SQLServerのSQLのサンプル集
明智重蔵のブログ
明智重蔵のTwitter
SQLServer2012 ホーム
SQLServerフォーラム
SQLServerの分析関数の使用例
概要
SQLServerの分析関数の使用例について、まとめたページです。
SQLServer2008 R1 Express Editionを対象としてます。
SQLServer2012で追加された機能は、第3部を参照して下さい。
目次
1. 分析関数とは
select句とorder by句で使うことができる。order by句で使うことは、ほとんどない。
SQLServer2005以降から使用可能
Oracle9i以降
DB2
PostgreSQL8.4
などでも使用可能
分析関数は標準SQLなので、いずれは、他のDBでも使えるようになるはずです。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
分析関数のメリット
自己結合や相関サブクエリを使ったり、親言語(C#やVB6など)やストアドプロシージャで、
求めていた結果を、SQLで容易に求めることができるようになります。
帳票作成やデータ分析で特に使います。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
SQLServer2008の分析関数の使用頻度
最頻出 count max min Row_Number
頻出 Rank dense_rank sum
たまに avg NTile
2. select文の件数取得
select文の結果の件数が欲しいといったことは、結構あります。そんな時に使うのが、分析関数のcount関数です。
create table TestTable(ID int,Val int);
insert into TestTable values(1,10),
(1,20),
(2,10),
(2,30),
(2,50);
-- OLAPSample1
select ID,Val,
count(*) over() as recordCount
from TestTable;
-- OLAPSample1のサブクエリを使った代替方法
select ID,Val,
(select count(*) from TestTable b) as recordCount
from TestTable a;
ID Val recordCount
-- --- -----------
1 10 5
1 20 5
2 10 5
2 30 5
2 50 5
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。
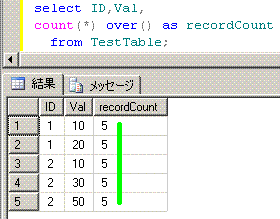 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
where句や、group by句や、having句があっても、select文の結果の件数が求まります。
-- OLAPSample2
select ID,Val,
count(*) over() as recordCount
from TestTable
where Val in(10,20);
ID Val recordCount
-- --- -----------
1 10 3
1 20 3
2 10 3
-- OLAPSample3
select ID,max(Val) as maxVal,
count(*) over() as recordCount
from TestTable
group by ID
having max(Val) = 20;
ID maxVal recordCount
-- ------ -----------
1 20 1
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
Top句があるselect文の結果の件数を求めるには、
インラインビューを使うか、case式を使う必要があります。
distinct指定があるselect文の結果の件数を求めるには、
インラインビューを使うか、count(*) over()の代わりにdense_rank関数と逆ソートを使う必要があります。
SELECT (Transact-SQL)に書いてあるように、SQLServerのselect文は、
1 from句
2 where句
3 group by句
4 having句
5 select句
6 distinct
7 order by句
8 Top句
の順に動作するからです。
-- OLAPSample4
select Top (2) ID,count(*) over() as recordCount
from TestTable
order by ID;
ID recordCount
-- -----------
1 5
1 5
-- OLAPSample5
select Top (2) ID,
case when 2 < count(*) over()
then 2 else count(*) over() end as recordCount
from TestTable
order by ID;
ID recordCount
-- -----------
1 2
1 2
create table disT(ColA int,ColB int);
insert into disT values(1,null),
(1, 3),
(1, 3),
(2,null),
(2,null);
-- OLAPSample6
select distinct ColA,ColB,
-1+dense_rank() over(order by ColA asc ,ColB asc)
+dense_rank() over(order by ColA desc,ColB desc) as recordCount
from disT
order by ColA,ColB;
ColA ColB recordCount
---- ---- -----------
1 NULL 3
1 3 3
2 NULL 3
-- OLAPSample7
select distinct Top (2) ColA,ColB,
case when 2 < -1+dense_rank() over(order by ColA asc ,ColB asc)
+dense_rank() over(order by ColA desc,ColB desc)
then 2 else -1+dense_rank() over(order by ColA asc ,ColB asc)
+dense_rank() over(order by ColA desc,ColB desc) end as recordCount
from disT
order by ColA,ColB;
ColA ColB recordCount
---- ---- -----------
1 NULL 2
1 3 2
下記のように、インラインビューを使うのがシンプルでおすすめですね。
-- OLAPSample8
select ColA,ColB,count(*) over() as recordCount
from (select distinct Top (2) ColA,ColB
from disT
order by ColA,ColB) a
order by ColA,ColB;
ColA ColB recordCount
---- ---- -----------
1 NULL 2
1 3 2
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
where句や、group by句や、having句があっても、select文の結果の件数が求まります。
-- OLAPSample2
select ID,Val,
count(*) over() as recordCount
from TestTable
where Val in(10,20);
ID Val recordCount
-- --- -----------
1 10 3
1 20 3
2 10 3
-- OLAPSample3
select ID,max(Val) as maxVal,
count(*) over() as recordCount
from TestTable
group by ID
having max(Val) = 20;
ID maxVal recordCount
-- ------ -----------
1 20 1
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
Top句があるselect文の結果の件数を求めるには、
インラインビューを使うか、case式を使う必要があります。
distinct指定があるselect文の結果の件数を求めるには、
インラインビューを使うか、count(*) over()の代わりにdense_rank関数と逆ソートを使う必要があります。
SELECT (Transact-SQL)に書いてあるように、SQLServerのselect文は、
1 from句
2 where句
3 group by句
4 having句
5 select句
6 distinct
7 order by句
8 Top句
の順に動作するからです。
-- OLAPSample4
select Top (2) ID,count(*) over() as recordCount
from TestTable
order by ID;
ID recordCount
-- -----------
1 5
1 5
-- OLAPSample5
select Top (2) ID,
case when 2 < count(*) over()
then 2 else count(*) over() end as recordCount
from TestTable
order by ID;
ID recordCount
-- -----------
1 2
1 2
create table disT(ColA int,ColB int);
insert into disT values(1,null),
(1, 3),
(1, 3),
(2,null),
(2,null);
-- OLAPSample6
select distinct ColA,ColB,
-1+dense_rank() over(order by ColA asc ,ColB asc)
+dense_rank() over(order by ColA desc,ColB desc) as recordCount
from disT
order by ColA,ColB;
ColA ColB recordCount
---- ---- -----------
1 NULL 3
1 3 3
2 NULL 3
-- OLAPSample7
select distinct Top (2) ColA,ColB,
case when 2 < -1+dense_rank() over(order by ColA asc ,ColB asc)
+dense_rank() over(order by ColA desc,ColB desc)
then 2 else -1+dense_rank() over(order by ColA asc ,ColB asc)
+dense_rank() over(order by ColA desc,ColB desc) end as recordCount
from disT
order by ColA,ColB;
ColA ColB recordCount
---- ---- -----------
1 NULL 2
1 3 2
下記のように、インラインビューを使うのがシンプルでおすすめですね。
-- OLAPSample8
select ColA,ColB,count(*) over() as recordCount
from (select distinct Top (2) ColA,ColB
from disT
order by ColA,ColB) a
order by ColA,ColB;
ColA ColB recordCount
---- ---- -----------
1 NULL 2
1 3 2
3. exceptとcount(*) over()
2つのselect文の結果が同じか確認するときや、同じ定義の2テーブルのデータが同じか確認する時に使えるのが、
exceptとcount(*) over() の組み合わせです。
create table tableA(ColA int,ColB int);
create table tableB(ColA int,ColB int);
insert into tableA values(1,2),
(3,4);
-- case1
truncate table tableB;
insert into tableB values(1,2);
-- case2
truncate table tableB;
insert into tableB values(1,2),
(3,4),
(5,6);
-- case3
truncate table tableB;
-- case4
truncate table tableB;
insert into tableB values(2,2),
(3,3);
-- case5
truncate table tableB;
insert into tableB values(1,2),
(3,4);
-- tableAとtableBのデータが同じか確認するselect文
