(order by SortKey
Rows between current row
and Unbounded Following) as firVal,
Val,
Last_Value(Val ignore nulls)
over(order by SortKey) as LastVal
from sampleT09_2;
SortKey firVal Val LastVal
------- ------ ---- -------
1 500 null null
2 500 500 500
3 300 null 500
5 300 null 500
6 300 300 300
10 700 null 300
11 700 null 300
12 700 700 700
13 null null 700
SQLのイメージは、こうなります。
First_Valueが青線、Last_Valueが黄緑線となります。
ignore nullsの、別の使い方として、
その行以降で最初のnullでないValや、
その行までで最後のnullでないValを求めるといった使い方もあります。
サンプルを見てみましょう。
create table sampleT09_2(SortKey,Val) as
select 1,null from dual union all
select 2, 500 from dual union all
select 3,null from dual union all
select 5,null from dual union all
select 6, 300 from dual union all
select 10,null from dual union all
select 11,null from dual union all
select 12, 700 from dual union all
select 13,null from dual;
select SortKey,
First_Value(Val ignore nulls)
over(order by SortKey
Rows between current row
and Unbounded Following) as firVal,
Val,
Last_Value(Val ignore nulls)
over(order by SortKey) as LastVal
from sampleT09_2;
SortKey firVal Val LastVal
------- ------ ---- -------
1 500 null null
2 500 500 500
3 300 null 500
5 300 null 500
6 300 300 300
10 700 null 300
11 700 null 300
12 700 700 700
13 null null 700
SQLのイメージは、こうなります。
First_Valueが青線、Last_Valueが黄緑線となります。
10. Rows 2 preceding
使用する状況
・帳票などで移動平均や移動累計を求めたい時
Rows 2 precedingといった指定は、移動平均や移動累計を求める時などに使われます。
サンプルを見てみましょう。
create table idotT(sortKey,Val) as
select 1, 10 from dual union all
select 2, 20 from dual union all
select 5, 60 from dual union all
select 7,100 from dual union all
select 8,200 from dual union all
select 9,600 from dual;
sortKeyの昇順での、前の2行と自分の行を加算対象とした移動累計を求めてみます。
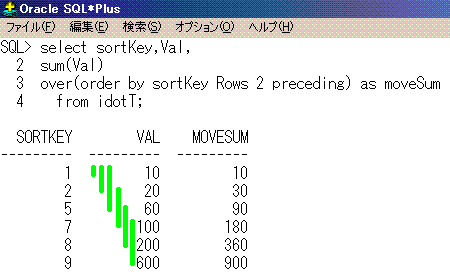
select sortKey,Val,
sum(Val)
over(order by sortKey Rows 2 preceding) as moveSum
from idotT;
sortKey Val moveSum
------- --- -------
1 10 10
2 20 30
5 60 90
7 100 180
8 200 360
9 600 900
SQLのイメージは、こうなります。
sum(Val) over(order by sortKey Rows 2 preceding)が黄緑線となります。
11. Range 2 preceding
使用する状況
・データ分析などで移動平均や移動累計を求めたい時
Range 2 precedingといった指定は、移動平均や移動累計を求めたい時などに、使われます。
Rows 2 precedingとの違いは、Rowsが行数の指定なのに対して、Rangeはソートキーの範囲の指定という点です。
サンプルを見てみましょう。
sortKeyが自分の行より2小さい行から、自分の行までを加算対象とした移動累計を求めてみます。
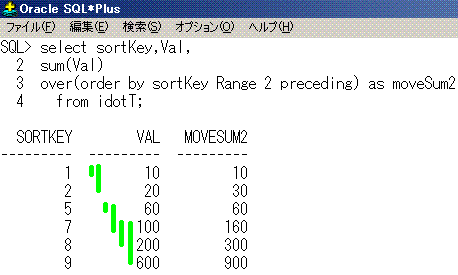
select sortKey,Val,
sum(Val)
over(order by sortKey Range 2 preceding) as moveSum2
from idotT;
sortKey Val moveSum2
------- --- --------
1 10 10
2 20 30
5 60 60
7 100 160
8 200 300
9 600 900
SQLのイメージは、こうなります。
sum(Val) over(order by sortKey Range 2 preceding)が黄緑線となります。
12. 全称肯定,全称否定,存在肯定,存在否定
使用する状況
・全ての行が条件を満たすかを調べる
・全ての行が条件を満たさないかを調べる
・少なくとも1行が条件を満たすかを調べる
・少なくとも1行が条件を満たさないかを調べる
複数行にまたがったチェックをしたい時に使います。サンプルを見てみましょう。
create table boolT(ID,Val) as
select 111,3 from dual union all
select 111,3 from dual union all
select 111,3 from dual union all
select 222,3 from dual union all
select 222,1 from dual union all
select 333,0 from dual union all
select 333,4 from dual;
・check1 IDごとで、全ての行が Val=3 を満たすか?
・check2 IDごとで、全ての行が Val=3 を満たさないか?
・check3 IDごとで、少なくとも1つの行が Val=3 を満たすか?
・check4 IDごとで、少なくとも1つの行が Val=3 を満たさないか?