select *,count(*) over() from tableA
except
select *,count(*) over() from tableB;
上記のselect文の結果が0件になるのは、以下の少なくとも1つが成り立つ場合です。
・tableAが空集合(レコードが0件)
・tableAとtableBのデータが(重複行があれば重複を排除してから)比較して一致する
実際の業務において、空集合ということは、まずないので
上記のselect文の結果が0件なら、tableAとtableBのデータが同じと判定できます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
数学の集合では、集合の相等性を調べる公式として、以下が有名ですが、
(A ⊆ B ) かつ (A ⊇ B) ⇔ (A = B)
(集合Aと集合Bの要素数が等しい) かつ (A ⊆ B) ⇔ (A = B)
も成立します。
集合Aと集合Bが両方とも空集合の場合は、自明ですし、
集合Aと集合Bが両方とも空集合でない場合は、要素数が等しくて包含関係が成立するのは、A=Bの場合しかないからです。
要素数は、分析関数のcount関数を使えば求まりますし、
包含関係は、差集合が空集合かどうかを調べれば分かります。
4. 最大値の行の取得
実によく見かける、定番問題です。IDごとに、Valが最大値の行を取得します。
create table TestTable2(ID int,Val int,extraCol char(1));
insert into TestTable2 values(1,10,'A'),
(1,20,'B'),
(2,10,'C'),
(2,30,'D'),
(2,50,'E'),
(3,70,'F'),
(3,70,'G');
-- 単純に、IDごとのValの最大値が欲しいなら、これで可
select ID,max(Val)
from TestTable2
group by ID;
-- OLAPSample9
select ID,Val,extraCol
from (select ID,Val,extraCol,
max(Val) over(partition by ID) as maxVal
from TestTable2) a
where Val = maxVal;
-- OLAPSample9の相関サブクエリを使った代替方法
select ID,Val,extraCol
from TestTable2 a
where Val = (select max(b.Val)
from TestTable2 b
where b.ID = a.ID);
ID Val extraCol
-- --- --------
1 20 B
2 50 E
3 70 F
3 70 G
分析関数が使えるのは、select句かorder by句です。
なので、分析関数の結果をwhere句で使うには、インラインビューを使う必要があります。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。
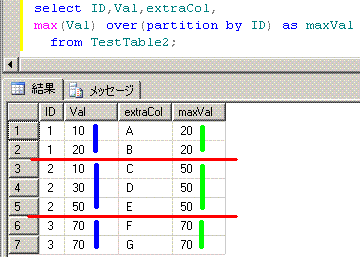
5. 順位を付ける
順位や連番を付けたい時に使うのが、分析関数のRow_Number関数,rank関数,dense_rank関数です。
create table TestTable3(ID int,score int);
insert into TestTable3 values(1,100),
(1,100),
(1, 90),
(1, 80),
(2,100),
(2, 70),
(2, 70);
-- OLAPSample10
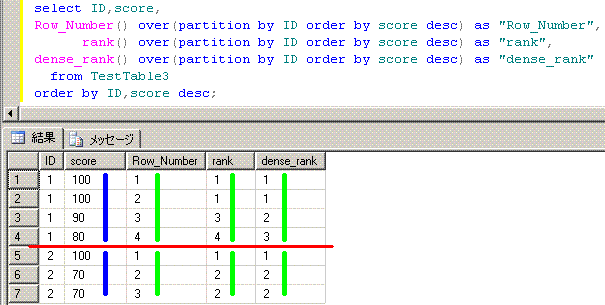
select ID,score,
Row_Number() over(partition by ID order by score desc) as "Row_Number",
rank() over(partition by ID order by score desc) as "rank",
dense_rank() over(partition by ID order by score desc) as "dense_rank"
from TestTable3
order by ID,score desc;
ID score Row_Number rank dense_rank
-- ----- ---------- ---- ----------
1 100 1 1 1
1 100 2 1 1
1 90 3 3 2
1 80 4 4 3
2 100 1 1 1
2 70 2 2 2
2 70 3 2 2
Row_Number関数は、1から始まって、必ず連番になります。
rank関数は、同点があると順位が飛びます。
dense_rank関数は、同点があっても順位が飛びません。denseは、形容詞で、密集したという意味です。
-- OLAPSample10の相関サブクエリを使った代替方法 (Row_Number関数以外)
select ID,score,
(select count(*)+1 from TestTable3 b
where b.ID = a.ID and b.score > a.score) as "rank",
(select count(distinct b.score)+1 from TestTable3 b
where b.ID = a.ID and b.score > a.score) as "dense_rank"
from TestTable3 a
order by ID,"rank";
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。
6. 最大値の行の取得(ソートキーが複数)
4. 最大値の行の取得では、
ソートキーが1つだったので、分析関数のmax関数を使いましたが、
ソートキーが複数だと、順位を付ける関数を使う必要があります。
IDごとで、sortKey1が最大の行の中でsortKey2が最大の行を取得します。
create table multiSortKey(ID int,sortKey1 int,sortKey2 int,extraCol char(3));
insert into multiSortKey values(1,10, 2,'AAA'),
(1,10, 3,'BBB'),
(1,30, 1,'CCC'),
(2,20, 1,'DDD'),
(2,50, 2,'EEE'),
(2,50, 2,'FFF'),
(3,60, 1,'GGG'),
(3,60, 2,'HHH'),
(3,60, 3,'III'),
(4,10,20,'JJJ');
-- OLAPSample11
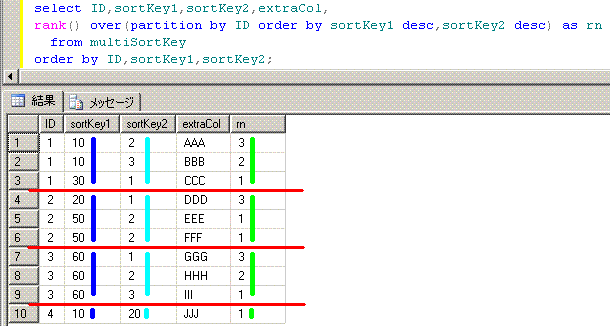
select ID,sortKey1,sortKey2,extraCol
from (select ID,sortKey1,sortKey2,extraCol,
rank() over(partition by ID order by sortKey1 desc,sortKey2 desc) as rn
from multiSortKey) a
where rn = 1
order by ID,extraCol;
ID sortKey1 sortKey2 extraCol
-- -------- -------- --------
1 30 1 CCC
2 50 2 EEE
2 50 2 FFF
3 60 3 III
4 10 20 JJJ
-- OLAPSample11の相関サブクエリを使った代替方法1
select ID,sortKey1,sortKey2,extraCol
from multiSortKey a
where not exists(select 1 from multiSortKey b
where b.ID = a.ID
and (b.sortKey1 > a.sortKey1
or b.sortKey1 = a.sortKey1 and b.sortKey2 > a.sortKey2))
order by ID,extraCol;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。
7. 全称肯定,全称否定,存在肯定,存在否定
これは、US-OTNでよく見かける問題です。
・全ての行が条件を満たすか?
・全ての行が条件を満たさないか?
・少なくとも1行が条件を満たすか?
・少なくとも1行が条件を満たさないか?
といった複数行にまたがったチェックをしたい時に使います。
create table boolCheckT(ID char(2),Val int);
insert into boolCheckT values('AA',10),
('AA',20),
('BB',10),
('BB',30),
('BB',50),
('CC',80),
('CC',90),
('DD',20),
('DD',70);
・check1 IDごとで、全ての行が Val<40 を満たすか?
・check2 IDごとで、全ての行が Val<40 を満たさないか?
・check3 IDごとで、少なくとも1つの行が Val<40 を満たすか?
・check4 IDごとで、少なくとも1つの行が Val<40 を満たさないか?
・check5 IDごとで、少なくとも1つの行が Val=10 を満たし、
かつ、少なくとも1つの行が Val=50 を満たすか?
をチェックしてみましょう。
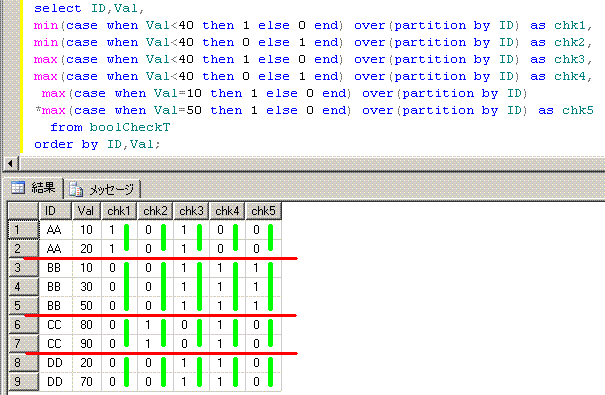
-- OLAPSample12
select ID,Val,
min(case when Val<40 then 1 else 0 end) over(partition by ID) as chk1,
min(case when Val<40 then 0 else 1 end) over(partition by ID) as chk2,
max(case when Val<40 then 1 else 0 end) over(partition by ID) as chk3,
max(case when Val<40 then 0 else 1 end) over(partition by ID) as chk4,
max(case when Val=10 then 1 else 0 end) over(partition by ID)
*max(case when Val=50 then 1 else 0 end) over(partition by ID) as chk5
from boolCheckT
order by ID,Val;
ID Val chk1 chk2 chk3 chk4 chk5
-- --- ---- ---- ---- ---- ----
AA 10 1 0 1 0 0
AA 20 1 0 1 0 0
BB 10 0 0 1 1 1
BB 30 0 0 1 1 1
BB 50 0 0 1 1 1
CC 80 0 1 0 1 0
CC 90 0 1 0 1 0
DD 20 0 0 1 1 0
DD 70 0 0 1 1 0
分析関数のmax関数やmin関数で、
条件を満たせば1、満たさなければ0を値とするcase式や、
条件を満たせば0、満たさなければ1を値とするcase式を使用してます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。partition byで、脳内で赤線を引くと分かりやすいです。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
全称肯定,全称否定,存在肯定,存在否定の、SQLへの変換公式は下記となります。
全称 → min
存在 → max
肯定 → (case when 条件 then 1 else 0 end)
否定 → (case when 条件 then 0 else 1 end)
まとめると
全称肯定命題なら min(case when 条件 then 1 else 0 end) = 1
全称否定命題なら min(case when 条件 then 0 else 1 end) = 1
存在肯定命題なら max(case when 条件 then 1 else 0 end) = 1
存在否定命題なら max(case when 条件 then 0 else 1 end) = 1
存在肯定命題の論理積なら max(case when 条件A then 1 else 0 end)
*max(case when 条件B then 1 else 0 end) = 1
真なら1、偽なら0にしておくことにより、ブール値としても使えます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
集約関数のmin関数やmax関数でも似たようなことを行うことができます。
-- 集約関数での全称肯定命題など
select ID,
(select cast(b.Val as char(2)) + ','
from boolCheckT b
where b.ID=a.ID
for xml path('')) as ListVal,
min(case when Val<40 then 1 else 0 end) as chk1,
min(case when Val<40 then 0 else 1 end) as chk2,
max(case when Val<40 then 1 else 0 end) as chk3,
max(case when Val<40 then 0 else 1 end) as chk4,
max(case when Val=10 then 1 else 0 end)
*max(case when Val=50 then 1 else 0 end) as chk5
from boolCheckT a
group by ID
order by ID;
ID ListVal chk1 chk2 chk3 chk4 chk5
-- --------- ---- ---- ---- ---- ----
AA 10,20, 1 0 1 0 0
BB 10,30,50, 0 0 1 1 1
CC 80,90, 0 1 0 1 0
DD 20,70, 0 0 1 1 0
select句よりも、下記のようにhaving句で使われることが多いです。
-- having句での存在肯定命題
select ID,
(select cast(b.Val as char(2)) + ','
from boolCheckT b
where b.ID=a.ID
for xml path('')) as ListVal
from boolCheckT a
group by ID
having max(case when Val<40 then 1 else 0 end) = 1
order by ID;
ID ListVal
-- ---------
AA 10,20,
BB 10,30,50,
DD 20,70,
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
全称肯定,全称否定,存在肯定,存在否定の、SQLへの変換公式は下記となります。
全称 → min
存在 → max
肯定 → (case when 条件 then 1 else 0 end)
否定 → (case when 条件 then 0 else 1 end)
まとめると
全称肯定命題なら min(case when 条件 then 1 else 0 end) = 1
全称否定命題なら min(case when 条件 then 0 else 1 end) = 1
存在肯定命題なら max(case when 条件 then 1 else 0 end) = 1
存在否定命題なら max(case when 条件 then 0 else 1 end) = 1
存在肯定命題の論理積なら max(case when 条件A then 1 else 0 end)
*max(case when 条件B then 1 else 0 end) = 1
真なら1、偽なら0にしておくことにより、ブール値としても使えます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
集約関数のmin関数やmax関数でも似たようなことを行うことができます。
-- 集約関数での全称肯定命題など
select ID,
(select cast(b.Val as char(2)) + ','
from boolCheckT b
where b.ID=a.ID
for xml path('')) as ListVal,
min(case when Val<40 then 1 else 0 end) as chk1,
min(case when Val<40 then 0 else 1 end) as chk2,
max(case when Val<40 then 1 else 0 end) as chk3,
max(case when Val<40 then 0 else 1 end) as chk4,
max(case when Val=10 then 1 else 0 end)
*max(case when Val=50 then 1 else 0 end) as chk5
from boolCheckT a
group by ID
order by ID;
ID ListVal chk1 chk2 chk3 chk4 chk5
-- --------- ---- ---- ---- ---- ----
AA 10,20, 1 0 1 0 0
BB 10,30,50, 0 0 1 1 1
CC 80,90, 0 1 0 1 0
DD 20,70, 0 0 1 1 0
select句よりも、下記のようにhaving句で使われることが多いです。
-- having句での存在肯定命題
select ID,
(select cast(b.Val as char(2)) + ','
from boolCheckT b
where b.ID=a.ID
for xml path('')) as ListVal
from boolCheckT a
group by ID
having max(case when Val<40 then 1 else 0 end) = 1
order by ID;
ID ListVal
-- ---------
AA 10,20,
BB 10,30,50,
DD 20,70,
8. 最頻値(モード)
create table DayWeather(day1 date,weather char(6));
insert into DayWeather values(convert(date,'2008-01-02'),'sunny' ),
(convert(date,'2008-01-15'),'snowy' ),
(convert(date,'2008-01-30'),'snowy' ),
(convert(date,'2008-06-01'),'cloudy'),
(convert(date,'2008-06-13'),'cloudy'),
(convert(date,'2008-06-24'),'rainy' ),
(convert(date,'2008-06-30'),'rainy' ),
(convert(date,'2008-07-02'),'sunny' ),
(convert(date,'2008-07-14'),'sunny' ),
(convert(date,'2008-07-23'),'sunny' ),
(convert(date,'2008-07-31'),'sunny' ),
(convert(date,'2008-11-10'),'cloudy');
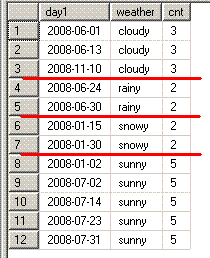
最頻値(モード)を求める問題は、結構見かけます。
weatherの最頻値を求めてみます。(最頻値が複数ある場合は、複数行返すようにします)
-- 最頻値が必ず1つだけなら、これでも可
select Top (1) weather,count(*) as cnt
from DayWeather
group by weather
order by count(*) desc;
-- OLAPSample13
select weather,cnt
from (select weather,count(*) as cnt,
max(count(*)) over() as maxCnt
from DayWeather
group by weather) a
where cnt = maxCnt;
weather cnt
------- ---
sunny 5
-- OLAPSample13のサブクエリを使った代替方法(all述語を使用)
select weather,count(*) as cnt
from DayWeather
group by weather
having count(*) >= all(select count(*)
from DayWeather
group by weather);
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。group by weatherに対応する赤線を引いてます。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
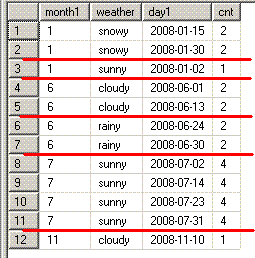
monthごとの最頻値(モード)を求めるような問題も結構見かけます。
-- OLAPSample14
select month1,weather,cnt
from (select month(day1) as month1,weather,
count(*) as cnt,
max(count(*)) over(partition by month(day1)) as maxCnt
from DayWeather
group by month(day1),weather) a
where cnt = maxCnt
order by month1,weather;
month1 weather cnt
------ ------- ---
1 snowy 2
6 cloudy 2
6 rainy 2
7 sunny 4
11 cloudy 1
-- OLAPSample14の相関サブクエリを使った代替方法(Top句を使用)
select month(day1) as month1,weather,count(*) as cnt
from DayWeather a
group by month(day1),weather
having count(*) = (select Top (1) count(*)
from DayWeather b
where month(b.day1) = month(a.day1)
group by weather
order by count(*) desc)
order by month1,weather;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
OLAPSample14の脳内のイメージ(第1段階)は、下のようになります。
group by month(day1),weatherに対応する赤線を引いてます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
monthごとの最頻値(モード)を求めるような問題も結構見かけます。
-- OLAPSample14
select month1,weather,cnt
from (select month(day1) as month1,weather,
count(*) as cnt,
max(count(*)) over(partition by month(day1)) as maxCnt
from DayWeather
group by month(day1),weather) a
where cnt = maxCnt
order by month1,weather;
month1 weather cnt
------ ------- ---
1 snowy 2
6 cloudy 2
6 rainy 2
7 sunny 4
11 cloudy 1
-- OLAPSample14の相関サブクエリを使った代替方法(Top句を使用)
select month(day1) as month1,weather,count(*) as cnt
from DayWeather a
group by month(day1),weather
having count(*) = (select Top (1) count(*)
from DayWeather b
where month(b.day1) = month(a.day1)
group by weather
order by count(*) desc)
order by month1,weather;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
OLAPSample14の脳内のイメージ(第1段階)は、下のようになります。
group by month(day1),weatherに対応する赤線を引いてます。
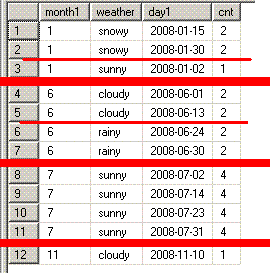
 脳内のイメージ(最終段階)は、下のようになります。
partition by month(day1)に対応する超極太赤線を引いてます。
脳内のイメージ(最終段階)は、下のようになります。
partition by month(day1)に対応する超極太赤線を引いてます。
9. 連続範囲の最小値と最大値 (2人旅人算)
US-OTNでよく見かける問題である、連続範囲の最小値と最大値を求めるSQLです。
分析関数の応用例として有名なものだと思います。
create table NumTable(NumVal integer not null primary key);
insert into NumTable values( 1),
( 2),
( 3),
( 5),
( 6),
( 7),
(10),
(11),
(12),
(20),
(21);
-- OLAPSample15 旅人算の感覚を使う
select min(NumVal) as StaVal,
max(NumVal) as EndVal,count(*) as cnt
from (select NumVal,
NumVal-Row_Number() over(order by NumVal) as distance
from NumTable) a
group by distance
order by StaVal;
StaVal EndVal cnt
------ ------ ---
1 3 3
5 7 3
10 12 3
20 21 2