をチェックしてみましょう。
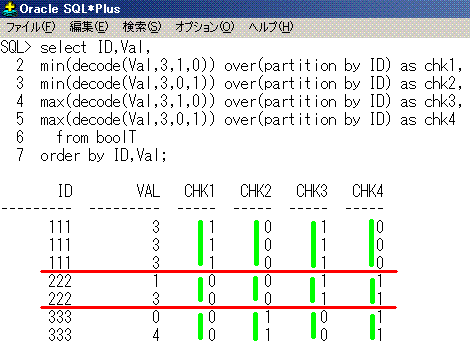
select ID,Val,
min(decode(Val,3,1,0)) over(partition by ID) as chk1,
min(decode(Val,3,0,1)) over(partition by ID) as chk2,
max(decode(Val,3,1,0)) over(partition by ID) as chk3,
max(decode(Val,3,0,1)) over(partition by ID) as chk4
from boolT
order by ID,Val;
ID Val chk1 chk2 chk3 chk4
--- --- ---- ---- ---- ----
111 3 1 0 1 0
111 3 1 0 1 0
111 3 1 0 1 0
222 1 0 0 1 1
222 3 0 0 1 1
333 0 0 1 0 1
333 4 0 1 0 1
SQLのイメージは、こうなります。
partition by IDが赤線で、min関数とmax関数が黄緑線となります。
 ちなみに、
IDごとで、少なくとも1つの行が Val=0を満たし、
かつ、少なくとも1つの行が Val=4を満たすかをチェックするSQLは、下記となります。
掛け算で論理積を代用しています。
select ID,Val,
max(decode(Val,0,1,0)) over(partition by ID)
*max(decode(Val,4,1,0)) over(partition by ID) as chk
from boolT
order by ID,Val;
ID Val chk
--- --- ---
111 3 0
111 3 0
111 3 0
222 1 0
222 3 0
333 0 1
333 4 1
ちなみに、
IDごとで、少なくとも1つの行が Val=0を満たし、
かつ、少なくとも1つの行が Val=4を満たすかをチェックするSQLは、下記となります。
掛け算で論理積を代用しています。
select ID,Val,
max(decode(Val,0,1,0)) over(partition by ID)
*max(decode(Val,4,1,0)) over(partition by ID) as chk
from boolT
order by ID,Val;
ID Val chk
--- --- ---
111 3 0
111 3 0
111 3 0
222 1 0
222 3 0
333 0 1
333 4 1
13. wmsys.wm_concatとListAgg
使用する状況
・sum関数やcount関数などの集約の内訳を表示したい時
・文字列を連結してまとめて表示したい時
MySQLのGroup_Concat関数のような機能として、wmsys.wm_concat関数という関数があります。
サンプルを見てみましょう。
create table strAggT(ID,Val) as
select 111,'a' from dual union all
select 111,'b' from dual union all
select 111,'c' from dual union all
select 222,'d' from dual union all
select 222,'e' from dual union all
select 222,'f' from dual;
select ID,Val,
wmsys.wm_concat(Val) over(partition by ID) as strAgg1,
wmsys.wm_concat(Val) over(order by Val) as strAgg2
from strAggT;
ID Val strAgg1 strAgg2
--- --- ------- -----------
111 a a,b,c a
111 b a,b,c a,b
111 c a,b,c a,b,c
222 d d,e,f a,b,c,d
222 e d,e,f a,b,c,d,e
222 f d,e,f a,b,c,d,e,f
wmsys.wm_concat関数は、Oracle11gR2の段階でマニュアルに記載されていないので、注意して使用する必要があります。
wmsys.wm_concat関数と似たような機能を持つListAgg関数は、Oracle11gR2で追加された関数です。
14. range between interVal '5' minute following and unBounded following
使用する状況
・ソートキーが日付型での最小上界を求めたい時
日付型をソートキーに指定してのrange指定です。サンプルを見てみましょう。
create table dateRange(dayCol) as
select to_date('2009-11-01 10:10','YYYY-MM-DD HH24:MI') from dual union
select to_date('2009-11-01 10:14','YYYY-MM-DD HH24:MI') from dual union
select to_date('2009-11-01 10:17','YYYY-MM-DD HH24:MI') from dual union
select to_date('2009-11-01 10:19','YYYY-MM-DD HH24:MI') from dual union
select to_date('2009-11-01 10:20','YYYY-MM-DD HH24:MI') from dual union
select to_date('2009-11-01 10:26','YYYY-MM-DD HH24:MI') from dual union
select to_date('2009-11-01 10:30','YYYY-MM-DD HH24:MI') from dual;
行ごとに、5分後以降で最小のdayColを求めます。
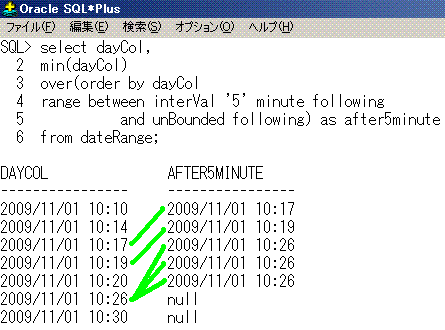
select dayCol,
min(dayCol)
over(order by dayCol
range between interVal '5' minute following
and unBounded following) as after5minute
from dateRange;
dayCol after5minute
---------------- ----------------
2009-11-01 10:10 2009-11-01 10:17
2009-11-01 10:14 2009-11-01 10:19
2009-11-01 10:17 2009-11-01 10:26
2009-11-01 10:19 2009-11-01 10:26
2009-11-01 10:20 2009-11-01 10:26
2009-11-01 10:26 null
2009-11-01 10:30 null
SQLのイメージは、こうなります。min関数で黄緑線を引いてます。
15. 分析関数の参考サイト