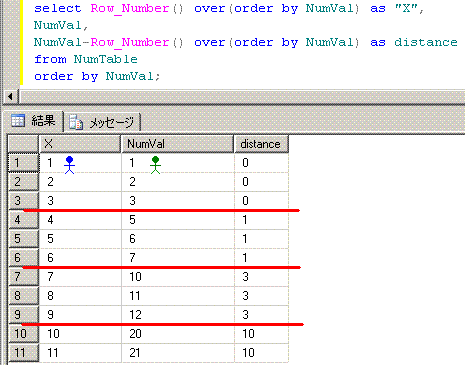
上記のSQLでは、2人の旅人(旅人Xと旅人A)を脳内でイメージしてます。
旅人Xは、速度が1です。(Row_Number() over(order by NumVal))
旅人Aは、速度が1以上の自然数です。(NumVal)
そして、旅人Xと旅人Aの距離でグループ化してます。 (group by distance)
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
旅人算の感覚を使う脳内のイメージは、下のようになります。
 中学受験の算数の旅人算の感覚を取得するには、
図表付きで解説している、これらのサイトの問題を解くのがオススメです。
(方程式や連立方程式を使って解いてもいいです)
今月は旅人算 - 学びの場.com
中学受験の算数の旅人算の感覚を取得するには、
図表付きで解説している、これらのサイトの問題を解くのがオススメです。
(方程式や連立方程式を使って解いてもいいです)
今月は旅人算 - 学びの場.com
10. 連続範囲の最小値と最大値 (3人旅人算)
前問の応用であり、US-OTNでよく見かけて、SQLパズル 第2版にも掲載されている問題。
第63問 連続的なグルーピングを旅人算の感覚を使って解いてみましょう。
create table Tabibito(
sortKey integer not null,
Val char(3),
primary key(sortKey));
insert into Tabibito values( 1,'aaa'),
( 2,'aaa'),
( 3,'bbb'),
( 6,'bbb'),
( 8,'aaa'),
(20,'bbb'),
(22,'ccc'),
(23,'ccc'),
(31,'ddd'),
(33,'ddd');
-- OLAPSample16
select min(sortKey) as low,max(sortKey) as high,Val
from (select sortKey,Val,
Row_Number() over(order by sortKey)
-Row_Number() over(partition by Val order by sortKey) as distance
from Tabibito) a
group by Val,distance
order by min(sortKey);
low high Val
--- ---- ---
1 2 aaa
3 6 bbb
8 8 aaa
20 20 bbb
22 23 ccc
31 33 ddd
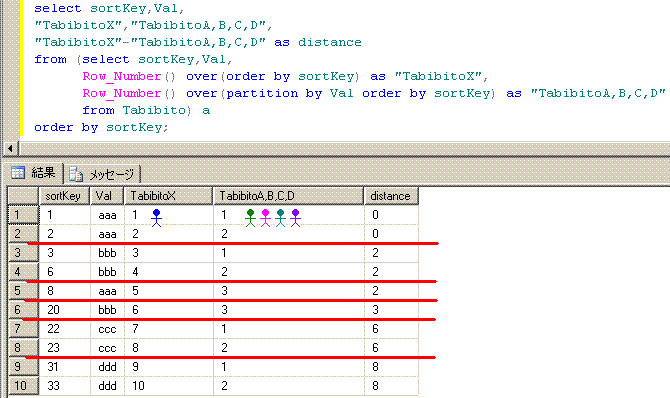
上記のSQLでは、5人の旅人(旅人Xと旅人A,B,C,D)を脳内でイメージしてます。
旅人Xは、必ず1進みます。(Row_Number() over(order by sortKey))
旅人Aは、Val='aaa'の時のみ1進みます。(Row_Number() over(partition by Val order by sortKey))
旅人Bは、Val='bbb'の時のみ1進みます。(Row_Number() over(partition by Val order by sortKey))
旅人Cは、Val='ccc'の時のみ1進みます。(Row_Number() over(partition by Val order by sortKey))
旅人Dは、Val='ddd'の時のみ1進みます。(Row_Number() over(partition by Val order by sortKey))
そして、旅人の種類と、旅人Xとの距離でグループ化してます。 (group by Val,distance)
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
旅人算の感覚を使うSQLの脳内のイメージは、こうなります。
 Row_Number() over(order by sortKey)に対応する1人の旅人と、
Row_Number() over(partition by Val order by sortKey)に対応する4人の旅人をイメージし、
group by Val,distanceに対応する赤線を引いてます。
Row_Number() over(order by sortKey)に対応する1人の旅人と、
Row_Number() over(partition by Val order by sortKey)に対応する4人の旅人をイメージし、
group by Val,distanceに対応する赤線を引いてます。
11. update文で分析関数の値に更新
分析関数を使ったselect文を扱ってきましたが、分析関数を使ったupdate文を扱ってみます。
create table updTes(
ID int not null,
Val int not null,
seq int,
primary key(ID,Val));
insert into updTes values(1, 1,null),
(1, 2,null),
(1, 4,null),
(1, 8,null),
(2, 16,null),
(2, 32,null),
(2, 64,null),
(2, 128,null),
(3, 1,null),
(3, 20,null),
(3, 30,null),
(4, 100,null),
(4, 123,null),
(4, 150,null);
-- OLAPSample17
update updTes
set seq = b.rn
from (select ID,Val,
Row_Number() over(partition by ID order by Val) as rn
from updtes) b
where updTes.ID=b.ID
and updTes.Val=b.Val;
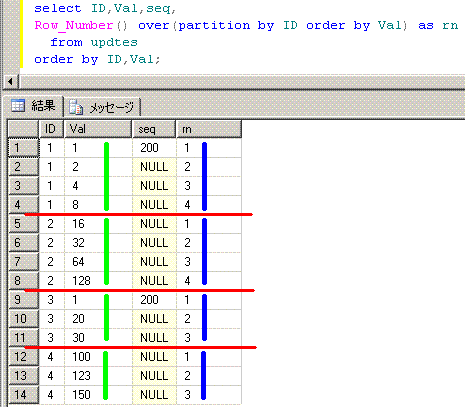
インラインビューでRow_Number関数を使って更新値を求め、IDとValをキーとして内部結合させてます。
MSDNライブラリ --- UPDATE (Transact-SQL)
-- OLAPSample17の相関サブクエリを使った代替方法
update updtes
set seq = (select count(*)+1
from updtes b
where b.ID = updtes.ID
and b.Val < updtes.Val);
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。
partition byで脳内で赤線を引いて、Row_Number関数で青線と黄緑線をイメージしてます。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
MSDNライブラリ --- TOP (Transact-SQL)
SQLServer2008のupdate文では、Top句の指定は可能で、Order by句の指定は不可です。
分析関数を使ったupdate文で、先頭2件だけをupdateしてみます。
-- OLAPSample18
update updTes
set seq = 200
from (select ID,Val,
Row_Number() over(order by Val) as rn
from updtes) b
where updTes.ID=b.ID
and updTes.Val=b.Val
and b.rn <= 2;
-- OLAPSample18の相関サブクエリを使った代替方法1
update updtes
set seq = 200
where exists(select 1
from (select top (2) ID,Val
from updtes
order by Val) b
where updTes.ID=b.ID
and updTes.Val=b.Val);
-- OLAPSample18の相関サブクエリを使った代替方法2
update updtes
set seq = 200
from (select top (2) ID,Val
from updtes
order by Val) b
where updTes.ID=b.ID
and updTes.Val=b.Val;
ちなみに、下記のマルチカラムin述語は、SQLServer2008では文法エラーになります。
-- マルチカラムin述語
update updtes
set seq = 200
where (ID,Val) in (select top (2) ID,Val
from updtes
order by Val)
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
MSDNライブラリ --- TOP (Transact-SQL)
SQLServer2008のupdate文では、Top句の指定は可能で、Order by句の指定は不可です。
分析関数を使ったupdate文で、先頭2件だけをupdateしてみます。
-- OLAPSample18
update updTes
set seq = 200
from (select ID,Val,
Row_Number() over(order by Val) as rn
from updtes) b
where updTes.ID=b.ID
and updTes.Val=b.Val
and b.rn <= 2;
-- OLAPSample18の相関サブクエリを使った代替方法1
update updtes
set seq = 200
where exists(select 1
from (select top (2) ID,Val
from updtes
order by Val) b
where updTes.ID=b.ID
and updTes.Val=b.Val);
-- OLAPSample18の相関サブクエリを使った代替方法2
update updtes
set seq = 200
from (select top (2) ID,Val
from updtes
order by Val) b
where updTes.ID=b.ID
and updTes.Val=b.Val;
ちなみに、下記のマルチカラムin述語は、SQLServer2008では文法エラーになります。
-- マルチカラムin述語
update updtes
set seq = 200
where (ID,Val) in (select top (2) ID,Val
from updtes
order by Val)
with句で分析関数を使った更新可能なビュー(UpdatableView)を使うupdate文を使ってもいいでしょう。
create table updT(ID int,Val int,seq int);
insert into updT values(1, 5,null),
(1,12,null),
(1,55,null),
(2,20,null),
(2,43,null),
(2,85,null);
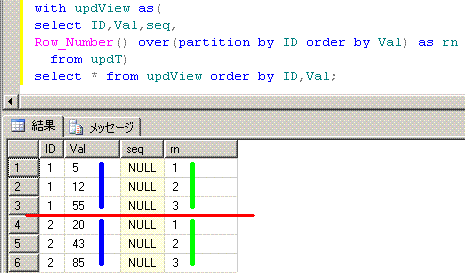
seqをIDごとのValの昇順な連番にupdateしてみます。
-- 更新可能なビュー(UpdatableView)を使うupdate文
with updView as(
select seq,
Row_Number() over(partition by ID order by Val) as rn
from updT)
update updView set seq=rn;
更新結果
ID Val seq
-- --- ---
1 5 1
1 12 2
1 55 3
2 20 1
2 43 2
2 85 3
脳内のイメージは、下記となります。partition by IDに対応する赤線を引いてから、
Row_Number関数で付与する連番に対応する青線と黄緑線を引いてます。
 UPDATE TABLE using ROW_NUMBER() OVER...
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
ちなみに、with句で分析関数を使った削除可能なビュー(DeletableView)を使うdelete文というのもあります。
create table dupT(Val1 int,Val2 int);
insert into dupT values(1, 5),
(1,10),
(1,10),
(2,20),
(2,20),
(3,30),
(3,40);
delete文で重複行を1行にしてみます。
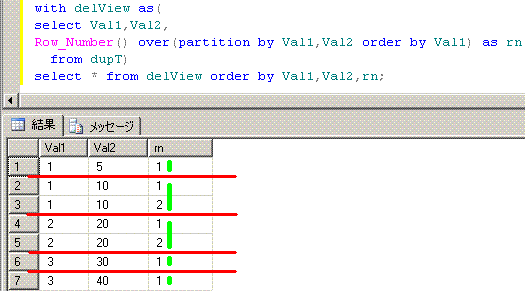
-- 削除可能なビュー(DeletableView)を使うdelete文
with delView as(
select Row_Number() over(partition by Val1,Val2 order by Val1) as rn
from dupT)
delete from delView where rn > 1;
削除結果
Val1 Val2
---- ----
1 5
1 10
2 20
3 30
3 40
脳内のイメージは、下記となります。partition by Val1,Val2に対応する赤線を引いてから、
Row_Number関数で付与する連番に対応する黄緑線を引いてます。
UPDATE TABLE using ROW_NUMBER() OVER...
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
ちなみに、with句で分析関数を使った削除可能なビュー(DeletableView)を使うdelete文というのもあります。
create table dupT(Val1 int,Val2 int);
insert into dupT values(1, 5),
(1,10),
(1,10),
(2,20),
(2,20),
(3,30),
(3,40);
delete文で重複行を1行にしてみます。
-- 削除可能なビュー(DeletableView)を使うdelete文
with delView as(
select Row_Number() over(partition by Val1,Val2 order by Val1) as rn
from dupT)
delete from delView where rn > 1;
削除結果
Val1 Val2
---- ----
1 5
1 10
2 20
3 30
3 40
脳内のイメージは、下記となります。partition by Val1,Val2に対応する赤線を引いてから、
Row_Number関数で付与する連番に対応する黄緑線を引いてます。
 Forum FAQ: How do I remove duplicate rows from a table in SQL Server?
Forum FAQ: How do I remove duplicate rows from a table in SQL Server?
第2部 Oracle11gR2の分析関数をSQLServer2008で模倣
12. order byを指定したsum関数
create table ValT(ID char(2),sortKey int,Val int);
insert into ValT values('AA',1,10);
insert into ValT values('AA',5,20);
insert into ValT values('AA',7,40);
insert into ValT values('AA',9,80);
insert into ValT values('BB',1,10);
insert into ValT values('BB',2,30);
insert into ValT values('BB',6,90);
insert into ValT values('CC',1,30);
insert into ValT values('CC',2,70);
insert into ValT values('CC',9,60);
Oracleでは、分析関数でorder byを指定して累計を取得することができます。
-- 模倣対象のOracleのSQL
select ID,sortKey,Val,
sum(Val) over(partition by ID order by sortKey) as runSum
from ValT
order by ID,sortKey;
ID sortKey Val runSum
-- ------- --- ------
AA 1 10 10
AA 5 20 30
AA 7 40 70
AA 9 80 150
BB 1 10 10
BB 2 30 40
BB 6 90 130
CC 1 30 30
CC 2 70 100
CC 9 60 160
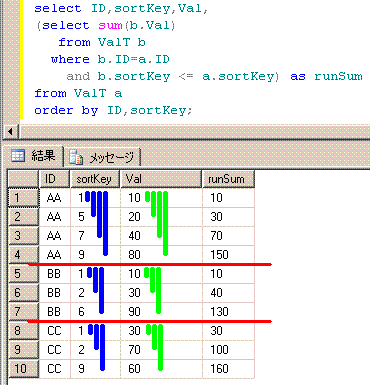
SQLServer2008では、相関サブクエリや再帰SQLを使う方法が、代用案となります。
-- 相関サブクエリを使う方法
select ID,sortKey,Val,
(select sum(b.Val)
from ValT b
where b.ID=a.ID
and b.sortKey <= a.sortKey) as runSum
from ValT a
order by ID,sortKey;
-- 再帰SQLを使う方法
with tmp(ID,sortKey,Val,rn) as(
select ID,sortKey,Val,
Row_Number() over(partition by ID order by sortKey)
from ValT),
rec(ID,sortKey,Val,rn,runSum) as(
select ID,sortKey,Val,rn,Val
from tmp
where rn=1
union all
select a.ID,b.sortKey,b.Val,b.rn,a.runSum+b.Val
from rec a,tmp b
where a.ID=b.ID
and a.rn+1=b.rn)
select * from rec
order by ID,sortKey;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。
13. Rowsを指定したsum関数
create table Rows2Preceding(
ID integer,
sortKey integer,
Val integer);
insert into Rows2Preceding values(1,1, 10);
insert into Rows2Preceding values(1,2, 60);
insert into Rows2Preceding values(1,3, 90);
insert into Rows2Preceding values(1,4,600);
insert into Rows2Preceding values(1,7,300);
insert into Rows2Preceding values(1,8,100);
insert into Rows2Preceding values(2,3, 40);
insert into Rows2Preceding values(2,4, 50);
insert into Rows2Preceding values(2,6,600);
insert into Rows2Preceding values(2,8,200);
Oracleでは、分析関数でorder byを指定して、かつrowsを指定し、
移動累計を取得することができます。
-- 模倣対象のOracleのSQL
select ID,sortKey,Val,
sum(Val) over(partition by ID order by sortKey Rows 2 Preceding) as moveSum
from Rows2Preceding
order by ID,sortKey;
ID sortKey Val moveSum
-- ------- --- -------
1 1 10 10
1 2 60 70
1 3 90 160
1 4 600 750
1 7 300 990
1 8 100 1000
2 3 40 40
2 4 50 90
2 6 600 690
2 8 200 850
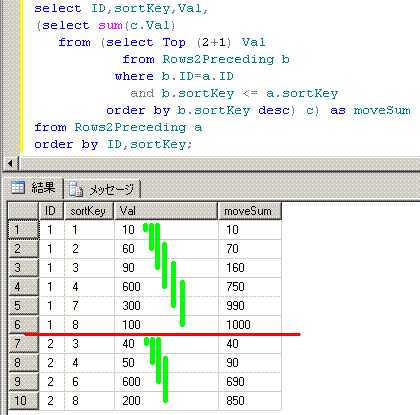
SQLServer2008では、相関サブクエリを使う方法が、代用案となります。
-- 相関サブクエリを使う方法1
select ID,sortKey,Val,
(select sum(c.Val)
from (select Top (2+1) Val
from Rows2Preceding b
where b.ID=a.ID
and b.sortKey <= a.sortKey
order by b.sortKey desc) c) as moveSum
from Rows2Preceding a
order by ID,sortKey;
-- 相関サブクエリを使う方法2
select ID,sortKey,Val,
(select sum(b.Val)
from Rows2Preceding b
where b.ID=a.ID
and (select count(*) from Rows2Preceding c
where c.ID=a.ID
and c.sortKey between b.sortKey and a.sortKey)
between 1 and 2+1) as moveSum
from Rows2Preceding a
order by ID,sortKey;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。
14. Rangeを指定したsum関数
create table Range2Preceding(
ID int,
sortKey int,
Val int);
insert into Range2Preceding values(1,1,10);
insert into Range2Preceding values(1,2,50);
insert into Range2Preceding values(1,2,60);
insert into Range2Preceding values(1,3,70);
insert into Range2Preceding values(1,4,80);
insert into Range2Preceding values(1,5,20);
insert into Range2Preceding values(2,1, 0);
insert into Range2Preceding values(2,1,50);
insert into Range2Preceding values(2,4,30);
insert into Range2Preceding values(2,4,90);
insert into Range2Preceding values(2,8,20);
Oracleでは、分析関数でorder byを指定して、かつrangeを指定し、
移動累計やcountを取得することができます。
-- 模倣対象のOracleのSQL
select ID,sortKey,Val,
sum(Val) over(partition by ID order by sortKey range 2 Preceding) as moveSum,
count(Val) over(partition by ID order by sortKey range 2 Preceding) as moveCnt
from Range2Preceding
order by ID,sortKey;
ID sortKey Val moveSum moveCnt
-- ------- --- ------- ------
1 1 10 10 1
1 2 50 120 3
1 2 60 120 3
1 3 70 190 4
1 4 80 260 4
1 5 20 170 3
2 1 0 50 2
2 1 50 50 2
2 4 30 120 2
2 4 90 120 2
2 8 20 20 1
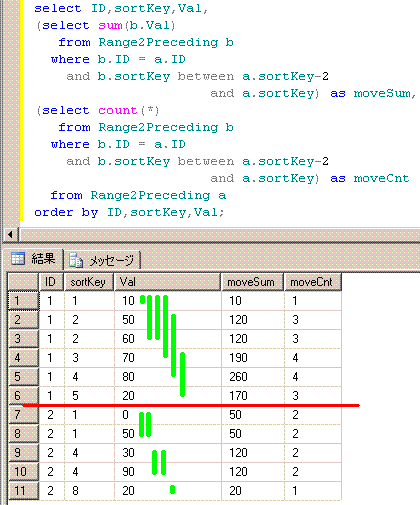
SQLServer2008では、相関サブクエリや自己結合を使う方法が、代用案となります。
-- 相関サブクエリを使う方法
select ID,sortKey,Val,
(select sum(b.Val)
from Range2Preceding b
where b.ID = a.ID
and b.sortKey between a.sortKey-2
and a.sortKey) as moveSum,
(select count(*)
from Range2Preceding b
where b.ID = a.ID
and b.sortKey between a.sortKey-2
and a.sortKey) as moveCnt
from Range2Preceding a
order by ID,sortKey,Val;
-- 自己結合を使う方法
select a.ID,a.sortKey,a.Val,sum(b.Val) as moveSum,count(*) as moveCnt
from Range2Preceding a Join Range2Preceding b
on a.ID=b.ID
and b.sortKey between a.sortKey-2
and a.sortKey
group by a.ID,a.sortKey,a.Val
order by a.ID,a.sortKey,a.Val;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。
15. First_Value関数,Last_Value関数,nth_Value関数
create table nthT(ID int,SortKey int,Val int);
insert into nthT values(1,10,666);
insert into nthT values(1,30,333);
insert into nthT values(1,40,222);
insert into nthT values(1,50,444);
insert into nthT values(2,20,777);
insert into nthT values(2,25,111);
insert into nthT values(2,27,555);
insert into nthT values(3,60,999);
insert into nthT values(3,61,888);
Oracleでは、
指定したソートキーでの、最初の行の値を求める、First_Value
指定したソートキーでの、最後の行の値を求める、Last_Value
指定したソートキーでの、(Row_Numberな順位が)n番目の行の値を求める、nth_Value
といった分析関数が使えます。
-- 模倣対象のOracleのSQL
select ID,SortKey,Val,
First_Value(Val) over(partition by ID order by SortKey) as FirVal,
Last_Value(Val) over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as LastVal,
nth_Value(Val,2) over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as SecondVal,
nth_Value(Val,3) over(partition by ID order by SortKey
Rows between Unbounded Preceding
and Unbounded Following) as thirdVal
from nthT
order by ID,SortKey;
ID SortKey Val FirVal LastVal SecondVal thirdVal
-- ------- --- ------ ------- --------- --------
1 10 666 666 444 333 222
1 30 333 666 444 333 222
1 40 222 666 444 333 222
1 50 444 666 444 333 222
2 20 777 777 555 111 555
2 25 111 777 555 111 555
2 27 555 777 555 111 555
3 60 999 999 888 888 null
3 61 888 999 888 888 null
SQLServer2008では、インラインビューでRow_Number関数を使ってから、
単純case式と分析関数のmax関数の組み合わせる方法が、代用案となります。
-- OLAPSample19
select ID,SortKey,Val,
max(case rn when 1 then Val end) over(partition by ID) as FirVal,
max(case RevRn when 1 then Val end) over(partition by ID) as LastVal,
max(case rn when 2 then Val end) over(partition by ID) as SecondVal,
max(case rn when 3 then Val end) over(partition by ID) as thirdVal
from (select ID,SortKey,Val,
Row_Number() over(partition by ID order by SortKey) as rn,
Row_Number() over(partition by ID order by SortKey desc) as RevRn
from nthT) a
order by ID,SortKey;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。
partition byで脳内で赤線を引いて、Row_Number関数を黄緑線でイメージしてます。
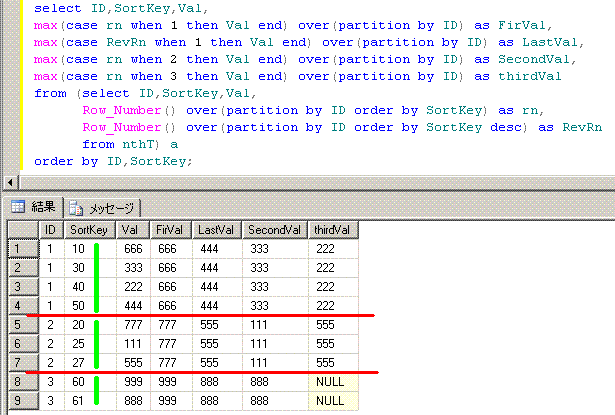 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
なお、First_ValueとLast_Valueは、下記のような相関サブクエリで代用できます。
-- OLAPSample19の相関サブクエリを使った代替方法
select ID,SortKey,Val,
(select top(1) b.Val
from nthT b
where b.ID = a.ID
order by SortKey) as FirVal,
(select top(1) b.Val
from nthT b
where b.ID = a.ID
order by SortKey desc) as LastVal
from nthT a
order by ID,SortKey;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
なお、First_ValueとLast_Valueは、下記のような相関サブクエリで代用できます。
-- OLAPSample19の相関サブクエリを使った代替方法
select ID,SortKey,Val,
(select top(1) b.Val
from nthT b
where b.ID = a.ID
order by SortKey) as FirVal,
(select top(1) b.Val
from nthT b
where b.ID = a.ID
order by SortKey desc) as LastVal
from nthT a
order by ID,SortKey;
16. Lag関数,Lead関数 (1行前と1行後)
create table LeadLagT(ID char(2),sortKey int,Val int);
insert into LeadLagT values('AA',1,10);
insert into LeadLagT values('AA',3,20);
insert into LeadLagT values('AA',5,60);
insert into LeadLagT values('AA',7,30);
insert into LeadLagT values('BB',2,40);
insert into LeadLagT values('BB',4,80);
insert into LeadLagT values('BB',6,50);
insert into LeadLagT values('CC',9,90);
Oracleでは、
指定したソートキーでの、
前の行の値が欲しい時にLag関数が使えて、
後の行の値が欲しい時にLead関数が使えます。
-- 模倣対象のOracleのSQL
select ID,sortKey,Val,
Lag(Val) over(partition by ID order by sortKey) as Prev,
Lead(Val) over(partition by ID order by sortKey) as Next
from LeadLagT
order by ID,sortKey;
ID sortKey Val Prev Next
-- ------- --- ---- ----
AA 1 10 null 20
AA 3 20 10 60
AA 5 60 20 30
AA 7 30 60 null
BB 2 40 null 80
BB 4 80 40 50
BB 6 50 80 null
CC 9 90 null null
SQLServer2008では、相関サブクエリでTop句を使う方法や
with句でRow_Number関数で連番を付与してから自己結合する方法が、代用案となります。
-- 相関サブクエリでTop句を使う方法
select ID,sortKey,Val,
(select Top (1) b.Val
from LeadLagT b
where b.ID = a.ID
and b.sortKey < a.sortKey
order by b.sortKey desc) as Prev,
(select Top (1) b.Val
from LeadLagT b
where b.ID = a.ID
and b.sortKey > a.sortKey
order by b.sortKey) as Next
from LeadLagT a
order by ID,sortKey;
-- with句でRow_Number関数で連番を付与してから自己結合する方法
with tmp(ID,sortKey,Val,rn) as(
select ID,sortKey,Val,Row_Number() over(partition by ID order by sortKey)
from LeadLagT)
select ID,sortKey,Val,
(select b.Val
from tmp b
where b.ID=a.ID
and b.rn=a.rn-1) as Prev,
(select b.Val
from tmp b
where b.ID=a.ID
and b.rn=a.rn+1) as Next
from tmp a
order by ID,sortKey;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。
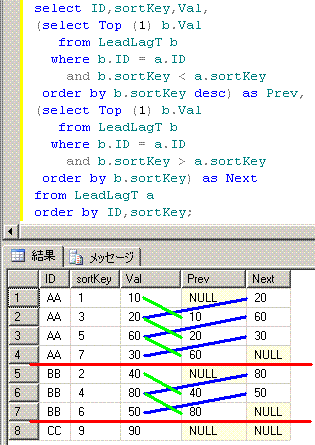
17. Lag関数,Lead関数 (2行前と2行後)
前問を少し変更して、
今度は、IDごとでsortKeyの昇順で2行前のValと2行後のValを求めてみます。
-- 模倣対象のOracleのSQL
select ID,sortKey,Val,
Lag(Val,2) over(partition by ID order by sortKey) as Prev,
Lead(Val,2) over(partition by ID order by sortKey) as Next
from LeadLagT
order by ID,sortKey;
ID sortKey Val Prev Next
-- ------- --- ---- ----
AA 1 10 null 60
AA 3 20 null 30
AA 5 60 10 null
AA 7 30 20 null
BB 2 40 null 50
BB 4 80 null null
BB 6 50 40 null
CC 9 90 null null
前問のように1行前や1行後であれば、相関サブクエリでTop句を使う方法が使えますが、
2行以上前や2行以上後の場合は、with句でRow_Number関数で連番を付与してから自己結合する方法が、代用案となります。
-- with句でRow_Number関数で連番を付与してから自己結合する方法
with tmp(ID,sortKey,Val,rn) as(
select ID,sortKey,Val,Row_Number() over(partition by ID order by sortKey)
from LeadLagT)
select ID,sortKey,Val,
(select b.Val
from tmp b
where b.ID=a.ID
and b.rn=a.rn-2) as Prev,
(select b.Val
from tmp b
where b.ID=a.ID
and b.rn=a.rn+2) as Next
from tmp a
order by ID,sortKey;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。
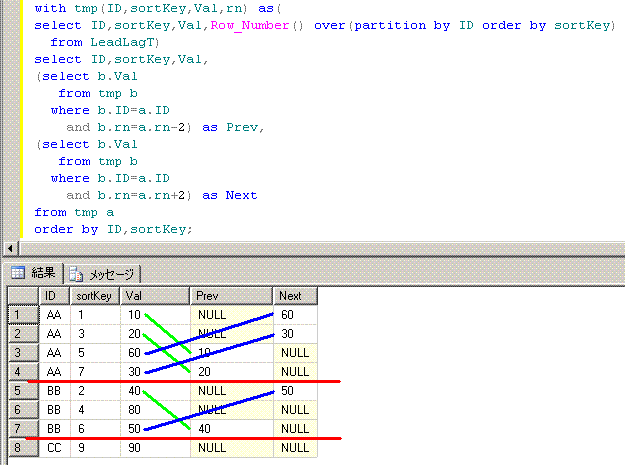
18. 直近との差が10以上なグループでまとめる
create table streamT(ID char(2),Val int);
insert into streamT values('AA',10);
insert into streamT values('AA',13);
insert into streamT values('AA',16);
insert into streamT values('AA',26);
insert into streamT values('AA',27);
insert into streamT values('AA',28);
insert into streamT values('AA',29);
insert into streamT values('AA',40);
insert into streamT values('AA',60);
insert into streamT values('BB',10);
insert into streamT values('BB',15);
insert into streamT values('BB',20);
insert into streamT values('BB',30);
insert into streamT values('BB',35);
9. 連続範囲の最小値と最大値 (2人旅人算)や10.連続範囲の最小値と最大値 (3人旅人算)の類似問題で、
旅人算の感覚が使えないケースを解いてみます。
IDごとで、直近のValとの差が10以上なら別グループ扱いとして
開始と終了と件数をまとめてみます。
-- 模倣対象のOracleのSQL
select ID,min(Val) as staV,max(Val) as endV,count(*) as cnt
from (select ID,Val,sum(willSum) over(partition by ID order by Val) as GID
from (select ID,Val,
case when Val < 10+Lag(Val) over(partition by ID order by Val)
then 0 else 1 end as willSum
from streamT))
group by ID,GID
order by ID,GID;
ID staV endV cnt
-- ---- ---- ---
AA 10 16 3
AA 26 29 4
AA 40 40 1
AA 60 60 1
BB 10 20 3
BB 30 35 2
SQLServer2008では、再帰SQLを使う方法が、代用案となります。
with tmp(ID,Val,rn) as(
select ID,Val,Row_Number() over(partition by ID order by Val)
from streamT),
rec(ID,Val,rn,GID) as(
select ID,Val,rn,1
from tmp where rn=1
union all
select b.ID,b.Val,b.rn,
case when b.Val < 10+a.Val
then a.GID else a.GID+1 end
from rec a,tmp b
where a.ID=b.ID
and a.rn+1=b.rn)
select ID,min(Val) as staV,max(Val) as endV,count(*) as cnt
from rec
group by ID,GID
order by ID,GID;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージ(第1段階)は、下のようになります。
Row_Number() over(partition by ID order by Val)のpartition by IDに対する赤線と
order by Valに対する青線と黄緑線を引いて、
再帰with句の木をイメージしてます。
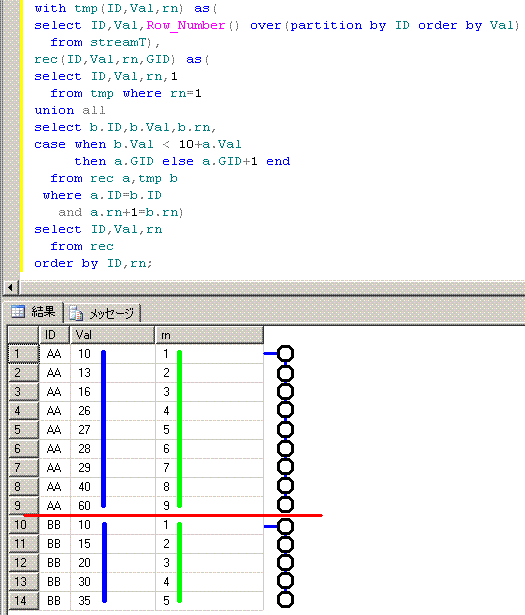 脳内のイメージ(最終段階)は、下のようになります。
group by ID,GIDに対する赤線を引いてます。
脳内のイメージ(最終段階)は、下のようになります。
group by ID,GIDに対する赤線を引いてます。
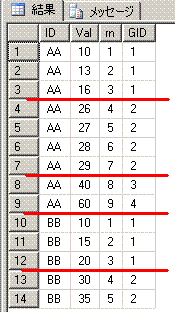
19. count(distinct Val) over(partition by ID)
create table OracleDistinct(
ID int,
Val int not null);
insert into OracleDistinct values(1,111);
insert into OracleDistinct values(1,111);
insert into OracleDistinct values(1,222);
insert into OracleDistinct values(1,222);
insert into OracleDistinct values(1,333);
insert into OracleDistinct values(2,111);
insert into OracleDistinct values(2,111);
insert into OracleDistinct values(3,111);
insert into OracleDistinct values(3,222);
insert into OracleDistinct values(4,333);
Oracleでは、分析関数のcount関数でdistinctオプションが使えます。
SQLServer2008で、下記のOracleのSQLと同じ結果を取得してみます。
-- 模倣対象のOracleのSQL
select ID,Val,count(distinct Val) over(partition by ID) as disCnt
from OracleDistinct;
ID Val disCnt
-- --- ------
1 111 3
1 111 3
1 222 3
1 222 3
1 333 3
2 111 1
2 111 1
3 111 2
3 222 2
4 333 1
-- OLAPSample20
select ID,Val,
-1+dense_rank() over(partition by ID order by Val asc )
+dense_rank() over(partition by ID order by Val desc) as disCnt
from OracleDistinct
order by ID,Val;
-- OLAPSample20の相関サブクエリを使った代替方法
select ID,Val,
(select count(distinct b.Val)
from OracleDistinct b where b.ID = a.ID) as disCnt
from OracleDistinct a
order by ID,Val;
正順位 + 逆順位 = 件数 + 1 を移項すると
件数 = -1 + 正順位 + 逆順位 になることをふまえてます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。partition by IDで赤線を引いてます。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
下記のようにdense_rank関数の結果の最大値を取得してもいいです。
-- OLAPSample21
select ID,Val,max(rn) over(partition by ID) as disCnt
from (select ID,Val,dense_rank() over(partition by ID order by Val) as rn
from OracleDistinct) a
order by ID,Val;
ちなみに、count(distinct Val) は、Valがnullだとカウントしませんので、
Valがnullの場合も考慮するなら、下記のように存在肯定命題を使う必要があります。
-- OLAPSample21
select ID,Val,
-1+dense_rank() over(partition by ID order by Val asc )
+dense_rank() over(partition by ID order by Val desc)
-max(case when Val is null then 1 else 0 end) over(partition by ID) as disCnt
from OracleDistinct
order by ID,Val;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
下記のようにdense_rank関数の結果の最大値を取得してもいいです。
-- OLAPSample21
select ID,Val,max(rn) over(partition by ID) as disCnt
from (select ID,Val,dense_rank() over(partition by ID order by Val) as rn
from OracleDistinct) a
order by ID,Val;
ちなみに、count(distinct Val) は、Valがnullだとカウントしませんので、
Valがnullの場合も考慮するなら、下記のように存在肯定命題を使う必要があります。
-- OLAPSample21
select ID,Val,
-1+dense_rank() over(partition by ID order by Val asc )
+dense_rank() over(partition by ID order by Val desc)
-max(case when Val is null then 1 else 0 end) over(partition by ID) as disCnt
from OracleDistinct
order by ID,Val;
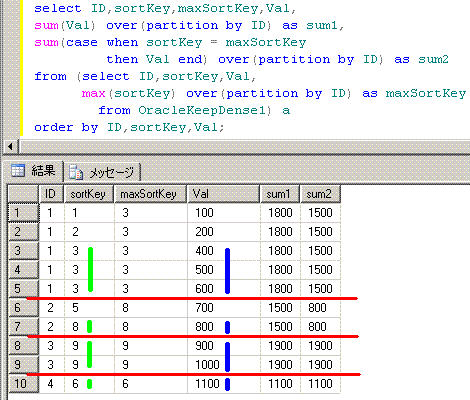
20. sum(Val) Keep(Dense_Rank Last order by sortKey) over(partition by ID)
Oracleでは、集合関数や分析関数の、count関数やmax関数やsum関数などで、Keepが使えます。
SQLServer2008で、同じ結果を取得してみます。
create table OracleKeepDense1(
ID int,
sortKey int,
Val int);
insert into OracleKeepDense1 values(1,1, 100);
insert into OracleKeepDense1 values(1,2, 200);
insert into OracleKeepDense1 values(1,3, 400);
insert into OracleKeepDense1 values(1,3, 500);
insert into OracleKeepDense1 values(1,3, 600);
insert into OracleKeepDense1 values(2,5, 700);
insert into OracleKeepDense1 values(2,8, 800);
insert into OracleKeepDense1 values(3,9, 900);
insert into OracleKeepDense1 values(3,9,1000);
insert into OracleKeepDense1 values(4,6,1100);
-- 模倣対象のOracleのSQL
select ID,sortKey,Val,
sum(Val) over(partition by ID) as sum1,
sum(Val) Keep(Dense_Rank Last order by sortKey) over(partition by ID) as sum2
from OracleKeepDense1
order by ID,sortKey,Val;
ID sortKey Val sum1 sum2
-- ------- ---- ---- ----
1 1 100 1800 1500 ←400+500+600
1 2 200 1800 1500
1 3 400 1800 1500
1 3 500 1800 1500
1 3 600 1800 1500
2 5 700 1500 800
2 8 800 1500 800
3 9 900 1900 1900 ←900+1000
3 9 1000 1900 1900
4 6 1100 1100 1100
-- OLAPSample22
select ID,sortKey,Val,
sum(Val) over(partition by ID) as sum1,
sum(case when sortKey = maxSortKey
then Val end) over(partition by ID) as sum2
from (select ID,sortKey,Val,
max(sortKey) over(partition by ID) as maxSortKey
from OracleKeepDense1) a
order by ID,sortKey,Val;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。partition by IDに対応する赤線を引いてます。
 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
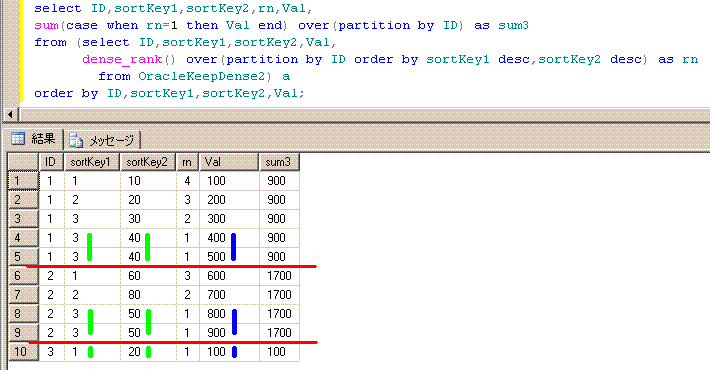
ソートキーが複数だったらdense_rank関数を使う必要があります。
create table OracleKeepDense2(
ID int,
sortKey1 int,
sortKey2 int,
Val int);
insert into OracleKeepDense2 values(1,1,10,100);
insert into OracleKeepDense2 values(1,2,20,200);
insert into OracleKeepDense2 values(1,3,30,300);
insert into OracleKeepDense2 values(1,3,40,400);
insert into OracleKeepDense2 values(1,3,40,500);
insert into OracleKeepDense2 values(2,1,60,600);
insert into OracleKeepDense2 values(2,2,80,700);
insert into OracleKeepDense2 values(2,3,50,800);
insert into OracleKeepDense2 values(2,3,50,900);
insert into OracleKeepDense2 values(3,1,20,100);
-- 模倣対象のOracleのSQL
select ID,sortKey1,sortKey2,Val,
sum(Val) Keep(Dense_Rank Last order by sortKey1,sortKey2) over(partition by ID) as sum3
from OracleKeepDense2
order by ID,sortKey1,sortKey2,Val;
ID sortKey1 sortKey2 Val sum3
-- -------- -------- --- ----
1 1 10 100 900 ←400+500
1 2 20 200 900
1 3 30 300 900
1 3 40 400 900
1 3 40 500 900
2 1 60 600 1700 ←800+900
2 2 80 700 1700
2 3 50 800 1700
2 3 50 900 1700
3 1 20 100 100
-- OLAPSample23
select ID,sortKey1,sortKey2,Val,
sum(case when rn=1 then Val end) over(partition by ID) as sum3
from (select ID,sortKey1,sortKey2,Val,
dense_rank() over(partition by ID order by sortKey1 desc,sortKey2 desc) as rn
from OracleKeepDense2) a
order by ID,sortKey1,sortKey2,Val;
order by sortKey1 asc ,sortKey2 asc の逆ソートである
order by sortKey1 desc,sortKey2 desc を使ってます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。partition by IDに対応する赤線を引いてます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
ソートキーが複数だったらdense_rank関数を使う必要があります。
create table OracleKeepDense2(
ID int,
sortKey1 int,
sortKey2 int,
Val int);
insert into OracleKeepDense2 values(1,1,10,100);
insert into OracleKeepDense2 values(1,2,20,200);
insert into OracleKeepDense2 values(1,3,30,300);
insert into OracleKeepDense2 values(1,3,40,400);
insert into OracleKeepDense2 values(1,3,40,500);
insert into OracleKeepDense2 values(2,1,60,600);
insert into OracleKeepDense2 values(2,2,80,700);
insert into OracleKeepDense2 values(2,3,50,800);
insert into OracleKeepDense2 values(2,3,50,900);
insert into OracleKeepDense2 values(3,1,20,100);
-- 模倣対象のOracleのSQL
select ID,sortKey1,sortKey2,Val,
sum(Val) Keep(Dense_Rank Last order by sortKey1,sortKey2) over(partition by ID) as sum3
from OracleKeepDense2
order by ID,sortKey1,sortKey2,Val;
ID sortKey1 sortKey2 Val sum3
-- -------- -------- --- ----
1 1 10 100 900 ←400+500
1 2 20 200 900
1 3 30 300 900
1 3 40 400 900
1 3 40 500 900
2 1 60 600 1700 ←800+900
2 2 80 700 1700
2 3 50 800 1700
2 3 50 900 1700
3 1 20 100 100
-- OLAPSample23
select ID,sortKey1,sortKey2,Val,
sum(case when rn=1 then Val end) over(partition by ID) as sum3
from (select ID,sortKey1,sortKey2,Val,
dense_rank() over(partition by ID order by sortKey1 desc,sortKey2 desc) as rn
from OracleKeepDense2) a
order by ID,sortKey1,sortKey2,Val;
order by sortKey1 asc ,sortKey2 asc の逆ソートである
order by sortKey1 desc,sortKey2 desc を使ってます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
脳内のイメージは、このようになります。partition by IDに対応する赤線を引いてます。
21. ListAgg関数とwmsys.wm_concat
create table ListAggT(
ID int,
Val char(3));
insert into ListAggT Values(1,'aaa');
insert into ListAggT Values(1,'bbb');
insert into ListAggT Values(1,'ccc');
insert into ListAggT Values(2,'ddd');
insert into ListAggT Values(2,'eee');
Oracleには、MySQLのgroup_concat関数のような集約関数として、
wmsys.wm_concat関数やListAgg関数があって、分析関数としても使えます。
-- 模倣対象のOracleのSQL(order by指定)
select ID,Val,wmsys.wm_concat(Val) over(order by Val) as strAgg1
from ListAggT;
ID Val strAgg1
-- --- -------------------
1 aaa aaa
1 bbb aaa,bbb
1 ccc aaa,bbb,ccc
2 ddd aaa,bbb,ccc,ddd
2 eee aaa,bbb,ccc,ddd,eee
SQLServer2008では、再帰SQLを使う方法や、
FOR XML PATHを相関サブクエリで使う方法が、代用案となります。
-- 再帰SQLを使う方法
with tmp(ID,Val,rn) as(
select ID,Val,Row_Number() over(order by Val)
from ListAggT),
rec(ID,Val,strAgg1,rn) as(
select ID,Val,cast(Val as varchar(20)),rn
from tmp
where rn=1
union all
select b.ID,b.Val,
cast(a.strAgg1 + ',' + b.Val as varchar(20)),b.Rn
from rec a,tmp b
where b.rn = a.rn+1)
select ID,Val,strAgg1 from rec
order by ID,Val;
-- FOR XML PATHを使う方法
select ID,Val,
(select ',' + b.Val
from ListAggT b
where b.Val <= a.Val
FOR XML PATH('')) as strAgg1
from ListAggT a
order by ID,Val;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
-- 模倣対象のOracleのSQL(partition by指定)
select ID,Val,wmsys.wm_concat(Val) over(partition by ID) as strAgg2
from ListAggT;
ID Val strAgg2
-- --- -----------
1 aaa aaa,bbb,ccc
1 bbb aaa,bbb,ccc
1 ccc aaa,bbb,ccc
2 ddd ddd,eee
2 eee ddd,eee
-- FOR XML PATHを使う方法
select ID,Val,
(select ',' + b.Val
from ListAggT b
where b.ID <= a.ID
FOR XML PATH('')) as strAgg2
from ListAggT a
order by ID,Val;
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
なお、FOR XML PATHを使う方法で、連結する文字列の連結順序を指定したい場合は、
下記のように、order byを指定します。
select ID,
(select ',' + b.Val
from ListAggT b
where b.ID=a.ID
ORDER BY Val desc
FOR XML PATH('')) as strAgg3
from ListAggT a
group by ID
order by ID;
ID strAgg3
-- ------------
1 ,ccc,bbb,aaa
2 ,eee,ddd
22. Median関数
create table MedianT(ID int,Val int);
insert into MedianT values(1, 10);
insert into MedianT values(1, 30);
insert into MedianT values(1,300);
insert into MedianT values(2,100);
insert into MedianT values(2,350);
insert into MedianT values(2,400);
insert into MedianT values(2,900);
insert into MedianT values(2,900);
insert into MedianT values(3,200);
insert into MedianT values(3,800);
Oracleには、メジアンを求める集約関数として、Median関数があって、分析関数としても使えます。
-- 模倣対象のOracleのSQL
select ID,Val,
Median(Val) over(partition by ID) as MedianVal
from MedianT
order by ID,Val;
ID Val MedianVal
-- --- ---------
1 10 30
1 30 30
1 300 30
2 100 400
2 350 400
2 400 400
2 900 400
2 900 400
3 200 500
3 800 500
-- OLAPSample24
select ID,Val,
avg(case when RecCnt%2 = 0 and Rn in(RecCnt/2,RecCnt/2+1)
or RecCnt%2 = 1 and Rn = CeilIng(RecCnt/2.0)
then Val end) over(partition by ID) as MedianVal
from (select ID,Val,
count(*) over(partition by ID) as RecCnt,
Row_Number() over(partition by ID order by Val) as Rn
from MedianT) a
order by ID,Val;
インラインビューで、分析関数のcount関数でレコード数を求めて、Row_Number関数で順位を求めて、
分析関数のavg関数の引数のcase式で、レコード数が偶数か奇数かで場合分けしてます。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
下記の、データ件数が奇数個の場合と、偶数個の場合の
正順位と逆順位の差をふまえた下記のSQLでもメジアンを求めることができます。
データ件数が奇数個の場合
正順位 1 2 3 4 5
逆順位 5 4 3 2 1
差 4 2 0 2 4
偶数個の場合
正順位 1 2 3 4
逆順位 4 3 2 1
差 3 1 1 3
-- OLAPSample25
select ID,Val,
avg(case when Rn-RevRn in(-1,0,1)
then Val end) over(partition by ID) as MedianVal
from (select ID,Val,
Row_Number() over(partition by ID order by Val) as Rn,
Row_Number() over(partition by ID order by Val desc) as RevRn
from MedianT) a
order by ID,Val;
第3部 SQLServer2012のTransact-SQLの新機能
■■■その1 分析関数の追加■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
MSDN --- Lead関数
MSDN --- Lag関数
MSDN --- First_Value関数
MSDN --- Last_Value関数
が新しくサポートされます。
残念ながら、Ignore nullsはサポートされないようです・・・
■■■その2 分析関数でorder byを指定可能に■■■■■■■■■■■■■■■■■■■■■
MSDN --- OVER句
分析関数のsum関数などでのorder by指定がサポートされます。
残念ながら、
RANGE を <unsigned value specification> PRECEDING
または <unsigned value specification> FOLLOWING と共に使用することはできません。
だそうです・・・
■■■その3 関数の追加■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
中央値を求めるのに使えるpercentile_cont関数
Excelにある、月末の日を求めるMSDN --- EoMonth関数
VB6にある、MSDN --- IIF関数やMSDN --- Choose関数などが追加。
■■■その4 OffSetとかFetchのサポート■■■■■■■■■■■■■■■■■■■■■■■■
MSDN --- ORDER BY句
select *
from テーブル名
order by ソートキー
OffSet オフしたい行数
Fetch First 取得したい行数
第4部 分析関数の参考リソース